Adding a New Column to an Aggregation Table
Special Considerations When Adding a New Column to an Aggregation Table
After an aggregation
target table is defined and the ETL job that starts aggregating data
is run, you might decide to add additional columns to it. For existing
observations in the target table, there might be missing values for
the new columns, depending on the column type. These missing values
can persist unless additional incoming observations are encountered
for that existing class combination. If the change results in missing
values for the new aging column in some observations, those observations
are immediately aged out at the next ETL.
This is especially important
if you change the aging column to a new aging column that is not in
the target table. For more information, see Changing the Aging Column in an Aggregation Table.
The following table
describes how a newly added column is treated:
|
Type of Added Column
|
Result
|
|---|---|
|
A class column that
is not in the target table
|
All pre-existing rows
show a missing value for that new class column. (See the following
discussion about the special impact on aging columns.)
|
|
An ID column that is
not in the target table
|
All pre-existing rows
show a missing value for that new ID column, even though the input
record has missing values. This condition persists until a new input
observation that has a nonmissing value for the same class combination
as an existing row is read.
|
|
A new statistic that
is derived directly from one or more input table columns
|
All pre-existing rows
show a missing value for that new base statistic, even though the
input record has missing values. This condition persists until a new
input observation that has a nonmissing value for the same class combination
as an existing row is read.
|
|
A new percentile
|
Pre-existing rows might
have a nonmissing value under either of these conditions:
|
|
A new statistic that
is derived from other statistics, or a new computed column that is
derived from other columns
|
Pre-existing rows might
have a nonmissing value for the new column if all of the other columns
that the calculation depends on are nonmissing. Otherwise, the pre-existing
rows show a missing value for that new statistic.
|
|
A new join column
|
The values depend entirely
on the values as they are calculated for the table from which the
join column is derived.
|
Changing the Aging Column in an Aggregation Table
Changing the aging
column in an existing aggregation table can produce different results
depending on whether there are already nonmissing values for the new
aging column in the existing table. If the new aging column that
you select does not exist in the table, a message appears that enables
you to continue with the change or to cancel it. If you continue,
all observations are discarded, except for the incoming ones. Some
examples follow:
-
Data exists for the new aging columnSuppose that the previous aging column is DayDate, but WeekDate is already being kept as an ID variable and therefore has valid nonmissing values. In that case, if the user changes the aging column from DayDate to WeekDate, then no unexpected aging occurs at the next ETL. No aging occurs because the transformation has valid values for WeekDate on which to age the data.Note: However, the next ETL results in fewer observations because the number of class combinations is fewer for WeekDate than for DayDate.
-
Data does not exist for the new aging columnSuppose that the change results in a new aging column for which there is no previous data.For example, the user changes the aging column from DayDate to WeekDate and there was no previous data for WeekDate. In that case, the pre-existing rows are immediately aged out at the next ETL because the pre-existing data has missing values for WeekDate. The transformation cannot invent nonmissing values for WeekDate for those pre-existing rows.
How to Add a New Column to an Aggregation Table
To add a new column
to an aggregation table, perform the following steps:
-
Locate the Aggregation transformation that generates the aggregation table that you want to modify. To do so, from the IT Data Marts tree, navigate to the IT data mart that contains the job where the Aggregation transformation is located. Double-click the job to open it on the Diagram tab of the Job Editor window.
-
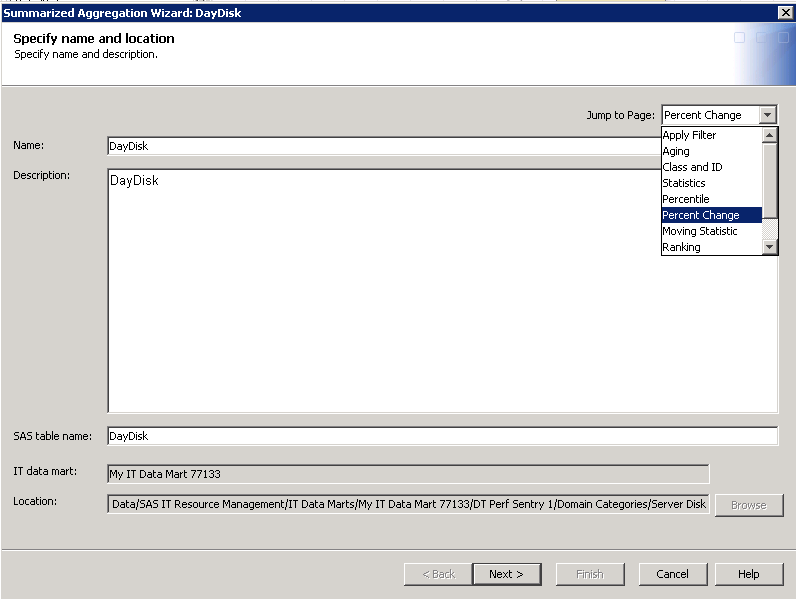
The first page of the wizard appears. The Jump to Page option enables you to display the list of pages that were specified for this table. To go directly to the page that you want to change, select it from the drop-down list. The following display shows the list of pages that are available.Note: To add a column, jump to the page of the wizard where that column is specified. For example, if you want to add a class or ID column, go to the page called Select class and ID columns. Similarly, to add a statistics column, go to the Statistics page, and so on, for the other columns.
-
Modify the contents of the page that you selected. (For information about which fields can be changed, follow the instructions that apply to the creation of the type of table that you want to modify.)
-
For information about creating summarized aggregation tables, see Creating Aggregation Tables with the Summarized Aggregation Table Wizard.
-
For information about creating simple aggregation tables, see Creating an Aggregation Table with the Simple Aggregation Table Wizard.
Note: If you try to delete a column that is used to create a statistic, percentile, percent change, moving statistic, rank, or join column, a warning message is displayed. The message lists the column, where it is used, and its table name. If a column was deleted using the Columns tab of the Properties dialog box, then the next time the aggregation wizard is opened on that table, a message appears that identifies any columns whose source column is no longer available. Click Yes to delete the columns from the table and continue to edit the table. Click No to keep the columns. In that case, the wizard does not open. -
In order for your
changes to take effect, you must redeploy the job. For information about
redeploying jobs, see Redeploy All Jobs on the Server.
CAUTION:
Do not
define a new staged table and use it as the source for an existing
aggregation transformation.
Doing so changes the
metadata identity of the columns of the source table so that the aggregation
transformation cannot process the source table correctly. If new columns
were added to the staged table, you might want to include them in
an associated aggregation table. In that case, modify that aggregation
table by using the Edit function for that
table. (To modify or add a column to an existing staged table, modify
the properties of the table or use the Maintain Tables function. For information about
modifying a staged table, see Modify a Staged Table. For more information about the Maintain Staged
Tables wizard, see About the Maintain Staged Tables Wizard.)
Copyright © SAS Institute Inc. All rights reserved.