HISTOGRAM Statement: CAPABILITY Procedure

Output Data Sets
You can create two output data sets with the HISTOGRAM statement: the OUTFIT= data set and the OUTHISTOGRAM= data set. These data sets are described in the following sections.
OUTFIT= Data Set
The OUTFIT= data set contains the parameters of fitted density curves, information about chi-square and EDF goodness-of-fit tests, specification limit information, and capability indices based on the fitted distribution. Since you can specify multiple HISTOGRAM statements with the CAPABILITY procedure, you can create several OUTFIT= data sets. For each variable plotted with the HISTOGRAM statement, the OUTFIT= data set contains one observation for each fitted distribution requested in the HISTOGRAM statement. If you use a BY statement, the OUTFIT= data set contains several observations for each BY group (one observation for each variable and fitted density combination). ID variables are not saved in the OUTFIT= data set.
The OUTFIT= data set contains the variables listed in Table 5.24. By default, an OUTFIT= data set contains _MIDPT1_ and _MIDPTN_ variables, whose values identify histogram intervals by their midpoints. When the ENDPOINTS= or NENDPOINTS option is specified, intervals are identified by endpoint values instead. If the RTINCLUDE option is specified, the variables _MAXPT1_ and _MAXPTN_ contain upper endpoint values. Otherwise, the variables _MINPT1_ and _MINPTN_ contain lower endpoint values.
Variable |
Description |
|---|---|
_ADASQ_ |
Anderson-Darling EDF goodness-of-fit statistic |
_ADP_ |
p-value for Anderson-Darling EDF goodness-of-fit test |
_CHISQ_ |
chi-square goodness-of-fit statistic |
_CP_ |
generalized capability index |
_CPK_ |
generalized capability index |
_CPL_ |
generalized capability index CPL based on the fitted curve |
_CPM_ |
generalized capability index |
_CPU_ |
generalized capability index CPU based on the fitted curve |
_CURVE_ |
name of fitted distribution (abbreviated to 8 characters) |
_CVMWSQ_ |
Cramer-von Mises EDF goodness-of-fit statistic |
_CVMP_ |
p-value for Cramer-von Mises EDF goodness-of-fit test |
_DF_ |
degrees of freedom for chi-square goodness-of-fit test |
_ESTGTR_ |
estimated percent of population greater than upper specification limit |
_ESTLSS_ |
estimated percent of population less than lower specification limit |
_ESTSTD_ |
estimated standard deviation |
_EXPECT_ |
estimated mean |
_K_ |
generalized capability index |
_KSD_ |
Kolmogorov-Smirnov EDF goodness-of-fit statistic |
_KSP_ |
p-value for Kolmogorov-Smirnov EDF goodness-of-fit test |
_LOCATN_ |
location parameter for fitted distribution. For the Gumbel, inverse Gaussian, and normal distributions, this is either the value of |
_LSL_ |
lower specification limit |
_MAXPT1_ |
upper endpoint of first interval used to calculate the value of the chi-square statistic. |
_MAXPTN_ |
upper endpoint of last interval used to calculate the value of the chi-square statistic. |
_MIDPT1_ |
midpoint of first interval used to calculate the value of the chi-square statistic. This is the leftmost interval that contains at least one value of the variable. |
_MIDPTN_ |
midpoint of last interval used to calculate the value of the chi-square statistic. This is the rightmost interval that contains at least one value of the variable. |
_MINPT1_ |
lower endpoint of first interval used to calculate the value of the chi-square statistic. |
_MINPTN_ |
lower endpoint of last interval used to calculate the value of the chi-square statistic. |
_OBSGTR_ |
observed percent of data greater than upper specification limit |
_OBSLSS_ |
observed percent of data less than the lower specification limit |
_PCHISQ_ |
p-value for chi-square goodness-of-fit test |
_SCALE_ |
value of scale parameter for fitted distribution. For the lognormal distribution, this is the value of |
_SHAPE1_ |
value of shape parameter for fitted distribution. For the beta, gamma, generalized Pareto, and power function distributions, this is the value of |
_SHAPE2_ |
value of shape parameter for fitted distribution. For the beta distribution, this is the value of |
_TARGET_ |
target value |
_USL_ |
upper specification limit |
_VAR_ |
variable name |
_WIDTH_ |
width of histogram interval |
 based on the fitted curve
based on the fitted curve 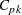 based on the fitted curve
based on the fitted curve 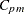 based on the fitted curve
based on the fitted curve 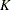 based on the fitted curve
based on the fitted curve 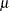 specified with the
specified with the 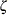 specified or estimated according to the
specified or estimated according to the  , either specified with the
, either specified with the  , either specified with the
, either specified with the  , either specified with the
, either specified with the 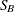 and
and 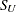 distributions, this is the value of
distributions, this is the value of 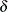 , either specified with the
, either specified with the 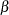 , either specified with the
, either specified with the 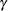 , either specified with the
, either specified with the OUTHISTOGRAM= Data Set
The OUTHISTOGRAM= data set contains information about histogram intervals. Since you can specify multiple HISTOGRAM statements with the CAPABILITY procedure, you can create multiple OUTHISTOGRAM= data sets.
