The HPQLIM Procedure

Output to SAS Data Set
XBeta, Predicted, and Residual
Xbeta is the structural part on the right-hand side of the model. The predicted value is the predicted dependent variable value. For censored variables, if the predicted value is outside the boundaries, it is reported as the closest boundary. The residual is defined only for continuous variables and is defined as
![\[ \text {Residual} = \text {Observed} - \text {Predicted} \]](images/etsug_hpqlim0175.png)
Error Standard Deviation
The error standard deviation is 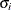 in the model. It varies only when the HETERO statement is used.
in the model. It varies only when the HETERO statement is used.
Marginal Effects
A marginal effect is defined as a contribution of one control variable to the response variable. For a binary choice model
with two response categories, 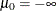 and
and 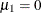 ,
, 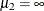 . For an ordinal response model with M response categories (
. For an ordinal response model with M response categories (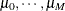 ), define
), define
![\[ R_{i,j} = \mu _{j} - \mb{x}_{i}’\bbeta \]](images/etsug_hpqlim0179.png)
The probability that the unobserved dependent variable is contained in the jth category can be written as
![\[ P[\mu _{j-1}< y_{i}^{*} \leq \mu _{j}] = F(R_{i,j}) - F(R_{i,j-1}) \]](images/etsug_hpqlim0075.png)
The marginal effect of changes in the regressors on the probability of 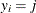 is then
is then
![\[ \frac{\partial \text {Prob}[y_{i}=j]}{\partial \mb{x}} = [f(\mu _{j-1} - \mb{x}_{i}’\bbeta ) - f(\mu _{j} - \mb{x}_{i}’\bbeta )] \bbeta \]](images/etsug_hpqlim0181.png)
where 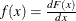 . In particular,
. In particular,
![\[ f(x) = \frac{d F(x)}{dx} = \left\{ \begin{array}{ll} \frac{1}{\sqrt {2\pi }}e^{-x^2/2} & \mr{(probit)} \\ \frac{e^{-x}}{[1+e^{(-x)}]^2} & \mr{(logit)} \end{array} \right. \]](images/etsug_hpqlim0183.png)
The marginal effects in the truncated regression model are
![\[ \frac{\partial {E}[y_{i}|L_{i} < y_{i}^{*} < R_{i}]}{\partial \mb{x}} = \bbeta \left[ 1 - \frac{(\phi (a_{i})-\phi (b_{i}))^2}{(\Phi (b_{i})-\Phi (a_{i}))^2} + \frac{a_{i}\phi (a_{i})-b_{i}\phi (b_{i})}{\Phi (b_{i})-\Phi (a_{i})} \right] \]](images/etsug_hpqlim0184.png)
where 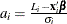 and
and 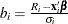 .
.
The marginal effects in the censored regression model are
![\[ \frac{\partial {E}[y|\mb{x}_{i}]}{\partial \mb{x}} = \bbeta \times \text {Prob}[L_{i}<y_{i}^{*}<R_{i}] \]](images/etsug_hpqlim0187.png)
Expected and Conditionally Expected Values
The expected value is the unconditional expectation of the dependent variable. For a censored variable, it is
![\[ E[y_ i] = \Phi (a_{i}) L_{i} + (\mb{x}_{i}’\bbeta + \lambda \sigma _ i) (\Phi (b_{i})-\Phi (a_{i})) + (1-\Phi (b_{i})) R_{i} \]](images/etsug_hpqlim0188.png)
For a left-censored variable (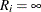 ), this formula is
), this formula is
![\[ E[y_ i] = \Phi (a_{i}) L_{i} + (\mb{x}_{i}’\bbeta + \lambda \sigma _ i) (1-\Phi (a_{i})) \]](images/etsug_hpqlim0190.png)
where 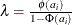 .
.
For a right-censored variable (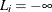 ), this formula is
), this formula is
![\[ E[y_ i] = (\mb{x}_{i}’\bbeta + \lambda \sigma _ i) \Phi (b_{i}) + (1-\Phi (b_{i})) R_{i} \]](images/etsug_hpqlim0193.png)
where 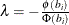 .
.
For a noncensored variable, this formula is
![\[ E[y_ i] = \mb{x}_{i}’\bbeta \]](images/etsug_hpqlim0195.png)
The conditional expected value is the expectation when the variable is inside the boundaries:
![\[ E[y_ i| L_ i< y_ i < R_ i] = \mb{x}_{i}’\bbeta + \lambda \sigma _ i \]](images/etsug_hpqlim0196.png)
Technical Efficiency
Technical efficiency for each producer is computed only for stochastic frontier models.
In general, the stochastic production frontier can be written as
![\[ y_ i=f(x_ i;\beta )\exp \{ v_ i\} TE_ i \]](images/etsug_hpqlim0197.png)
where 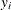 denotes producer i’s actual output,
denotes producer i’s actual output, 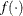 is the deterministic part of the production frontier,
is the deterministic part of the production frontier, 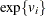 is a producer-specific error term, and
is a producer-specific error term, and 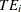 is the technical efficiency coefficient, which can be written as
is the technical efficiency coefficient, which can be written as
![\[ TE_ i=\frac{y_ i}{f(x_ i;\beta )\exp \{ v_ i\} } \]](images/etsug_hpqlim0202.png)
For a Cobb-Douglas production function, 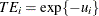 . For more information, see the section Stochastic Frontier Production and Cost Models.
. For more information, see the section Stochastic Frontier Production and Cost Models.
