The NLIN Procedure
- Overview
-
Getting Started

-
Syntax
-
DetailsAutomatic DerivativesMeasures of Nonlinearity, Diagnostics and InferenceMissing ValuesSpecial VariablesTroubleshootingComputational MethodsOutput Data SetsConfidence IntervalsCovariance Matrix of Parameter EstimatesConvergence MeasuresDisplayed OutputIncompatibilities with SAS 6.11 and Earlier Versions of PROC NLINODS Table NamesODS Graphics
-
Examples
- References
Computational Methods
Nonlinear Least Squares
Recall the basic notation for the nonlinear regression model from the section Notation for Nonlinear Regression Models. The parameter vector 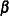 belongs to
belongs to 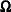 , a subset of
, a subset of 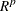 . Two points of this set are of particular interest: the true value
. Two points of this set are of particular interest: the true value 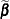 and the least squares estimate
and the least squares estimate 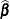 . The general nonlinear model fit with the NLIN procedure is represented by the equation
. The general nonlinear model fit with the NLIN procedure is represented by the equation
![\[ \mb{Y} = \mb{f}(\widetilde{\beta _0}, \widetilde{\beta _1}, \ldots , \widetilde{\beta _ p}; \mb{z}_1,\mb{z}_2,\ldots ,\mb{z}_ k) + \bepsilon = \mb{f}(\widetilde{\bbeta }; \mb{z}_1,\mb{z}_2,\ldots ,\mb{z}_ k) + \bepsilon \]](images/statug_nlin0203.png)
where 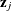 denotes the
denotes the 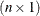 vector of the jth regressor (independent) variable, is the true value of the parameter vector, and
vector of the jth regressor (independent) variable, is the true value of the parameter vector, and  is the vector of homoscedastic and uncorrelated model errors with zero mean.
is the vector of homoscedastic and uncorrelated model errors with zero mean.
To write the model for the ith observation, the ith elements of 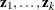 are collected in the row vector
are collected in the row vector 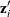 , and the model equation becomes
, and the model equation becomes
![\[ Y_ i = f(\bbeta ; \mb{z}_{i}^\prime ) + \epsilon _ i \]](images/statug_nlin0208.png)
The shorthand 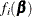 will also be used throughout to denote the mean of the ith observation.
will also be used throughout to denote the mean of the ith observation.
For any given value we can compute the residual sum of squares
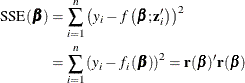
The aim of nonlinear least squares estimation is to find the value that minimizes 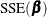 . Because
. Because 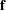 is a nonlinear function of , a closed-form solution does not exist for this minimization problem. An iterative process is used instead. The iterative
techniques that PROC NLIN uses are similar to a series of linear regressions involving the matrix
is a nonlinear function of , a closed-form solution does not exist for this minimization problem. An iterative process is used instead. The iterative
techniques that PROC NLIN uses are similar to a series of linear regressions involving the matrix 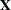 and the residual vector
and the residual vector 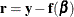 , evaluated at the current values of .
, evaluated at the current values of .
It is more insightful, however, to describe the algorithms in terms of their approach to minimizing the residual sum of squares
and in terms of their updating formulas. If 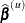 denotes the value of the parameter estimates at the uth iteration, and
denotes the value of the parameter estimates at the uth iteration, and 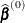 are your starting values, then the NLIN procedure attempts to find values k and
are your starting values, then the NLIN procedure attempts to find values k and 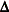 such that
such that
![\[ \widehat{\bbeta }^{(u+1)} = \widehat{\bbeta }^{(u)} + k\bDelta \]](images/statug_nlin0216.png)
and
![\[ \mr{SSE}\left(\widehat{\bbeta }^{(u+1)}\right) < \mr{SSE}\left(\widehat{\bbeta }^{(u)}\right) \]](images/statug_nlin0217.png)
The various methods to fit a nonlinear regression model—which you can select with the METHOD=
option in the PROC NLIN
statement—differ in the calculation of the update vector .
