The QUANTREG Procedure

PROC QUANTREG Statement
-
PROC QUANTREG <options>;
The PROC QUANTREG statement invokes the QUANTREG procedure. Table 95.1 summarizes the options available in the PROC QUANTREG statement.
Table 95.1: PROC QUANTREG Statement Options
|
Option |
Description |
|---|---|
|
Specifies an algorithm to estimate the regression parameters |
|
|
Specifies the level of significance |
|
|
Specifies a method to compute confidence intervals |
|
|
Specifies the input SAS data set |
|
|
Specifies an input SAS data set that contains initial estimates |
|
|
Specifies the length of effect names |
|
|
Specifies the order in which to sort classification variables |
|
|
Specifies an output SAS data set containing the parameter estimates |
|
|
Specifies options that control details of the plots |
You can specify the following options in the PROC QUANTREG statement.
- ALGORITHM=algorithm <( suboptions )>
-
specifies an algorithm for estimating the regression parameters.
You can specify one of the following four algorithms:
The default algorithm depends on the number of observations (n) and the number of covariates (p) in the model estimation. See Table 95.2 for the relevant defaults.
Table 95.2: The Default Estimation Algorithm
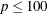
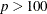
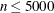
SIMPLEX
SMOOTH
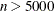
INTERIOR
SMOOTH
- ALPHA=value
-
specifies the level of significance
 for
for 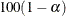 % confidence intervals for
regression parameters. The value must be between 0 and 1. The default is ALPHA=0.05, which corresponds to a 0.95 confidence interval.
% confidence intervals for
regression parameters. The value must be between 0 and 1. The default is ALPHA=0.05, which corresponds to a 0.95 confidence interval.
- CI=NONE | RANK | SPARSITY<(BF | HS)></IID> | RESAMPLING<(NREP=n)>
-
specifies a method for computing confidence intervals for regression parameters. When you specify CI=SPARSITY or CI=RESAMPLING, the QUANTREG procedure also computes standard errors, t values, and p-values for regression parameters.
Table 95.3 summarizes these methods.
Table 95.3: Options for Confidence Intervals
Value of CI=
Method
Additional Options
NONE
No confidence intervals computed
RANK
By inverting rank-score tests
RESAMPLING
By resampling
NREP
SPARSITY
By estimating sparsity function
HS, BF, and IID
By default, when there are fewer than 5,000 observations, fewer than 20 variables in the data set, and the algorithm is simplex, the QUANTREG procedure computes confidence intervals by using the inverted rank-score test method. Otherwise, the resampling method is used.
By default, confidence intervals are not computed for the quantile process, which is estimated when you specify the QUANTILE=PROCESS option in the MODEL statement. Confidence intervals for the quantile process are computed by using the sparsity or resampling methods when you specify CI=SPARSITY or CI=RESAMPLING, respectively. The rank method for confidence intervals is not available for quantile processes because it is computationally prohibitive.
When you specify the SPARSITY option, you have two suboptions for estimating the sparsity function. If you specify the IID suboption, the sparsity function is estimated by assuming that the errors in the linear model are independent and identically distributed (iid). By default, the sparsity function is estimated by assuming that the conditional quantile function is locally linear. For more information, see the section Sparsity. For both methods, two bandwidth selection methods are available: You can specify the BF suboption for the Bofinger method or the HS suboption for the Hall-Sheather method. By default, the Hall-Sheather method is used.
When you specify the RESAMPLING option, you can specify the NREP=n suboption for the number of repetitions. By default, NREP=200. The value of n must be greater than 50.
- DATA=SAS-data-set
-
specifies the input SAS data set to be used by the QUANTREG procedure. By default, the most recently created SAS data set is used.
- INEST=SAS-data-set
-
specifies an input SAS data set that contains initial estimates for all the parameters in the model. The interior point algorithm and the smoothing algorithm use these estimates as a start. For a detailed description of the contents of the INEST= data set, see the section INEST= Data Set.
- NAMELEN=n
-
restricts the length of effect names in tables and output data sets to n characters, where n is a value between 20 and 200. By default, NAMELEN=20.
- ORDER=DATA | FORMATTED | FREQ | INTERNAL
-
specifies the sort order for the levels of the classification variables (which are specified in the CLASS statement).
This option applies to the levels for all classification variables, except when you use the (default) ORDER=FORMATTED option with numeric classification variables that have no explicit format. In that case, the levels of such variables are ordered by their internal value.
The ORDER= option can take the following values:
Value of ORDER=
Levels Sorted By
DATA
Order of appearance in the input data set
FORMATTED
External formatted value, except for numeric variables with no explicit format, which are sorted by their unformatted (internal) value
FREQ
Descending frequency count; levels with the most observations come first in the order
INTERNAL
Unformatted value
By default, ORDER=FORMATTED. For ORDER=FORMATTED and ORDER=INTERNAL, the sort order is machine-dependent.
For more information about sort order, see the chapter on the SORT procedure in the Base SAS Procedures Guide and the discussion of BY-group processing in SAS Language Reference: Concepts.
- OUTEST=SAS-data-set
-
specifies an output SAS data set to contain the parameter estimates for all quantiles. See the section OUTEST= Data Set for a detailed description of the contents of the OUTEST= data set.
-
PLOT | PLOTS<(global-plot-options)> <=plot-request>
PLOT | PLOTS<(global-plot-options)> <=(plot-request < …plot-request > )> -
specifies options that control details of the plots. These plots fall into two categories: diagnostic plots and fit plots. You can also use the PLOT= option in the MODEL statement to request the quantile process plot for any effects that are specified in the model. If you do not specify the PLOTS= option, PROC QUANTREG produces the quantile fit plot by default when a single continuous variable is specified in the model.
When you specify only one plot-request, you can omit the parentheses around the plot request.
Here are some examples:
plots=ddplot plots=(ddplot rdplot)
ODS Graphics must be enabled before plots can be requested. For example:
ods graphics on; proc quantreg plots=fitplot; model y=x1; run;
For more information about enabling and disabling ODS Graphics, see the section Enabling and Disabling ODS Graphics in Chapter 21: Statistical Graphics Using ODS.
You can specify the following global-plot-options, which apply to all plots that PROC QUANTREG generates:
You can specify the following plot-requests:
- PP
-
requests preprocessing to speed up the interior point algorithm or the smoothing algorithm. The preprocessing uses a subsampling algorithm (which assumes that the data set is evenly distributed) to iteratively reduce the original problem to a smaller one. Preprocessing should be used only for very large data sets, such as data sets with more than 100,000 observations. For more information, see Portnoy and Koenker (1997).