The HPMIXED Procedure

Model Assumptions
The following sections provide an overview of the approach used by the HPMIXED procedure for likelihood-based analysis of linear mixed models with sparse matrix technique. Additional theory and examples are provided in Littell et al. (1996); Verbeke and Molenberghs (1997, 2000); Brown and Prescott (1999).
The HPMIXED procedure fits models generally of the form
![\[ \mb{y} = \bX \bbeta + \bZ \bgamma +\bepsilon \]](images/statug_hpmixed0148.png)
Models of this form contain both fixed-effects parameters, 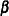 , and random-effects parameters,
, and random-effects parameters, 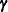 ; hence, they are called mixed models. See Henderson (1990) and Searle, Casella, and McCulloch (1992) for historical developments of the mixed model. Note that the matrix
; hence, they are called mixed models. See Henderson (1990) and Searle, Casella, and McCulloch (1992) for historical developments of the mixed model. Note that the matrix 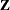 can contain either continuous or dummy variables, just like
can contain either continuous or dummy variables, just like 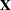 .
.
So far this is the same general form of model fit by the MIXED procedure. The difference between the models handled by the
two procedures lies in the assumptions about the distributions of and  . For both procedures
a key assumption is that and are normally distributed with
. For both procedures
a key assumption is that and are normally distributed with
![\begin{eqnarray*} \mbox{E}\left[ \begin{array}{c} \bgamma \\ \bepsilon \end{array} \right] & = & \left[\begin{array}{c} \Strong{0} \\ \Strong{0} \end{array} \right] \\ \mbox{Var}\left[ \begin{array}{c} \bgamma \\ \bepsilon \end{array} \right] & = & \left[\begin{array}{cc} \bG & \Strong{0} \\ \Strong{0} & \bR \end{array} \right] \end{eqnarray*}](images/statug_hpmixed0149.png)
The two procedures differ in their assumptions about the variance matrices 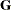 and
and 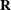 for and , respectively. The MIXED procedure allows a variety of different structures for both and ; while in HPMIXED procedure, is always assumed to be of the form
for and , respectively. The MIXED procedure allows a variety of different structures for both and ; while in HPMIXED procedure, is always assumed to be of the form 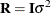 , and the structures available for modeling are only a small subset of the structures offered by the MIXED procedure.
, and the structures available for modeling are only a small subset of the structures offered by the MIXED procedure.
Estimates of fixed effects and predictions for random effects are obtained by solving the so-called mixed model equations:
![\[ \left[ \begin{array}{cc} \bX ’\bX /\sigma ^2 & \bX ’\bZ /\sigma ^2 \\ \bZ ’\bX /\sigma ^2 & \bZ ’\bZ /\sigma ^2 + \bG ^{-1} \end{array}\right] \left[\begin{array}{c} \widehat{\bbeta } \\ \widehat{\bgamma } \end{array}\right] = \left[\begin{array}{c} \bX ’\mb{y}/\sigma ^2 \\ \bZ ’\mb{y}/\sigma ^2 \end{array}\right] \]](images/statug_hpmixed0151.png)
Let 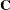 denote the coefficient matrix of the mixed model equations:
denote the coefficient matrix of the mixed model equations:
![\[ \bC = \left[ \begin{array}{cc} \bX ’\bX /\sigma ^2 & \bX ’\bZ /\sigma ^2 \\ \bZ ’\bX /\sigma ^2 & \bZ ’\bZ /\sigma ^2 + \bG ^{-1} \end{array}\right] \]](images/statug_hpmixed0153.png)
Under the assumptions given previously for the moments of and , the variance of 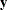 is
is 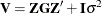 . You can model
. You can model 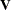 by setting up the random-effects design matrix and by specifying covariance structures for . Let
by setting up the random-effects design matrix and by specifying covariance structures for . Let 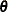 be a vector of all unknown parameters in . Then the general form of the restricted likelihood function for the mixed models that the HPMIXED procedure can fit is
be a vector of all unknown parameters in . Then the general form of the restricted likelihood function for the mixed models that the HPMIXED procedure can fit is
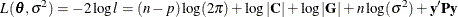
where
![\[ \bP = \bV ^{-1} - \bV ^{-1}\bX (\bX ’\bV ^{-1}\bX )^{-}\bX ’\bV ^{-1} \]](images/statug_hpmixed0157.png)
and p is the rank of . The HPMIXED procedure minimizes 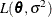 over all unknown parameters in and
over all unknown parameters in and 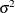 by using nonlinear optimization algorithms.
by using nonlinear optimization algorithms.