The IRT Procedure
-
Overview

- Getting Started
-
Syntax
-
DetailsNotation for the Item Response Theory ModelAssumptionsPROC IRT Contrasted with Other SAS ProceduresResponse ModelsMarginal LikelihoodApproximating the Marginal LikelihoodMaximizing the Marginal LikelihoodFactor Score EstimationModel and Item FitItem and Test informationMissing ValuesOutput Data SetsODS Table NamesODS Graphics
-
Examples
- References
Model and Item Fit
The IRT procedure includes five model fit statistics: log likelihood, Akaike’s information criterion (AIC), Bayesian information
criterion (BIC), likelihood ratio chi-square 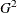 , and Pearson’s chi-square.
, and Pearson’s chi-square.
The following two equations compute the likelihood ratio chi-square and Pearson’s chi-square,
![\[ G^2 = 2\left[\sum _{l=1}^{L} r_ l \log \frac{r_ l}{N P_ l}\right] \]](images/statug_irt0116.png)
![\[ \chi ^2 = \sum _{l=1}^{L} \frac{(r_ l-NP_ l)^2}{N P_ l} \]](images/statug_irt0117.png)
where N is the number of subjects, L is number of possible response patterns, 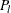 is the estimated probability of observing response pattern l, and
is the estimated probability of observing response pattern l, and 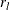 is the number of subjects who have response pattern l. If the model is true, these two statistics asymptotically follow central chi-square distribution with degrees of freedom
is the number of subjects who have response pattern l. If the model is true, these two statistics asymptotically follow central chi-square distribution with degrees of freedom
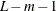 , where m is the number of free parameters in the model. When L (the number of possible response patterns) is much greater than N, the frequency table is sparse. This invalidates the use of chi-square distribution as the asymptotic distribution for these
two statistics, and as a result the likelihood ratio chi-square and Pearson’s chi-square statistics should not be used to
evaluate overall model fit.
, where m is the number of free parameters in the model. When L (the number of possible response patterns) is much greater than N, the frequency table is sparse. This invalidates the use of chi-square distribution as the asymptotic distribution for these
two statistics, and as a result the likelihood ratio chi-square and Pearson’s chi-square statistics should not be used to
evaluate overall model fit.
For item fit, PROC IRT computes the likelihood ratio and Pearson’s chi-square. Pearson’s chi-square statistic, proposed by Yen (1981), has the form
![\[ Q_{1j} = \sum _{k=1}^{10} N_ k\frac{(O_{jk} - E_{jk})^2}{E_{jk}(1-E_{jk})} \]](images/statug_irt0121.png)
The likelihood ratio , proposed by McKinley and Mills (1985), uses the following equation:
![\[ G^2 = 2 \sum _{k=1}^{10} N_ k \left[ O_{jk} \log \frac{O_{jk}}{E_{ik}} + (1-O_{jk})\log \frac{1-O_{jk}}{1-E_{ik}}\right] \]](images/statug_irt0122.png)
These two statistics approximately follow a central chi-square distribution with 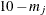 degrees of freedom, where
degrees of freedom, where 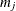 is the number of free parameters for item j.
is the number of free parameters for item j.
To calculate these two statistics, first order all the subjects according to their estimated factor scores, and then partition
them into 10 intervals such that the number of subjects in each interval is approximately equal. 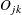 and
and 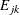 are the observed proportion and expected proportion, respectively, of subjects in interval k who have a correct response on item j. The expected proportions are computed as the mean predicted probability of a correct response in interval k.
are the observed proportion and expected proportion, respectively, of subjects in interval k who have a correct response on item j. The expected proportions are computed as the mean predicted probability of a correct response in interval k.