The GEE Procedure

REPEATED Statement
-
REPEATED SUBJECT=subject-effect </ options>;
The REPEATED statement specifies the correlation structure of the responses for GEE model fitting. In addition, the REPEATED statement controls the iterative fitting algorithm and specifies optional output.
Table 43.8 summarizes the options available in the REPEATED statement.
Table 43.8: REPEATED Statement Options
|
Option |
Description |
|---|---|
|
Specifies initial values for log odds ratio regression parameters |
|
|
Specifies the convergence criterion for GEE parameter estimation |
|
|
Displays the estimated correlation matrix |
|
|
Displays the estimated working correlation matrix |
|
|
Displays the estimated covariance matrix |
|
|
Displays the estimated empirical correlation matrix |
|
|
Displays the estimated empirical covariance matrix |
|
|
Specifies initial values of the regression parameters estimation |
|
|
Specifies an initial value of the intercept |
|
|
Specifies the use of alternating logistic regression and a model for the log odds ratio |
|
|
Specifies the maximum number of iterations |
|
|
Displays the estimated model-based correlation matrix |
|
|
Displays the estimated model-based covariance matrix |
|
|
Displays a parameter estimates table with the model-based standard errors |
|
|
Specifies a variable that defines subclusters |
|
|
Identifies a different subject (cluster) |
|
|
Specifies the working correlation matrix structure |
|
|
Specifies the order of measurements within subjects |
|
|
Specifies the full |
|
|
Specifies the rows of the |
You must specify the SUBJECT= option:
You can also specify the following options after a slash (/) to control how the model is fit and what output is produced:
- ALPHAINIT=numbers
-
specifies initial values for log odds ratio regression parameters if you specify the option LOGOR= for data that have either binary or ordinal multinomial responses. The default value of numbers is 0.01.
- CONVERGE=number
-
specifies the convergence criterion for GEE parameter estimation. If the maximum absolute difference between regression parameter estimates is less than number on two successive iterations, convergence is declared. If the absolute value of a regression parameter estimate is greater than 0.08, then the absolute difference normalized by the regression parameter value is used instead of the absolute difference. The default value of number is 0.0001.
- CORRB
-
displays the estimated regression parameter correlation matrix. Both model-based and empirical correlations are displayed.
- CORRW
-
displays the estimated working correlation matrix. If you specify TYPE=EXCH for the exchangeable working correlation structure, then the CORRW option is not needed to view the estimated correlation, because a table that contains the single estimated correlation is printed by default.
- COVB
-
displays the estimated regression parameter covariance matrix. Both model-based and empirical covariances are displayed.
- ECORRB
-
displays the estimated regression parameter empirical correlation matrix.
- ECOVB
-
displays the estimated regression parameter empirical covariance matrix.
- INITIAL=numbers
-
specifies initial values of the regression parameters estimation, other than the intercept parameter, for GEE estimation. If you do not specify this option, then the estimated regression parameters (assuming independence for all responses) are used for the initial values.
- INTERCEPT=number
-
specifies an initial value of the intercept regression parameter in the GEE model.
- LOGOR=log-odds-ratio-structure-keyword
-
specifies the use of the alternating logistic regression (ALR) method and the regression model structure for the log odds ratio. For data that have either a binary or ordinal multinomial response distribution, the ALR method uses the log odds ratio to model the association of the responses from subjects. For more information about the ALR method and examples of specifying log odds ratio models, see the section Alternating Logistic Regression. You can specify the values that are shown in Table 43.9.
Table 43.9: Log Odds Ratio Regression Structures
Keyword
Log Odds Ratio Regression Structure
EXCH
Exchangeable
FULLCLUST
Fully parameterized clusters
LOGORVAR(variable)
Indicator variable for specifying block effects
NESTK
k-nested
NEST1
1-nested
ZFULL
Fully specified
 matrix specified in ZDATA= data set
matrix specified in ZDATA= data set
ZREP
Single cluster specification for replicated
matrix specified
in ZDATA= data set
ZREP(matrix)
Single cluster specification for replicated
matrix
For ordinal multinomial data, only the exchangeable regression structure that is specified by LOGOR=EXCH is supported. You should specify the option LOGOR= or TYPE=, but not both.
-
MAXITER=number
MAXIT=number -
specifies the maximum number of iterations allowed in the iterative GEE estimation process. By default, MAXITER=50.
- MCORRB
-
displays the estimated regression parameter model-based correlation matrix.
- MCOVB
-
displays the estimated regression parameter model-based covariance matrix.
- MODELSE
-
displays a parameter estimates table that uses model-based standard errors for inference. By default, a "Parameter Estimates" table that is based on empirical standard errors is displayed.
-
SUBCLUSTER=variable
SUBCLUST=variable -
specifies a variable that defines subclusters for the 1-nested or k-nested log odds ratio association modeling structures for data that have a binary response distribution. A 1-nested or k-nested modeling structure is specified in the option LOGOR=, and variable must be listed in the CLASS statement. For definitions of the 1-nested and k-nested modeling structures, see the section Specifying Log Odds Ratio Models.
-
TYPE=correlation-structure-keyword
CORR=correlation-structure-keyword -
specifies the structure of the working correlation matrix that is used to model the correlation of the responses from subjects for ordinary GEEs. You can specify the values that are shown in Table 43.10 (for definitions of the correlation matrix types, see Table 43.11 in the section Details: GEE Procedure).
Table 43.10: Correlation Structure Types
Keyword
Correlation Structure Type
AR | AR(1)
Autoregressive(1)
EXCH | CS
Exchangeable
IND
Independent
MDEP(number)
m-dependent, where m = number
UNSTR | UN
Unstructured
USER(matrix) | FIXED(matrix)
Fixed, user-specified correlation matrix
For example, the following option specifies a fixed
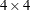 correlation matrix:
correlation matrix:
type=user( 1.0 0.9 0.8 0.6 0.9 1.0 0.9 0.8 0.8 0.9 1.0 0.9 0.6 0.8 0.9 1.0 )By default, TYPE=IND. When you specify the alternating logistic regression method using the option LOGOR= you should not specify TYPE=.
-
WITHINSUBJECT=within-subject-effect
WITHIN=within-subject-effect -
defines an effect that specifies the order of measurements within subjects. Each distinct level of the within-subject-effect defines a different response from the same subject. If the data are in proper order within each subject, you do not need to specify this option.
If some measurements do not appear in the data for some subjects, this option properly orders the existing measurements and treats the omitted measurements as missing values.
If you do not specify the WITHIN= option for the standard GEE method, missing values are assumed to be the last values and are not used; the remaining observations are then ordered in the sequence in which they are provided in the input data set. If you do not specify the WITHIN= option for the weighted GEE method, the observations are assumed to be ordered in the sequence in which they are provided in the input data set.
Variables that are used in defining the within-subject-effect must be listed in the CLASS statement.
- ZDATA=SAS-data-set
-
specifies a SAS data set that contains either the full
matrix for
log odds ratio association modeling for data with binary responses or the matrix for a single complete cluster to be replicated for all clusters.
- ZROW=variable-list
-
specifies the variables in the ZDATA= data set that correspond to rows of the
matrix for log odds ratio association modeling for data with binary responses.