| The CALIS Procedure |
| A Structural Equation Example |
This example from Wheaton et al. (1977) illustrates the basic uses of the CALIS procedure and the relationships among the LINEQS, LISMOD, PATH, and RAM modeling languages. Different structural models for these data are analyzed in Jöreskog and Sörbom (1985) and in (Bentler; 1995, p. 28). The data contain the following six (manifest) variables collected from 932 people in rural regions of Illinois:
- Anomie67:
Anomie 1967
- Powerless67:
Powerlessness 1967
- Anomie71:
Anomie 1971
- Powerless71:
Powerlessness 1971
- Education:
Education level (years of schooling)
- SEI:
Duncan’s socioeconomic index (SEI)
The covariance matrix of these six variables is stored in the data set named Wheaton.
It is assumed that anomie and powerlessness are indicators of an alienation factor and that education and SEI are indicators for a socioeconomic status (SES) factor. Hence, the analysis contains three latent variables (factors):
- Alien67:
Alienation 1967
- Alien71:
Alienation 1971
- SES:
Socioeconomic status (SES)
The following path diagram shows the structural model used in Bentler (1985, p. 29) and slightly modified in Jöreskog and Sörbom (1985, p. 56):
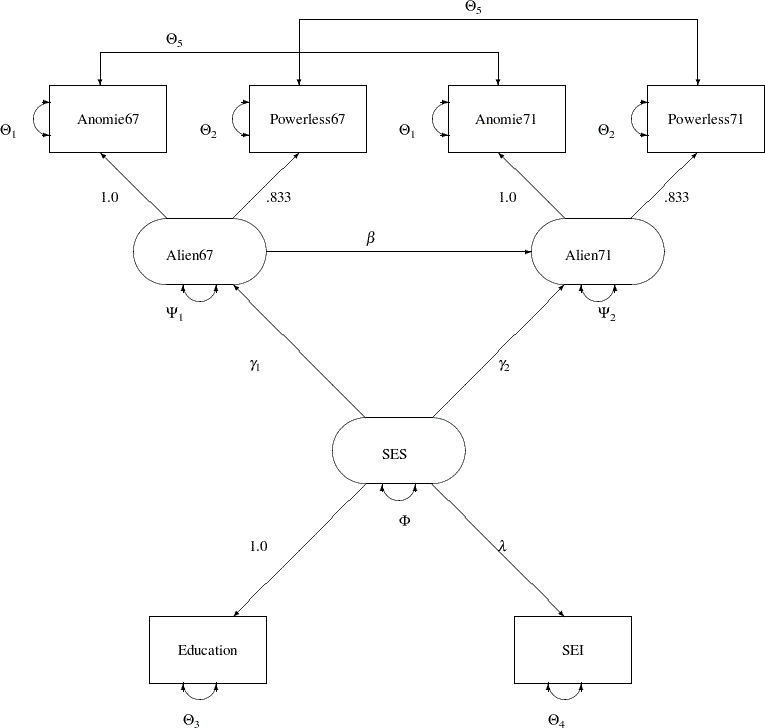
In the path diagram shown in Figure 25.1, regressions of variables are represented by one-headed arrows. Regression coefficients are indicated along these one-headed arrows. Variances and covariances among the variables are represented by two-headed arrows. Error variances and covariances are also represented by two-headed arrows. This scheme of representing paths, variances and covariances, and error variances and covariances (McArdle; 1988; McDonald; 1985) is helpful in translating the path diagram to the PATH or RAM model input in the CALIS procedure.
PATH Model
Specification by using the PATH modeling language is direct and intuitive in PROC CALIS once a path diagram is drawn. The following statements specify the path diagram almost intuitively:
proc calis nobs=932 data=Wheaton;
path
Anomie67 <--- Alien67 = 1.0,
Powerless67 <--- Alien67 = 0.833,
Anomie71 <--- Alien71 = 1.0,
Powerless71 <--- Alien71 = 0.833,
Education <--- SES = 1.0,
SEI <--- SES = lambda,
Alien67 <--- SES = gamma1,
Alien71 <--- SES = gamma2,
Alien71 <--- Alien67 = beta;
pvar
Anomie67 = theta1,
Powerless67 = theta2,
Anomie71 = theta1,
Powerless71 = theta2,
Education = theta3,
SEI = theta4,
Alien67 = psi1,
Alien71 = psi2,
SES = phi;
pcov
Anomie67 Anomie71 = theta5,
Powerless67 Powerless71 = theta5;
run;
In the PROC CALIS statement, you specify Wheaton as the input data set, which contains the covariance matrix of the variables.
