The GAMPL Procedure
-
Overview

- Getting Started
-
Syntax
-
DetailsMissing ValuesThin-Plate Regression SplinesGeneralized Additive ModelsModel Evaluation CriteriaFitting AlgorithmsDegrees of FreedomModel InferenceDispersion ParameterTests for Smoothing ComponentsComputational Method: MultithreadingChoosing an Optimization TechniqueDisplayed OutputODS Table NamesODS Graphics
-
Examples
- References
Generalized Additive Models
Generalized Linear Models
All probability distributions that the GAMPL procedure fits are members of an exponential family of distributions. For the specification of an exponential family, see the section "Generalized Linear Models Theory" in Chapter 44: The GENMOD Procedure in SAS/STAT 14.1 User's Guide.
Table 7.11 lists and defines some common notation that is used in the context of generalized linear models and generalized additive models.
Table 7.11: Common Notation
|
Notation |
Meaning |
|---|---|
|
|
Log-likelihood |
|
|
Penalized log-likelihood |
|
|
Deviance |
|
|
Penalized deviance |
|
|
Link function |
|
|
Inverse link function |
|
|
Response mean |
|
|
Linear predictor |
|
|
Dispersion parameter |
|
|
Column of adjusted response variable |
|
|
Column of response variance |
|
|
Prior weight for each observation |
|
|
Adjusted weight for each observation |
|
|
Diagonal matrix of adjusted weights |
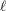
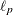
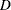
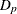
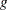
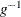
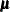
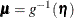
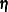
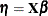


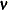
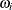
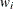
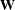
The GAMPL procedure supports the following distributions: binary, binomial, gamma, inverse Gaussian, negative binomial, normal (Gaussian), and Poisson.
For forms of log-likelihood functions for each of the probability distributions, see the section "Log-Likelihood Functions" in Chapter 44: The GENMOD Procedure in SAS/STAT 14.1 User's Guide. For forms of the deviance for each of the probability distributions, see the section "Goodness of Fit" in Chapter 44: The GENMOD Procedure in SAS/STAT 14.1 User's Guide.
Generalized Additive Models
Generalized additive models are extensions of generalized linear models (Nelder and Wedderburn 1972). For each observation that has a response 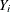 and a row vector of the model matrix
and a row vector of the model matrix 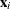 , both generalized additive models and generalized linear models assume the model additivity
, both generalized additive models and generalized linear models assume the model additivity
![\[ g(\mu _ i) = f_1(\mb{x}_{i1}) + \dots + f_ p(\mb{x}_{ip}) \]](images/stathpug_hpgam0127.png)
where 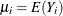 and is independently distributed in some exponential family. Generalized linear models further assume model linearity by
and is independently distributed in some exponential family. Generalized linear models further assume model linearity by 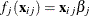 for
for 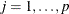 . Generalized additive models relax the linearity assumption by allowing some smoothing functions
. Generalized additive models relax the linearity assumption by allowing some smoothing functions 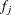 to characterize the dependency. The GAMPL procedure constructs the smoothing functions by using thin-plate regression splines.
For more information about generalized additive models and other type of smoothing functions, see Chapter 41: The GAM Procedure in SAS/STAT 14.1 User's Guide.
to characterize the dependency. The GAMPL procedure constructs the smoothing functions by using thin-plate regression splines.
For more information about generalized additive models and other type of smoothing functions, see Chapter 41: The GAM Procedure in SAS/STAT 14.1 User's Guide.
Consider a generalized additive model that has some linear terms 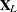 with coefficients
with coefficients 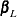 and p smoothing functions . Each smoothing function can be constructed by thin-plate regression splines with a smoothing parameter
and p smoothing functions . Each smoothing function can be constructed by thin-plate regression splines with a smoothing parameter 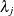 . Using the notations described in the section Low-Rank Approximation, you can characterize each smoothing function by
. Using the notations described in the section Low-Rank Approximation, you can characterize each smoothing function by
![\[ \bbeta _ j = \left[\begin{matrix} \btheta _ j \\ \tilde{\bdelta }_ j \end{matrix}\right], \quad \bX _ j = [\bT _ j : \bU _{kj}\bD _{kj}\bZ _ j ], \quad \text {and} \quad \bS _ j = \left[\begin{matrix} \mb{0} & \mb{0} \\ \mb{0} & \bZ _ j’\bD _{kj} \bZ _ j \end{matrix}\right] \]](images/stathpug_hpgam0135.png)
Notice that each smoothing function representation contains a zero-degree polynomial that corresponds to a constant. Having multiple constant terms makes the smoothing functions unidentifiable. The solution is to include a global constant term (that is, the intercept) in the model and enforce the centering constraint to each smoothing function. You can write the constraint as
![\[ \mb{1}’\bX _ j\bbeta _ j = 0 \]](images/stathpug_hpgam0136.png)
By using a similar approach as the linear constraint for thin-plate regression splines, you obtain the orthogonal column
basis 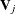 via the QR decomposition of
via the QR decomposition of 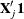 such that
such that 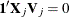 . Each smoothing function can be reparameterized as
. Each smoothing function can be reparameterized as 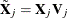 .
.
Let ![$\bX = [ \bX _ L : \tilde{\bX }_1 : \dots : \tilde{\bX }_ p ]$](images/stathpug_hpgam0141.png) and
and ![$\bbeta ’ = [ \bbeta _ L’ : \bbeta _1’ : \dots : \bbeta _ p’]$](images/stathpug_hpgam0142.png) . Then the generalized additive model can be represented as
. Then the generalized additive model can be represented as 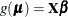 . The roughness penalty matrix is represented as a block diagonal matrix:
. The roughness penalty matrix is represented as a block diagonal matrix:
![\[ \bS _{\blambda } = \begin{bmatrix} \mb{0} & \mb{0} & & \cdots & & \mb{0} \\ \mb{0} & \lambda _1\bS _1 & & \cdots & & \mb{0} \\ & & \ddots & & & \\ \vdots & \vdots & & \lambda _ j\bS _ j & & \vdots \\ & & & & \ddots & \\ \mb{0} & \mb{0} & & \cdots & & \lambda _ p\bS _ p \end{bmatrix} \]](images/stathpug_hpgam0144.png)
Then the roughness penalty is measured in the quadratic form 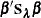 .
.
Penalized Likelihood Estimation
Given a fixed vector of smoothing parameters, ![$\blambda =[\lambda _ i\dots \lambda _ p]’$](images/stathpug_hpgam0146.png) , you can fit the generalized additive models by the penalized likelihood estimation. In contrast to the maximum likelihood
estimation, penalized likelihood estimation obtains an estimate for
, you can fit the generalized additive models by the penalized likelihood estimation. In contrast to the maximum likelihood
estimation, penalized likelihood estimation obtains an estimate for 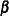 by maximizing the penalized log likelihood,
by maximizing the penalized log likelihood,
![\[ \ell _ p(\bbeta ) = \ell (\bbeta )-\frac{1}{2}\bbeta ’\bS _{\blambda }\bbeta \]](images/stathpug_hpgam0148.png)
Any optimization technique that you can use for maximum likelihood estimation can also be used for penalized likelihood estimation. If first-order derivatives are required for the optimization technique, you can compute the gradient as
![\[ \frac{\partial \ell _ p}{\partial \bbeta } = \frac{\partial \ell }{\partial \bbeta }-\bS _{\blambda }\bbeta \]](images/stathpug_hpgam0149.png)
If second-order derivatives are required for the optimization technique, you can compute the Hessian as
![\[ \frac{\partial ^2\ell _ p}{\partial \bbeta \partial \bbeta '}= \frac{\partial ^2\ell }{\partial \bbeta \partial \bbeta '}-\bS _{\blambda } \]](images/stathpug_hpgam0150.png)
In the gradient and Hessian forms, 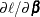 and
and 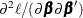 are the corresponding gradient and Hessian, respectively, for the log-likelihood for generalized linear models. For more
information about optimization techniques, see the section Choosing an Optimization Technique.
are the corresponding gradient and Hessian, respectively, for the log-likelihood for generalized linear models. For more
information about optimization techniques, see the section Choosing an Optimization Technique.