The COUNTREG Procedure
- Overview
- Getting Started
-
Syntax
 Functional SummaryPROC COUNTREG StatementBAYES StatementBOUNDS StatementBY StatementCLASS StatementDISPMODEL StatementFREQ StatementINIT StatementMODEL StatementNLOPTIONS StatementOUTPUT StatementPERFORMANCE StatementPRIOR StatementRESTRICT StatementSCORE StatementSHOW StatementSPATIALDISPEFFECTS StatementSPATIALEFFECTS StatementSPATIALID StatementSPATIALZEROEFFECTS StatementSTORE StatementTEST StatementWEIGHT StatementZEROMODEL Statement
Functional SummaryPROC COUNTREG StatementBAYES StatementBOUNDS StatementBY StatementCLASS StatementDISPMODEL StatementFREQ StatementINIT StatementMODEL StatementNLOPTIONS StatementOUTPUT StatementPERFORMANCE StatementPRIOR StatementRESTRICT StatementSCORE StatementSHOW StatementSPATIALDISPEFFECTS StatementSPATIALEFFECTS StatementSPATIALID StatementSPATIALZEROEFFECTS StatementSTORE StatementTEST StatementWEIGHT StatementZEROMODEL Statement -
DetailsSpecification of RegressorsMissing ValuesPoisson RegressionConway-Maxwell-Poisson RegressionNegative Binomial RegressionZero-Inflated Count Regression OverviewZero-Inflated Poisson RegressionZero-Inflated Conway-Maxwell-Poisson RegressionZero-Inflated Negative Binomial RegressionSpatial Lag of X ModelVariable SelectionPanel Data AnalysisBY Groups and Scoring with an Item StoreParameter Naming Conventions for the RESTRICT, TEST, BOUNDS, and INIT StatementsComputational ResourcesNonlinear Optimization OptionsCovariance Matrix TypesDisplayed OutputBayesian AnalysisPrior DistributionsAutomated MCMC AlgorithmMarginal LikelihoodOUTPUT OUT= Data SetOUTEST= Data SetODS Table NamesODS Graphics
-
Examples
- References
Zero-Inflated Count Regression Overview
The main motivation for zero-inflated count models is that real-life data frequently display overdispersion and excess zeros.
Zero-inflated count models provide a way of modeling the excess zeros in addition to allowing for overdispersion. In particular,
for each observation, there are two possible data generation processes. The result of a Bernoulli trial is used to determine
which of the two processes is used. For observation i, Process 1 is chosen with probability 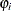 and Process 2 with probability
and Process 2 with probability 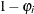 . Process 1 generates only zero counts. Process 2 generates counts from either a Poisson or a negative binomial model. In
general,
. Process 1 generates only zero counts. Process 2 generates counts from either a Poisson or a negative binomial model. In
general,
![\[ y_ i \sim \left\{ \begin{array}{l@{\quad \mbox {with probability} \quad }l} 0 & \varphi _{i} \\ g(y_ i) & 1-\varphi _{i} \end{array} \right. \]](images/etsug_countreg0190.png)
Therefore, the probability of 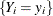 can be described as
can be described as
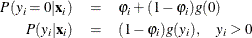
where 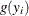 follows either the Poisson or the negative binomial distribution. You can specify the probability
follows either the Poisson or the negative binomial distribution. You can specify the probability 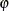 by using the PROBZERO= option in the OUTPUT statement.
by using the PROBZERO= option in the OUTPUT statement.
When the probability depends on the characteristics of observation i, is written as a function of 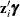 , where
, where 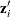 is the
is the 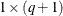 vector of zero-inflation covariates and
vector of zero-inflation covariates and 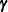 is the
is the  vector of zero-inflation coefficients to be estimated. (The zero-inflation intercept is
vector of zero-inflation coefficients to be estimated. (The zero-inflation intercept is  ; the coefficients for the q zero-inflation covariates are
; the coefficients for the q zero-inflation covariates are 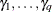 .) The function F that relates the product (which is a scalar) to the probability is called the zero-inflation link function,
.) The function F that relates the product (which is a scalar) to the probability is called the zero-inflation link function,
![\[ \varphi _{i} = F_{i} = F(\mathbf{z}_{i}’\bgamma ) \]](images/etsug_countreg0196.png)
In the COUNTREG procedure, the zero-inflation covariates are indicated in the ZEROMODEL statement. Furthermore, the zero-inflation link function F can be specified as either the logistic function,
![\[ F(\mathbf{z}_{i}’\bgamma ) = \Lambda (\mathbf{z}_{i}’\bgamma ) = \frac{\exp (\mathbf{z}_{i}'\bgamma )}{1+\exp (\mathbf{z}_{i}'\bgamma )} \]](images/etsug_countreg0197.png)
or the standard normal cumulative distribution function (also called the probit function),
![\[ F(\mathbf{z}_{i}’\bgamma ) = \Phi (\mathbf{z}_{i}’\bgamma ) = \int _{0}^{\mathbf{z}_{i}'\bgamma } \frac{1}{\sqrt {2 \pi }}\exp (-u^2 \slash 2) du \]](images/etsug_countreg0198.png)
The zero-inflation link function is indicated in the LINK option in ZEROMODEL statement. The default ZI link function is the logistic function.