The gradient and Hessian of the residual sum of squares with respect to individual parameters and pairs of parameters are, respectively,
![\begin{align*} \mb{g}(\beta _ j) & = \frac{\partial \mr{SSE}(\bbeta )}{\partial \beta _ j} = -2 \sum _{i=1}^{n} \left(y_ i - f_ i(\bbeta )\right) \frac{\partial f_ i(\bbeta )}{\partial \beta _ j} \\ \left[\mb{H}(\bbeta )\right]_{jk} & = \frac{\partial \mr{SSE}(\bbeta )}{\partial \beta _ j \partial \beta _ k} = 2 \sum _{i=1}^{n} \frac{\partial f_ i(\bbeta )}{\partial \beta _ j} \frac{\partial f_ i(\bbeta )}{\partial \beta _ k} - \left(y_ i - f_ i(\bbeta )\right) \frac{\partial ^2 f_ i(\bbeta )}{\partial \beta _ j\partial \beta _ k} \\ \end{align*}](images/statug_nlin0218.png)
Denote as 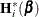 the Hessian matrix of the mean function,
the Hessian matrix of the mean function,
![\[ \left[\mb{H}^*_ i(\bbeta )\right]_{jk} = \left[ \frac{\partial ^2 f_ i(\bbeta )}{\partial \beta _ j\partial \beta _ k} \right]_{jk} \]](images/statug_nlin0220.png)
Collecting the derivatives across all parameters leads to the expressions
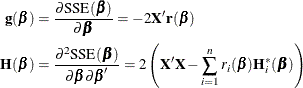
The change in the vector of parameter estimates is computed as follows, depending on the estimation method:
![\begin{align*} \mbox{Gauss-Newton: } \bDelta & = \left(-\mr{E}[\mb{H}(\bbeta )]\right)^{-}\mb{g}(\bbeta ) = (\mb{X}’\mb{X})^{-}\mb{X}’\mb{r} \\[0.15 in] \mbox{Marquardt: } \bDelta & = \left(\mb{X}’\mb{X} + \lambda \mbox{diag}(\mb{X}’\mb{X})\right)^{-}\mb{X}’\mb{r} \\[0.15 in] \mbox{Newton: } \bDelta & = - \mb{H}(\bbeta )^{-}\mb{g}(\bbeta ) = \mb{H}(\bbeta )^- \mb{X}’\mb{r} \\[0.15in] \mbox{Steepest descent: } \bDelta & = -\frac12 \frac{\partial \mr{SSE}(\bbeta )}{\partial \bbeta } = \mb{X}’\mb{r}\\ \end{align*}](images/statug_nlin0222.png)
The Gauss-Newton and Marquardt iterative methods regress the residuals onto the partial derivatives of the model with respect to the parameters until the estimates converge. You can view the Marquardt algorithm as a Gauss-Newton algorithm with a ridging penalty. The Newton iterative method regresses the residuals onto a function of the first and second derivatives of the model with respect to the parameters until the estimates converge. Analytical first- and second-order derivatives are automatically computed as needed.
The default method used to compute 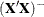 is the sweep (Goodnight 1979). It produces a reflexive generalized inverse (a
is the sweep (Goodnight 1979). It produces a reflexive generalized inverse (a 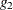 -inverse, Pringle and Rayner 1971).
In some cases it might be preferable to use a Moore-Penrose inverse (a
-inverse, Pringle and Rayner 1971).
In some cases it might be preferable to use a Moore-Penrose inverse (a 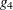 -inverse) instead.
If you specify the G4
option in the PROC NLIN
statement, a -inverse is used to calculate on each iteration.
-inverse) instead.
If you specify the G4
option in the PROC NLIN
statement, a -inverse is used to calculate on each iteration.
The four algorithms are now described in greater detail.
Algorithmic Details
Gauss-Newton and Newton Methods
From the preceding set of equations you can see that the Marquardt method is a ridged version of the Gauss-Newton method.
If the ridge parameter 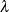 equals zero, the Marquardt step is identical to the Gauss-Newton step. An important difference between the Newton methods
and the Gauss-Newton-type algorithms lies in the use of second derivatives. To motivate this distinctive element between Gauss-Newton
and the Newton method, focus first on the objective function in nonlinear least squares. To numerically find the minimum of
equals zero, the Marquardt step is identical to the Gauss-Newton step. An important difference between the Newton methods
and the Gauss-Newton-type algorithms lies in the use of second derivatives. To motivate this distinctive element between Gauss-Newton
and the Newton method, focus first on the objective function in nonlinear least squares. To numerically find the minimum of
![\[ \mr{SSE}(\bbeta ) = \mb{r}(\bbeta )^\prime \mb{r}(\bbeta ) \]](images/statug_nlin0226.png)
you can approach the problem by approximating the sum of squares criterion by a criterion for which you can compute a closed-form solution. Following Seber and Wild (1989, Sect. 2.1.3), we can achieve that by doing the following:
-
approximating the model and substituting the approximation into
-
approximating
directly
The first method, approximating the nonlinear model with a first-order Taylor series, is the purview of the Gauss-Newton method. Approximating the residual sum of squares directly is the realm of the Newton method.
