The SURVEYPHREG Procedure
- Overview
- Getting Started
-
Syntax
 PROC SURVEYPHREG StatementBY StatementCLASS StatementCLUSTER StatementDOMAIN StatementESTIMATE StatementFREQ StatementLSMEANS StatementLSMESTIMATE StatementMODEL StatementNLOPTIONS StatementOUTPUT StatementProgramming StatementsREPWEIGHTS StatementSLICE StatementSTORE StatementSTRATA StatementTEST StatementWEIGHT Statement
PROC SURVEYPHREG StatementBY StatementCLASS StatementCLUSTER StatementDOMAIN StatementESTIMATE StatementFREQ StatementLSMEANS StatementLSMESTIMATE StatementMODEL StatementNLOPTIONS StatementOUTPUT StatementProgramming StatementsREPWEIGHTS StatementSLICE StatementSTORE StatementSTRATA StatementTEST StatementWEIGHT Statement -
DetailsNotation and EstimationFailure Time DistributionTime and CLASS Variables UsagePartial Likelihood Function for the Cox ModelSpecifying the Sample DesignMissing ValuesVariance EstimationDomain AnalysisHypothesis Tests, Confidence Intervals, and ResidualsOutput Data SetsDisplayed OutputODS Table NamesODS Graphics
-
Examples
- References
MODEL Statement
-
MODEL response <*censor (list)> = effects </ options>;
The MODEL statement identifies the variable to be used as the failure time variable, the optional censoring variable, and
the explanatory effects, including covariates, main effects, and interactions; see the section Specification of Effects in Chapter 46: The GLM Procedure, for more information. A note of caution: specifying the effect T*A in the MODEL statement, where T is the time variable and A is a CLASS variable, does not make the effect time-dependent. You must specify exactly one MODEL statement.
The MODEL statement allows one response variable. In the MODEL statement, the failure time variable precedes the equal sign. This can optionally be followed by an asterisk, the name of the censoring variable, and a list of censoring values (separated by blanks or commas if there is more than one) enclosed in parentheses. If the censoring variable takes on one of these values, the corresponding failure time is considered to be censored. The variables following the equal sign are the explanatory variables (sometimes called independent variables or covariates) for the model.
The censoring variable must be numeric. The failure time variable must contain nonnegative values. Any observation with a negative failure time is excluded from the analysis, as is any observation with a missing value for any of the variables listed in the MODEL statement. See Missing Values for details.
Table 113.6 summarizes the options available in the MODEL statement, which can be specified after a slash (/).
Table 113.6: MODEL Statement Options
|
Option |
Description |
|---|---|
|
Specifies |
|
|
Computes confidence limits for regression parameters |
|
|
Displays covariance matrix |
|
|
Specifies the denominator degrees of freedom |
|
|
Displays the Hessian matrix |
|
|
Displays the inverse of the Hessian matrix |
|
|
Computes confidence limits for the exponentials of the regression parameters |
|
|
Computes the ratio of two standard errors for the regression coefficients |
|
|
Specifies tolerance for testing singularity |
|
|
Specifies the method of handling ties in failure times |
|
|
Specifies a variance adjustment factor |
|
|
Computes the ratio of two variances for the regression coefficients |
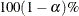
-
ALPHA=

-
sets the level of the confidence limits for the estimated regression parameters and the hazard ratios. The value of alpha must be between 0 and 1, and the default is 0.05. A confidence level of
produces 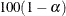 % confidence limits. The default of ALPHA=0.05 produces 95% confidence limits.
% confidence limits. The default of ALPHA=0.05 produces 95% confidence limits.
The ALPHA= option has no effect unless you also specify the CLPARM or RISKLIMITS option.
- CLPARM
-
produces confidence limits for regression parameters of Cox proportional hazards models. You can specify the confidence coefficient by using the ALPHA= option. Classification main effects that use parameterizations other than REF, EFFECT, or GLM are ignored. For more information, see the section Confidence Intervals.
- COVB
-
displays the estimated covariance matrix of the parameter estimates.
- DF=value | keyword <(value)>
-
specifies the denominator degrees of freedom for hypothesis tests, specifies the degrees of freedom for confidence limits, and requests adjustments to the Wald test statistics. If you specify a value, it must be a nonnegative number.
In the description that follows, d denotes the usual degrees of freedom computed from the survey data by using the number of strata, clusters, or replicate weights. For more information, see the section Degrees of Freedom.
By default, DF=PARMADJ when you use the Taylor series linearized variance estimator, and DF=DESIGN when you use the replication variance estimator. Alternatively, you can specify a nonnegative value for the degrees of freedom, or you can specify one of the following keywords:
- HESS
- INVHESS
-
displays the inverse of the Hessian matrix that is evaluated at the estimated regression parameters.
-
RISKLIMITS
RL -
produces confidence limits for hazard ratios and related quantities. For more information, see the section Hazard Ratios. You can specify the confidence coefficient by using the ALPHA= option. You must take great care with any interpretation of the estimates and their confidence limits if interaction effects are involved in the model or if parameterizations other than REF, EFFECT, or GLM are used.
- SERATIO=ALL | MODEL | IND
-
computes the ratio of two standard errors for the regression parameters. The standard error in the numerator uses the complete design information that you specify. You can specify the following options to compute different standard errors for the denominator:
- SINGULAR=value
-
specifies the singularity criterion for determining linear dependencies in the set of explanatory variables. The default value is
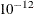 .
.
- TIES=method
-
specifies how to handle ties in the failure time. You can specify the following methods:
If there are no ties, both methods result in the same likelihood and yield identical estimates. By default, TIES=BRESLOW, which is the most efficient method when there are no ties.
- VADJUST=DF | PARMADJ | NONE | AVGREPSS
-
specifies variance adjustment factors. You can specify the following keywords:
-
DF
PARMADJ -
requests the degrees-of-freedom adjustment
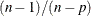 in the computation of the matrix
in the computation of the matrix 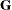 for the Taylor series linearization variance estimation
.
for the Taylor series linearization variance estimation
.
- NONE
-
excludes the degrees-of-freedom adjustment
from the computation of the matrix for the Taylor series linearization variance estimation
. By default, VADJUST=NONE.
- AVGREPSS
-
use the average sum of squares from all the usable replicate samples for the unusable replicates. This option is applicable only for the jackknife replication method. VADJUST=AVGREPSS multiplies the default jackknife variance estimator by the factor
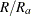 , where
, where 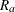 is the number of usable replicates and R is the total number of replicates. For more information, see the section Variance Adjustment Factors.
is the number of usable replicates and R is the total number of replicates. For more information, see the section Variance Adjustment Factors.
-
DF
- VARRATIO=ALL | MODEL | IND
-
computes the ratio of two variances for the regression parameters. The variance in the numerator uses the complete design information. You can specify the following options to compute different variances for the denominator: