The IRT Procedure
-
Overview

- Getting Started
-
Syntax
-
DetailsNotation for the Item Response Theory ModelAssumptionsPROC IRT Contrasted with Other SAS ProceduresResponse ModelsMarginal LikelihoodApproximating the Marginal LikelihoodMaximizing the Marginal LikelihoodFactor Score EstimationModel and Item FitItem and Test informationMissing ValuesOutput Data SetsODS Table NamesODS Graphics
-
Examples
- References
Getting Started: IRT Procedure
This example shows how you can use all default settings in PROC IRT to fit an item response model. In this example, there are 50 subjects and each subject responds to 10 items. These 10 items have binary responses: 1 indicates correct and 0 indicates incorrect.
The following DATA step creates the SAS data set IrtBinary:
data IrtBinary; input item1-item10 @@; datalines; 1 0 1 1 1 1 1 1 1 0 1 1 1 1 1 1 1 1 1 1 0 0 0 0 1 0 1 0 0 1 1 1 1 1 1 0 0 0 0 0 1 1 1 1 1 0 0 0 1 1 1 1 1 1 1 0 0 1 0 1 1 1 1 1 1 1 1 1 1 1 ... more lines ... 1 1 1 1 1 0 1 1 1 1 1 1 1 1 1 1 1 0 1 1 ;
The following statements fit an IRT model:
proc irt data=IrtBinary; var item1-item10; run;
The PROC IRT statement invokes the procedure, and the DATA=
option specifies the input data set IrtBinary. The VAR
statement names the variables to be used in the model. As you can see from the syntax in this example, fitting a IRT model
can be very simple when you use the default settings. These default settings are chosen to reflect setups that are common
in practice. Some of the important default settings follow:
-
The number of factors is 1.
-
The two-parameter logistic model is assumed for binary variables, and the graded response model is assumed for ordinal variables.
-
The link function is logistic link.
-
The estimation method is based on marginal likelihood.
-
The optimization method is the quasi-Newton algorithm.
-
The quadrature method is adaptive Gauss-Hermite quadrature, in which the number of quadrature points per dimension is determined adaptively.
As a result, the preceding statements fit two-parameter logistic (2PL) models for all the variables that are listed in the VAR statement.
The first table that PROC IRT produces is the "Modeling Information" table, as shown in Figure 65.1. This table displays basic information about the analysis, such as the name of the input data set, the link function, the number of items and factors, the number of observations, and the estimation method. You can change the link function by using the LINK= option in the PROC IRT statement. You can change the response model for all the items by using the RESFUNC= option in the PROC IRT statement. You can specify different response functions or models for different set of variables by including a MODEL statement. If you want to do multidimensional exploratory analysis, you can simply change the number of factors by using the NFACTOR= option in the PROC IRT statement. For confirmatory analysis, you can use the FACTOR statement to specify the confirmatory factor pattern; the number of factors is implicitly defined by the number of distinctive factor names that you specify in the FACTOR statement.
Figure 65.1: Model Information
The "Item Information" table, shown in Figure 65.2, is displayed by default and can be used to check the item-level information. In this case, each of the 10 variables has two levels, and the raw values for these two levels are 0 and 1, respectively.
Figure 65.2: Item Information
The eigenvalues of polychoric correlations are also computed by default and are shown in Figure 65.3. You can use the information from these eigenvalues to assess a reasonable range for the number of factors. For this example,
you can observe that the first eigenvalue accounts for almost 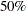 of the variance, which suggests that there is only one dominant eigenvalue and that a unidimensional model is reasonable
for this example. To produce the polychoric correlation table, you specify the POLYCHORIC
option in the PROC IRT
statement.
of the variance, which suggests that there is only one dominant eigenvalue and that a unidimensional model is reasonable
for this example. To produce the polychoric correlation table, you specify the POLYCHORIC
option in the PROC IRT
statement.
Figure 65.3: Eigenvalues of Polychoric Correlation
| Eigenvalues of the Polychoric Correlation Matrix | ||||
|---|---|---|---|---|
| Eigenvalue | Difference | Proportion | Cumulative | |
| 1 | 4.71105177 | 3.51149453 | 0.4711 | 0.4711 |
| 2 | 1.19955723 | 0.14183502 | 0.1200 | 0.5911 |
| 3 | 1.05772221 | 0.26577735 | 0.1058 | 0.6968 |
| 4 | 0.79194486 | 0.07204549 | 0.0792 | 0.7760 |
| 5 | 0.71989938 | 0.17782491 | 0.0720 | 0.8480 |
| 6 | 0.54207446 | 0.12713664 | 0.0542 | 0.9022 |
| 7 | 0.41493782 | 0.10631770 | 0.0415 | 0.9437 |
| 8 | 0.30862012 | 0.12256183 | 0.0309 | 0.9746 |
| 9 | 0.18605829 | 0.11792444 | 0.0186 | 0.9932 |
| 10 | 0.06813385 | 0.0068 | 1.0000 | |
Next, the "Optimization Information" table, shown in Figure 65.4, lists the optimization technique, the numeric quadrature method, and the number of quadrature points per dimension. If you want to use the expectation-maximization (EM) technique, specify TECHNIQUE=EM in the PROC IRT statement. If you specify the NOAD option in the PROC IRT statement, PROC IRT uses the nonadaptive Gauss-Hermite quadrature to approximate the likelihood. You can change the number of quadrature points by specifying the QPOINTS= option in the PROC IRT statement.