In the PATH model specification, all the one-headed arrows in the path diagram are represented as path entries in the PATH statement, with entries separated by commas. In each path entry, you specify a pair of variables and the direction of the path (either <--- or --->), followed by a path coefficient, which is either a fixed constant or a parameter with a name in the specification.
All the two-headed arrows each with the same source and destination are represented as entries in the PVAR statement, with entries separated by commas. In the PVAR statement, you specify the variance or error (or partial) variance parameters. In each entry, you specify a variable and then a parameter name or a fixed parameter value. If the variable involved is exogenous in the model (serves only as a predictor; never being pointed at by one-headed arrows), you are specifying a variance parameter for an exogenous variable in the PVAR statement. Otherwise, you are specifying an error variance (or a partial variance) parameter for an endogenous variable.
All other two-headed arrows are represented as entries in the PCOV statement, with entries separated by commas. In the PCOV statement, you specify the covariance or error (or partial) covariance parameters. In each entry, you specify a pair of variables and then a parameter name or a fixed parameter value. If both variables involved in an entry are exogenous, you are specifying a covariance parameter. If both variables involved in an entry are endogenous, you are specifying an error (or partial) covariance parameter. When one variable is exogenous and the other is endogenous in an entry, you are specifying a partial covariance parameter that can be interpreted as the covariance between the exogenous variable and the error of the endogenous variable.
See Example 25.15 for the results of the current PATH model analysis. For more information about the PATH modeling language, see the section The PATH Model and the PATH statement.
RAM Model
The PATH modeling language is not the only specification method that you can use to represent the path diagram. You can also use the RAM, LINEQS or LISMOD modeling language to represent the diagram equivalently.
The RAM model specification in PROC CALIS resembles that of the PATH model, as shown in the following statements:
proc calis nobs=932 data=Wheaton;
ram
var = Anomie67 /* 1 */
Powerless67 /* 2 */
Anomie71 /* 3 */
Powerless71 /* 4 */
Education /* 5 */
SEI /* 6 */
Alien67 /* 7 */
Alien71 /* 8 */
SES, /* 9 */
_A_ 1 7 1.0,
_A_ 2 7 0.833,
_A_ 3 8 1.0,
_A_ 4 8 0.833,
_A_ 5 9 1.0,
_A_ 6 9 lambda,
_A_ 7 9 gamma1,
_A_ 8 9 gamma2,
_A_ 8 7 beta,
_P_ 1 1 theta1,
_P_ 2 2 theta2,
_P_ 3 3 theta1,
_P_ 4 4 theta2,
_P_ 5 5 theta3,
_P_ 6 6 theta4,
_P_ 7 7 psi1,
_P_ 8 8 psi2,
_P_ 9 9 phi,
_P_ 1 3 theta5,
_P_ 2 4 theta5;
run;
In the RAM statement, you specify a list of entries for parameters, with entries separated by commas. In each entry, you specify the type of parameter (PATH, PVAR, or PCOV in the code), the associated variable or pair of variables and the path direction if applicable, and then a parameter name or a fixed parameter value. The types of parameters you specify in this RAM model are for path coefficients, variances or partial variances, and covariances or partial covariances. They bear the same meanings as those in the PATH model specified previously. The RAM model specification is therefore quite similar to the PATH model specification—except that in the RAM model you put all parameter specification in the same list under the RAM statement, whereas you specify different types of parameters separately under different statements in the PATH model.
See Example 25.20 for partial results of the current RAM model analysis. For more information about the RAM modeling language, see the section The RAM Model and the RAM statement.
LINEQS Model
The LINEQS modeling language uses equations to specify functional relationships among variables, as shown in the following statements:
proc calis nobs=932 data=Wheaton;
lineqs
Anomie67 = 1.0 * f_Alien67 + E1,
Powerless67 = 0.833 * f_Alien67 + E2,
Anomie71 = 1.0 * f_Alien71 + E3,
Powerless71 = 0.833 * f_Alien71 + E4,
Education = 1.0 * f_SES + E5,
SEI = lambda * f_SES + E6,
f_Alien67 = gamma1 * f_SES + D1,
f_Alien71 = gamma2 * f_SES + beta * Alien67 + D2;
std
E1 = theta1,
E2 = theta2,
E3 = theta1,
E4 = theta2,
E5 = theta3,
E6 = theta4,
D1 = psi1,
D2 = psi2,
f_SES = phi;
cov
E1 E3 = theta5,
E2 E4 = theta5;
run;
In the LINEQS statement, equations are separated by commas. In each equation, you specify an endogenous variable on the left-hand side, and then predictors and path coefficients on the right-hand side of the equal side. The set of equations specified in this LINEQS model is equivalent to the system of paths specified in the preceding PATH (or RAM) model. However, there are some notable differences between the LINEQS and the PATH specifications.