The data set contains a group of observations for each variable plotted with the HISTOGRAM statement. The group contains an observation for each interval of the histogram, beginning with the leftmost interval that contains a value of the variable and ending with the rightmost interval that contains a value of the variable. These intervals will not necessarily coincide with the intervals displayed in the histogram since the histogram may be padded with empty intervals at either end. If you superimpose one or more fitted curves on the histogram, the OUTHISTOGRAM= data set contains multiple groups of observations for each variable (one group for each curve). If you use a BY statement, the OUTHISTOGRAM= data set contains groups of observations for each BY group. ID variables are not saved in the OUTHISTOGRAM= data set.
The OUTHISTOGRAM= data set contains the variables listed in Table 5.25. By default, an OUTHISTOGRAM= data set contains the _MIDPT_ variable, whose values identify histogram intervals by their midpoints. When the ENDPOINTS= or NENDPOINTS option is specified, intervals are identified by endpoint values instead. If the RTINCLUDE option is specified, the _MAXPT_ variable contains an interval’s upper endpoint value. Otherwise, the _MINPT_ variable contains the interval’s lower endpoint value.
Variable |
Description |
|---|---|
_COUNT_ |
number of variable values in histogram interval |
_CURVE_ |
name of fitted distribution (if requested in HISTOGRAM statement) |
_EXPPCT_ |
estimated percent of population in histogram interval determined from optional fitted distribution |
_MAXPT_ |
upper endpoint of histogram interval |
_MIDPT_ |
midpoint of histogram interval |
_MINPT_ |
lower endpoint of histogram interval |
_OBSPCT_ |
percent of variable values in histogram interval |
_VAR_ |
variable name |
OUTKERNEL= Output Data Set
An OUTKERNEL= data set contains information about kernel density estimates requested with the KERNEL option. Because you can specify multiple HISTOGRAM statements with the CAPABILITY procedure, you can create multiple OUTKERNEL= data sets.
An OUTKERNEL= data set contains a group of observations for each kernel density estimate requested with the HISTOGRAM statement. These observations span a range of analysis variable values recorded in the _VALUE_ variable. The procedure determines the increment between values, and therefore the number of observations in the group. The variable _DENSITY_ contains the kernel density calculated for the corresponding analysis variable value.
When a density curve is overlaid on a histogram, the curve is scaled so that the area under the curve equals the total area of the histogram bars. The scaled density values are saved in the variable _COUNT_, _PERCENT_, or _PROPORTION_, depending on the histogram’s vertical axis scale, determined by the VSCALE= option. Only one of these variables appears in a given OUTKERNEL= data set.
Table 5.26 lists the variables in an OUTKERNEL= data set.
Variable |
Description |
|---|---|
_C_ |
standardized bandwidth parameter |
_COUNT_ |
kernel density scaled for VSCALE=COUNT |
_DENSITY_ |
kernel density |
_PERCENT_ |
kernel density scaled for VSCALE=PERCENT (default) |
_PROPORTION_ |
kernel density scaled for VSCALE=PROPORTION |
_TYPE_ |
kernel function |
_VALUE_ |
variable value at which kernel function is calculated |
_VAR_ |
variable name |