Figure 65.4: Optimization Information
Figure 65.5 shows the "Iteration History" table. For each iteration, the table displays the current iteration number, number of function evaluations, objective function value, change of object function value, and maximum value of gradients. You can use this information to monitor the estimation status of the model. You can turn off the display of the "Iteration History" table by specifying the NOITPRINT option in the PROC IRT statement.
Following the "Iteration History" table is the convergence status table, shown in Figure 65.6. It shows whether the optimization algorithm converges successfully or not. You should make sure that the optimization converges successfully before you try to interpret the estimation results.
Figure 65.5: Iteration History
| Iteration History | |||||
|---|---|---|---|---|---|
| Cycles | Iteration | Evaluations | Objective Function |
Function Change |
Max Abs Gradient |
| 0 | 0 | 2 | 5.53317409 | 0.055021 | |
| 0 | 1 | 4 | 5.43362007 | -0.09955401 | 0.017514 |
| 0 | 2 | 6 | 5.41516422 | -0.01845585 | 0.017074 |
| 0 | 3 | 8 | 5.40358645 | -0.01157777 | 0.007847 |
| 0 | 4 | 10 | 5.40166068 | -0.00192577 | 0.00726 |
| 0 | 5 | 12 | 5.40106299 | -0.00059770 | 0.00349 |
| 0 | 6 | 15 | 5.40088871 | -0.00017428 | 0.001478 |
| 0 | 7 | 18 | 5.40082522 | -0.00006349 | 0.000859 |
| 0 | 8 | 21 | 5.40079959 | -0.00002563 | 0.000804 |
| 0 | 9 | 24 | 5.40078941 | -0.00001017 | 0.000441 |
| 0 | 10 | 27 | 5.40078290 | -0.00000652 | 0.00014 |
| 0 | 11 | 30 | 5.40078218 | -0.00000072 | 0.000156 |
| 0 | 12 | 32 | 5.40078188 | -0.00000030 | 0.000202 |
| 0 | 13 | 34 | 5.40078147 | -0.00000042 | 0.000032 |
| 0 | 14 | 37 | 5.40078144 | -0.00000003 | 0.000024 |
| 0 | 15 | 40 | 5.40078142 | -0.00000001 | 9.866E-6 |
| 1 | 0 | 2 | 5.40078179 | 9.953E-6 | |
Next is the "Model Fit Statistics" table, shown in Figure 65.7, which includes the log likelihood, Akaike’s information criterion (AIC), and the Bayesian information criterion (BIC). If all the response patterns are observed, Pearson’s chi-square and likelihood ratio chi-square statistics are also included in this table. Because some of the response patterns in this example are not observed, the Pearson’s chi-square and likelihood ratio chi-square statistics are not included in the table.
Figure 65.7: Fit Statistics
Finally, the "Item Parameter Estimates" table, shown in Figure 65.8, includes parameter estimates, standard errors, and p-values. Parameters are organized and displayed within each item. The items are listed in the order of their appearance in the modeling statements. For each item, there are two parameters: difficulty and slope. Difficulty parameters measure the difficulties of the items. As the value of the difficulty parameter increases, the item becomes more difficult. In Figure 65.8, you can observe that all the difficulty parameters are less than 0, which suggests that all the items in this example are relatively easy. The slope parameter values for this example range from 0.94 to 2.33, suggesting that all the items are adequate measures of the latent trait.
Figure 65.8: Parameter Estimates
| Item Parameter Estimates | ||||
|---|---|---|---|---|
| Item | Parameter | Estimate | Standard Error |
Pr > |t| |
| item1 | Difficulty | -0.86577 | 0.20049 | <.0001 |
| Slope | 2.21983 | 0.68394 | 0.0006 | |
| item2 | Difficulty | -1.01629 | 0.21353 | <.0001 |
| Slope | 2.33878 | 0.76100 | 0.0011 | |
| item3 | Difficulty | -0.91125 | 0.20824 | <.0001 |
| Slope | 2.18658 | 0.68338 | 0.0007 | |
| item4 | Difficulty | -0.92384 | 0.22606 | <.0001 |
| Slope | 1.87303 | 0.57533 | 0.0006 | |
| item5 | Difficulty | -1.09216 | 0.30469 | 0.0002 |
| Slope | 1.33934 | 0.42769 | 0.0009 | |
| item6 | Difficulty | -0.48811 | 0.24191 | 0.0218 |
| Slope | 1.17672 | 0.37110 | 0.0008 | |
| item7 | Difficulty | -0.61766 | 0.29991 | 0.0197 |
| Slope | 0.94547 | 0.32651 | 0.0019 | |
| item8 | Difficulty | -0.50800 | 0.28293 | 0.0363 |
| Slope | 0.95665 | 0.32983 | 0.0019 | |
| item9 | Difficulty | -0.41109 | 0.24309 | 0.0454 |
| Slope | 1.11732 | 0.35666 | 0.0009 | |
| item10 | Difficulty | -0.62318 | 0.27830 | 0.0126 |
| Slope | 1.05213 | 0.34965 | 0.0013 | |