First, in the LINEQS modeling language you must specify the error terms explicitly as exogenous variables. For example, E1, E2, and D1 are error terms in the specification. In the PATH (or RAM) modeling language, you do not need to specify error terms explicitly.
Second, equations specified in the LINEQS modeling language are oriented by the endogenous variables. Each endogenous variable can appear on the left-hand side of an equation only once in the LINEQS statement. All the corresponding predictor variables must then be specified on the right-hand side of the equation. For example, f_Alien71 is predicted from f_Alien67 and f_SES in the last equation of the LINEQS statement. In the PATH or RAM modeling language, however, you would specify the same functional relationships in two separate paths.
Third, you must follow some naming conventions for latent variables when using the LINEQS modeling language. The names of latent variables that are not errors or disturbances must start with an 'f' or 'F'. Also, the names of the error variables must start with 'e' or 'E' and the names of the disturbance variables must start with 'd' or 'D'. For example, variables Alien67, Alien71, and SES serve as latent factors in the previous PATH or RAM model specification. To comply with the naming conventions, these variables are named with an extra prefix 'f_' in the LINEQS model specification—that is, f_Alien67, f_Alien71, and f_SES, respectively. In addition, because of the naming conventions of the LINEQS modeling language, E1–E6 serve as error terms and D1–D1 serve as disturbances in the specification.
A consequence of explicit specification of error terms in the LINEQS statement is that the partial variance and partial covariance concepts used in the PATH and RAM modeling languages are no longer needed. They are replaced by the variances or covariances of the error terms or disturbances. Errors and disturbances are exogenous variables by nature. Hence, in terms of variance and covariance specification, they are treated exactly the same way as other non-error exogenous variables in the LINEQS modeling language. That is, variance parameters for all exogenous variables, including errors and disturbances, are specified in the VARIANCE statement, and covariance parameters among exogenous variables, including errors and disturbances, are specified in COV statement.
See Example 25.20 for partial results of the current LINEQS model analysis. For more information about the LINEQS modeling language, see the section The LINEQS Model and the LINEQS statement.
LISMOD Model
The LISMOD language is quite different from the LINEQS, PATH, and RAM modeling languages. In the LISMOD specification, you define parameters as entries in model matrices, as shown in the following statements:
proc calis nobs=932 data=Wheaton;
lismod
yvar = Anomie67 Powerless67 Anomie71 Powerless71,
xvar = Education SEI,
etav = Alien67 Alien71,
xiv = SES;
matrix _LAMBDAY_ [1,1] = 1.0,
[2,1] = 0.833,
[3,2] = 1.0,
[4,2] = 0.833;
matrix _LAMBDAX_ [1,1] = 1.0,
[2,1] = lambda;
matrix _GAMMA_ [1,1] = gamma1,
[2,1] = gamma2;
matrix _BETA_ [2,1] = beta;
matrix _THETAY_ [1,1] = theta1,
[2,2] = theta2,
[3,3] = theta1,
[4,4] = theta2,
[3,1] = theta5,
[4,2] = theta5;
matrix _THETAX_ [1,1] = theta3,
[2,2] = theta4;
matrix _PSI_ [1,1] = psi1,
[2,2] = psi2;
matrix _PHI_ [1,1] = phi;
run;
In the LISMOD statement, you specify the lists of variables in the model. In the MATRIX statements, you specify the parameters in the LISMOD model matrices. Each MATRIX statement contains the matrix name of interest and then locations of the parameters, followed by the parameter names or fixed parameter values. It would be difficult to explain the LISMOD specification here without better knowledge about the formulation of the mathematical model. For this purpose, see the section The LISMOD Model and Submodels and the LISMOD statement. See also Example 25.20 for partial results of the current LISMOD model analysis.
COSAN Model
The COSAN model specification is even more abstract than all of the modeling languages considered. Like the LISMOD model specification, to specify a COSAN model you need to define parameters as entries in model matrices. In addition, you must also provide the definitions of the model matrices and the matrix formula for the covariance structures in the COSAN model specification. Therefore, the COSAN model specification requires sophisticated knowledge about the formulation of the mathematical model. For this reason, the COSAN model specification of the preceding path model is not discussed here (but see Example 25.26). For more details about the COSAN model specification, see the section The COSAN Model and the COSAN statement.
Copyright © SAS Institute, Inc. All Rights Reserved.