The HPQLIM Procedure

Naming
Naming of Parameters
The parameters are named in the same way as in other SAS procedures such as the REG and PROBIT procedures. The constant in the regression equation is called Intercept. The coefficients of independent variables are named by the independent variables. The standard deviation of the errors is called _Sigma. If the HETERO statement is included, the coefficients of the independent variables in the HETERO statement are called _H.x, where x is the name of the independent variable.
Naming of Output Variables
Table 22.10 shows the options in the OUTPUT statement, with the corresponding variable names and their explanations.
Table 22.10: OUTPUT Statement Options
|
output-option |
Variable Name |
Explanation |
|---|---|---|
|
CONDITIONAL |
CEXPCT_y |
Conditional expected value of y, conditioned on the truncation |
|
ERRSTD |
ERRSTD_y |
Standard deviation of error term |
|
EXPECTED |
EXPCT_y |
Unconditional expected value of y |
|
MARGINAL |
MEFF_x |
Marginal effect of x on y ( |
|
PREDICTED |
P_y |
Predicted value of y |
|
RESIDUAL |
RESID_y |
Residual of y, (y – PredictedY) |
|
PROB |
PROB_y |
Probability that y is taking the observed value in this observation (discrete y only) |
|
PROBALL |
PROBi_y |
Probability that y is taking the ith value (discrete y only) |
|
MILLS |
MILLS_y |
Inverse Mills ratio for y |
|
TE1 |
TE1 |
Technical efficiency estimate for each producer proposed by Battese and Coelli (1988) |
|
TE2 |
TE2 |
Technical efficiency estimate for each producer proposed by Jondrow et al. (1982) |
|
XBETA |
XBETA_y |
Structure part ( |
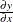
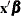
If you prefer to name the output variables differently, you can use the RENAME option in the data set. For example, the following statements rename the residual of y as Resid:
proc hpqlim data=one;
model y = x1-x10 / censored;
output out=outds(rename=(resid_y=resid)) residual;
run;