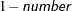The GAMPL Procedure
-
Overview

- Getting Started
-
Syntax
-
DetailsMissing ValuesThin-Plate Regression SplinesGeneralized Additive ModelsModel Evaluation CriteriaFitting AlgorithmsDegrees of FreedomModel InferenceDispersion ParameterTests for Smoothing ComponentsComputational Method: MultithreadingChoosing an Optimization TechniqueDisplayed OutputODS Table NamesODS Graphics
-
Examples
- References
OUTPUT Statement
-
OUTPUT <OUT=SAS-data-set><keyword <=name>>…<keyword <=name>> </ options>;
The OUTPUT statement creates a data set that contains observationwise statistics that are computed after the model is fitted. The variables in the input data set are not included in the output data set in order to avoid data duplication for large data sets; however, variables that are specified in the ID statement are included.
If the input data set is distributed (so that accessing data in a particular order cannot be guaranteed), the GAMPL procedure copies the distribution or partition key to the output data set so that its contents can be joined with the input data.
The computation of the output statistics is based on the final parameter estimates. If the model fit does not converge, missing values are produced for the quantities that depend on the estimates.
You can specify the following syntax elements in the OUTPUT statement before the slash (/).
-
OUT=SAS-data-set
DATA=SAS-data-set -
specifies the name of the output data set. If you omit this option, PROC GAMPL uses the
DATAn convention to name the output data set. - keyword <=name>
-
specifies a statistic to include in the output data set and optionally assigns a name to the variable. If you do not provide a name, the GAMPL procedure assigns a default name based on the keyword.
You can specify the following keywords for adding statistics to the OUTPUT data set:
- LINP | XBETA
-
requests the linear predictor
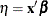 . For observations in which only the response variable is missing, values of the linear predictor are computed even though
these observations do not affect the model fit. The default name is Xbeta.
. For observations in which only the response variable is missing, values of the linear predictor are computed even though
these observations do not affect the model fit. The default name is Xbeta.
- LOWER
-
requests a lower Bayesian confidence band value for the predicted value. The default name is Lower.
- PEARSON | PEARS | RESCHI
-
requests the Pearson residual,
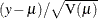 , where
, where 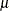 is the estimate of the predicted response mean and
is the estimate of the predicted response mean and 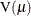 is the response distribution variance function. The default name is Pearson.
is the response distribution variance function. The default name is Pearson.
- PREDICTED | PRED | P
-
requests predicted values for the response variable. For observations in which only the response variable is missing, the predicted values are computed even though these observations do not affect the model fit. The default name is Pred.
- RESIDUAL | RESID | R
-
requests the raw residual,
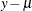 , where is the estimate of the predicted mean. The default name is Residual.
, where is the estimate of the predicted mean. The default name is Residual.
- STD
-
requests a standard error for the linear predictor. The default name is Std.
- UPPER
-
requests an upper Bayesian confidence band value for the predicted value. The default name is Upper.
You can specify the following options in the OUTPUT statement after the slash (/):