The SEQTEST Procedure
-
Overview

- Getting Started
-
Syntax
-
DetailsInput Data SetsBoundary VariablesInformation Level Adjustments at Future StagesBoundary Adjustments for Information LevelsBoundary Adjustments for Minimum Error SpendingBoundary Adjustments for Overlapping Lower and Upper beta BoundariesStochastic CurtailmentRepeated Confidence IntervalsAnalysis after a Sequential TestAvailable Sample Space Orderings in a Sequential TestApplicable Tests and Sample Size ComputationTable OutputODS Table NamesGraphics OutputODS Graphics
-
ExamplesTesting the Difference between Two ProportionsTesting an Effect in a Regression ModelTesting an Effect with Early Stopping to Accept H0Testing a Binomial ProportionComparing Two Proportions with a Log Odds Ratio TestComparing Two Survival Distributions with a Log-Rank TestTesting an Effect in a Proportional Hazards Regression ModelTesting an Effect in a Logistic Regression ModelConducting a Trial with a Nonbinding Acceptance Boundary
- References
Boundary Adjustments for Information Levels
In a group sequential clinical trial, if the information level for the observed test statistic does not match the corresponding information level in the BOUNDARY= data set, the INFOADJ=PROP option (which is the default) can be used to modify information levels at future stages to accommodate this observed information level. With the adjusted information levels, the ERRSPENDADJ= option provides various methods to compute error spending values at the current and future interim stages. These error spending values are then used to derive boundary values in the SEQTEST procedure. See the section Error Spending Methods in Chapter 101: The SEQDESIGN Procedure, for more information about how to use these error spending values to derive boundary values.
The ERRSPENDADJ=NONE option keeps the error spending the same at each stage. The ERRSPENDADJ=ERRLINE option uses a linear interpolation on the cumulative error spending in the design stored in the BOUNDARY= data set to derive the error spending for each unmatched information level (Kittelson and Emerson 1999, p. 882). That is, the cumulative error spending for an information level I is computed as
![\[ e( I) = \left\{ \begin{array}{ll} e_{1} \, \left( \frac{I}{I_{1}} \right) & \mr{if} \, \, I < I_{1} \\ e_{j} + (\alpha _{j+1}-\alpha _{j}) \, \left( \frac{I-I_{j}}{I_{j+1}-I_{j}} \right) & \mr{if} \, \, I_{j} \leq I < I_{j+1} \\ e_{K} & \mr{if} \, \, I \geq I_{K} \\ \end{array} \right. \]](images/statug_seqtest0083.png)
where  ,
,  , …,
, …,  are the cumulative errors at the K stages of the design that is stored in the BOUNDARY= data set.
are the cumulative errors at the K stages of the design that is stored in the BOUNDARY= data set.
The ERRSPENDADJ=ERRFUNCPOC option uses Pocock-type cumulative error spending function (Lan and DeMets 1983):
![\[ E( t) = \left\{ \begin{array}{ll} 1 & \mr{if} \, \, t \geq 1 \\ \mr{log}( \, 1+(e-1)t) & \mr{if} \, \, 0 < t < 1 \\ 0 & \mr{otherwise} \end{array} \right. \]](images/statug_seqtest0087.png)
With an error level of  or
or 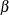 , the cumulative error spending for an information level I is
, the cumulative error spending for an information level I is  or
or  .
.
The ERRSPENDADJ=ERRFUNCOBF option uses O’Brien-Fleming-type cumulative error spending function (Lan and DeMets 1983):
![\[ E( t; a) = \left\{ \begin{array}{ll} 1 & \mr{if} \, \, t \geq 1 \\ \frac{1}{a} \, 2 \, ( 1 - \Phi ( \frac{z_{(1-a/2)}}{\sqrt {t}})) & \mr{if} \, \, 0 < t < 1 \\ 0 & \mr{otherwise} \end{array} \right. \]](images/statug_seqtest0090.png)
where a is either for the spending function or for the spending function, and 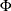 is the cumulative distribution function of the standardized Z statistic. That is, with an error level of or , the cumulative error spending for an information level I is
is the cumulative distribution function of the standardized Z statistic. That is, with an error level of or , the cumulative error spending for an information level I is  or
or  .
.
The ERRSPENDADJ=ERRFUNCGAMMA option uses gamma cumulative error spending function (Hwang, Shih, and DeCani 1990):
![\[ E( t; \gamma ) = \left\{ \begin{array}{ll} 1 & \mr{if} \, \, t \geq 1 \\ \frac{1 - e^{-\gamma t}}{1 - e^{-\gamma }} & \mr{if} \, \, 0 < t < 1 , \gamma \neq 0\\ {t} & \mr{if} \, \, 0 < t < 1 , \gamma = 0 \\ 0 & \mr{otherwise} \end{array} \right. \]](images/statug_seqtest0094.png)
where 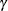 is the parameter specified in the GAMMA= option. That is, with an error level of or , the cumulative error spending for an information level I is
is the parameter specified in the GAMMA= option. That is, with an error level of or , the cumulative error spending for an information level I is  or
or  .
.
The ERRSPENDADJ=ERRFUNCPOW option uses power cumulative error spending function (Jennison and Turnbull 2000, p. 148):
![\[ E( t; \rho ) = \left\{ \begin{array}{ll} 1 & \mr{if} \, \, t \geq 1 \\ {t}^{\rho } & \mr{if} \, \, 0 < t < 1 \\ 0 & \mr{otherwise} \end{array} \right. \]](images/statug_seqtest0097.png)
where 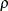 is the power parameter specified in the RHO= suboption. With an error level of or , the cumulative error spending for an information level I is
is the power parameter specified in the RHO= suboption. With an error level of or , the cumulative error spending for an information level I is  or
or  .
.
If the BOUNDARYKEY=BOTH option is specified, the maximum information required for the trial might not be the same as the maximum information level stored in the BOUNDARY= data set. In this case, the information levels at future stages are adjusted proportionally, and the same error spending values that were computed based on the maximum information level stored in the BOUNDARY= data set are used to derive boundary values for the trial.
If an error spending function is used to create boundaries for the design in the SEQDESIGN procedure, then in order to better maintain the design features throughout the group sequential trial, the same error spending function to create boundaries for the design in the SEQDESIGN procedure should be used to modify boundaries in the SEQTEST procedure at each subsequent stage.