The first-order Taylor series of the residual 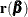 at the point is
at the point is
![\[ \mb{r}(\bbeta ) \approx \mb{r}(\widehat{\bbeta }) - \widehat{\mb{X}} \left(\bbeta - \widehat{\bbeta }\right) \]](images/statug_nlin0228.png)
Substitution into leads to the objective function for the Gauss-Newton step:
![\[ \mr{SSE}\left(\bbeta \right) \approx S_ G(\bbeta ) = \mb{r}(\widehat{\bbeta })^\prime - 2\mb{r}^\prime (\widehat{\bbeta })\widehat{\mb{X}} \left(\bbeta - \widehat{\bbeta }\right) + \left(\bbeta - \widehat{\bbeta }\right)^\prime \left(\widehat{\mb{X}}^\prime \widehat{\mb{X}}\right) \left(\bbeta - \widehat{\bbeta }\right) \]](images/statug_nlin0229.png)
"Hat" notation is used here to indicate that the quantity in question is evaluated at .
To motivate the Newton method, take a second-order Taylor series of around the value :
![\[ \mr{SSE}\left(\bbeta \right) \approx S_ N(\bbeta ) = \mr{SSE}\left(\widehat{\bbeta }\right) + \mb{g}(\widehat{\bbeta })^\prime \left(\bbeta - \widehat{\bbeta }\right) +\frac12 \left(\bbeta - \widehat{\bbeta }\right)^\prime \mb{H}(\widehat{\bbeta }) \left(\bbeta - \widehat{\bbeta }\right) \]](images/statug_nlin0230.png)
Both 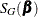 and
and 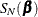 are quadratic functions in and are easily minimized. The minima occur when
are quadratic functions in and are easily minimized. The minima occur when
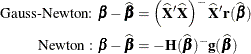
and these terms define the preceding update vectors.
Gauss-Newton Method
Since the Gauss-Newton method is based on an approximation of the model, you can also derive the update vector by first considering the "normal" equations of the nonlinear model
![\[ \mb{X}^\prime \mb{f}(\bbeta ) = \mb{X}^\prime \mb{Y} \]](images/statug_nlin0234.png)
and then substituting the Taylor approximation
![\[ \mb{f}(\bbeta ) \approx \mb{f}(\widehat{\bbeta }) + \mb{X} \left(\bbeta - \widehat{\bbeta }\right) \]](images/statug_nlin0235.png)
for 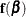 . This leads to
. This leads to
![\begin{align*} \mb{X}^{\prime }\left(\mb{f}(\widehat{\bbeta }) + \mb{X}(\bbeta - \widehat{\bbeta })\right) & = \mb{X}^{\prime }\mb{Y} \\[0.05in] (\mb{X}^{\prime }\mb{X})(\bbeta - \widehat{\bbeta }) & = \mb{X}^{\prime }\mb{Y} - \mb{X}^{\prime }\mb{f}(\widehat{\bbeta }) \\[0.05in] (\mb{X}^{\prime }\mb{X}) \bDelta & = \mb{X}^{\prime }\mb{r}(\widehat{\bbeta }) \\ \end{align*}](images/statug_nlin0237.png)
and the update vector becomes
![\[ \bDelta = \left(\mb{X}^\prime \mb{X}\right)^{-} \mb{X}^{\prime }\mb{r}(\widehat{\bbeta }) \]](images/statug_nlin0238.png)
Note: If 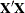 is singular or becomes singular, PROC NLIN computes by using a generalized inverse for the iterations after singularity occurs. If is still singular for the last iteration, the solution should be examined.
is singular or becomes singular, PROC NLIN computes by using a generalized inverse for the iterations after singularity occurs. If is still singular for the last iteration, the solution should be examined.
Newton Method
The Newton method uses the second derivatives and solves the equation
![\[ \bDelta = \mb{H}^{-} \mb{X}^{\prime }\mb{r} \]](images/statug_nlin0240.png)
If the automatic variables _WEIGHT_, _WGTJPJ_, and _RESID_ are used, then
![\[ \bDelta = \mb{H}^{-}\mb{X}^{\prime } \mb{W}^{\mr{SSE}} \mb{r}^* \]](images/statug_nlin0241.png)
is the direction, where
![\[ \mb{H} = \mb{X}^{\prime } \mb{W}^{\mr{XPX}} \mb{X} - \sum _{i=1}^ n \mb{H}^*_ i(\bbeta ) w_ i^{\mr{XPX}} r^*_ i \]](images/statug_nlin0242.png)
and
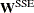
-
is an
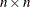 diagonal matrix with elements
diagonal matrix with elements 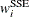 of weights from the
of weights from the _WEIGHT_variable. Each element contains the value of _WEIGHT_for the ith observation. 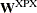
-
is an
diagonal matrix with elements 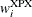 of weights from the
of weights from the _WGTJPJ_variable.Each element
contains the value of _WGTJPJ_for the ith observation. 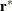
-
is a vector with elements
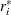 from the
from the _RESID_variable. Each element contains the value of _RESID_evaluated for the ith observation.
Marquardt Method
The updating formula for the Marquardt method is as follows:
![\[ \bDelta = (\mb{X}^{\prime }\mb{X} + \lambda \mbox{diag}(\mb{X}^{\prime }\mb{X}))^{-}\mb{X}^{\prime }\mb{e} \]](images/statug_nlin0250.png)
The Marquardt method is a compromise between the Gauss-Newton and steepest descent methods (Marquardt 1963). As 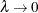 , the direction approaches Gauss-Newton. As
, the direction approaches Gauss-Newton. As 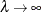 , the direction approaches steepest descent.
, the direction approaches steepest descent.
Marquardt’s studies indicate that the average angle between Gauss-Newton and steepest descent directions is about 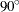 . A choice of between 0 and infinity produces a compromise direction.
. A choice of between 0 and infinity produces a compromise direction.
By default, PROC NLIN chooses 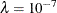 to start and computes . If
to start and computes . If 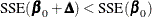 , then
, then 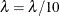 for the next iteration. Each time
for the next iteration. Each time 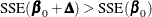 , then
, then 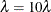 .
.
Note: If the SSE decreases on each iteration, then , and you are essentially using the Gauss-Newton method. If SSE does not improve, then is increased until you are moving in the steepest descent direction.
Marquardt’s method is equivalent to performing a series of ridge regressions, and it is useful when the parameter estimates are highly correlated or the objective function is not well approximated by a quadratic.
Steepest Descent (Gradient) Method
The steepest descent method is based directly on the gradient of 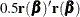 :
:
![\[ \frac{1}{2} \frac{\partial \mr{SSE}(\bbeta )}{\partial \bbeta } = -\mb{X}^{\prime }\mb{r} \]](images/statug_nlin0260.png)
The quantity 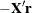 is the gradient along which
is the gradient along which 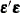 increases. Thus
increases. Thus 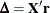 is the direction of steepest descent.
is the direction of steepest descent.
If the automatic variables _WEIGHT_ and _RESID_ are used, then
![\[ \bDelta = \mb{X}^{\prime } \mb{W}^{\mr{SSE}} \mb{r}^* \]](images/statug_nlin0264.png)
is the direction, where
-
is an
diagonal matrix with elements of weights from the _WEIGHT_variable. Each element contains the value of _WEIGHT_for the ith observation. -
is a vector with elements
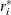 from
from _RESID_. Each element contains the value of _RESID_evaluated for the ith observation.
Using the method of steepest descent, let
![\[ \bbeta ^{(k+1)} = \bbeta ^{(k)} + \alpha \bDelta \]](images/statug_nlin0266.png)
where the scalar  is chosen such that
is chosen such that
![\[ \mbox{SSE}(\bbeta _ i + \alpha \bDelta ) < \mbox{SSE}(\bbeta _ i) \]](images/statug_nlin0267.png)
Note: The steepest-descent method can converge very slowly and is therefore not generally recommended. It is sometimes useful when the initial values are poor.
Step-Size Search
The default method of finding the step size k is step halving by using SMETHOD=
HALVE. If 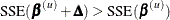 , compute
, compute 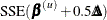 ,
, 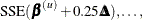 until a smaller SSE is found.
until a smaller SSE is found.
If you specify SMETHOD=
GOLDEN, the step size k is determined by a golden section search. The parameter TAU
determines the length of the initial interval to be searched, with the interval having length TAU
(or 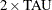 ), depending on
), depending on 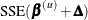 . The RHO
parameter specifies how fine the search is to be. The SSE at each endpoint of the interval is evaluated, and a new subinterval
is chosen. The size of the interval is reduced until its length is less than RHO
. One pass through the data is required each time the interval is reduced. Hence, if RHO
is very small relative to TAU, a large amount of time can be spent determining a step size. For more information about the
golden section search, see Kennedy and Gentle (1980).
. The RHO
parameter specifies how fine the search is to be. The SSE at each endpoint of the interval is evaluated, and a new subinterval
is chosen. The size of the interval is reduced until its length is less than RHO
. One pass through the data is required each time the interval is reduced. Hence, if RHO
is very small relative to TAU, a large amount of time can be spent determining a step size. For more information about the
golden section search, see Kennedy and Gentle (1980).
If you specify SMETHOD= CUBIC, the NLIN procedure performs a cubic interpolation to estimate the step size. If the estimated step size does not result in a decrease in SSE, step halving is used.