The cost frontier can be written in general as
![\[ E_ i=c(y_ i,w_ i;\beta )\exp \{ v_ i\} /CE_ i \]](images/etsug_hpqlim0204.png)
where 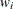 denotes producer i’s input prices,
denotes producer i’s input prices, 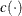 is the deterministic part of the cost frontier, is a producer-specific error term, and
is the deterministic part of the cost frontier, is a producer-specific error term, and 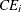 is the cost efficiency coefficient, which can be written as
is the cost efficiency coefficient, which can be written as
![\[ CE_ i=\frac{c(x_ i,w_ i;\beta )\exp \{ v_ i\} }{E_ i} \]](images/etsug_hpqlim0207.png)
For a Cobb-Douglas cost function, 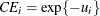 . For more information, see the section Stochastic Frontier Production and Cost Models. Hence, both technical and cost efficiency coefficients are the same. The estimates of technical efficiency are provided
in the following subsections.
. For more information, see the section Stochastic Frontier Production and Cost Models. Hence, both technical and cost efficiency coefficients are the same. The estimates of technical efficiency are provided
in the following subsections.
Normal-Half-Normal Model
Define 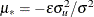 and
and 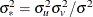 . Then, as shown by Jondrow et al. (1982), conditional density is as follows:
. Then, as shown by Jondrow et al. (1982), conditional density is as follows:
![\[ f(u|\epsilon )=\frac{f(u,\epsilon )}{f(\epsilon )} =\frac{1}{\sqrt {2\pi }\sigma _*}\exp \left\{ -\frac{(u-\mu _*)^2}{2\sigma _*^2}\right\} \bigg/\left[1-\Phi \left(-\frac{\mu _*}{\sigma _*}\right)\right] \]](images/etsug_hpqlim0211.png)
Hence, 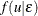 is the density for
is the density for 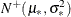 .
.
From this result, it follows that the estimate of technical efficiency (Battese and Coelli 1988) is
![\[ TE1_ i=E(\exp \{ -u_ i\} |\epsilon _ i)=\left[\frac{1-\Phi (\sigma _*-\mu _{*i}/\sigma _*)}{1-\Phi (-\mu _{*i}/\sigma _*)}\right]\exp \left\{ -\mu _{*i}+\frac{1}{2}\sigma _*^2\right\} \]](images/etsug_hpqlim0214.png)
The second version of the estimate (Jondrow et al. 1982) is
![\[ TE2_ i=\exp \{ -E(u_ i|\epsilon _ i)\} \]](images/etsug_hpqlim0215.png)
where
![\[ E(u_ i|\epsilon _ i)=\mu _{*i}+\sigma _*\left[\frac{\phi (-\mu _{*i}/\sigma _*)}{1-\Phi (-\mu _{*i}/\sigma _*)}\right]=\sigma _*\left[\frac{\phi (\epsilon _ i\lambda /\sigma )}{1-\Phi (\epsilon _ i\lambda /\sigma )}-\left(\frac{\epsilon _ i\lambda }{\sigma }\right)\right] \]](images/etsug_hpqlim0216.png)
Normal-Exponential Model
Define 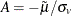 and
and 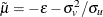 . Then, as shown by Kumbhakar and Lovell (2000), conditional density is as follows:
. Then, as shown by Kumbhakar and Lovell (2000), conditional density is as follows:
![\[ f(u|\epsilon ) =\frac{1}{\sqrt {2\pi }\sigma _ v\Phi (-\tilde{\mu }/\sigma _ v)}\exp \left\{ -\frac{(u-\tilde{\mu })^2}{2\sigma ^2}\right\} \]](images/etsug_hpqlim0219.png)
Hence, is the density for 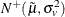 .
.
From this result, it follows that the estimate of technical efficiency is
![\[ TE1_ i=E(\exp \{ -u_ i\} |\epsilon _ i)=\left[\frac{1-\Phi (\sigma _ v-\tilde{\mu }_ i/\sigma _ v)}{1-\Phi (-\tilde{\mu }_ i/\sigma _ v)}\right]\exp \left\{ -\tilde{\mu }_ i+\frac{1}{2}\sigma _ v^2\right\} \]](images/etsug_hpqlim0221.png)
The second version of the estimate is
where
![\[ E(u_ i|\epsilon _ i)=\tilde{\mu }_ i+\sigma _ v\left[\frac{\phi (-\tilde{\mu }_ i/\sigma _ v)}{1-\Phi (-\tilde{\mu }_ i/\sigma _ v)}\right]=\sigma _ v\left[\frac{\phi (A)}{\Phi (-A)}-A\right] \]](images/etsug_hpqlim0222.png)
Normal–Truncated Normal Model
Define 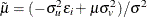 and . Then, as shown by Kumbhakar and Lovell (2000), conditional density is as follows:
and . Then, as shown by Kumbhakar and Lovell (2000), conditional density is as follows:
![\[ f(u|\epsilon )= \frac{1}{\sqrt {2\pi }\sigma _*[1-\Phi (-\tilde{\mu }/\sigma _*)]}\exp \left\{ -\frac{(u-\tilde{\mu })^2}{2\sigma _*^2}\right\} \]](images/etsug_hpqlim0224.png)
Hence, is the density for 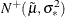 .
.
From this result, it follows that the estimate of technical efficiency is
![\[ TE1_ i=E(\exp \{ -u_ i\} |\epsilon _ i)=\frac{1-\Phi (\sigma _*-\tilde{\mu }_ i/\sigma _*)}{1-\Phi (-\tilde{\mu }_ i/\sigma _*)}\exp \left\{ -\tilde{\mu }_ i+\frac{1}{2}\sigma _*^2\right\} \]](images/etsug_hpqlim0226.png)
The second version of the estimate is
where
![\[ E(u_ i|\epsilon _ i)=\tilde{\mu }_ i+\sigma _*\left[\frac{\phi (\tilde{\mu }_ i/\sigma _*)}{1-\Phi (-\tilde{\mu }_ i/\sigma _*)}\right] \]](images/etsug_hpqlim0227.png)