| The CALIS Procedure |
| The RAM Model |
The RAM modeling language is adapted from the basic RAM model developed by McArdle (1980). For brevity, models specified by the RAM modeling language are called RAM models. You can also specify these so-called RAM models by other general modeling languages that are supported in PROC CALIS.
Types of Variables in the RAM Model
A variable in the RAM model is manifest if it is observed and is defined in the input data set. A variable in the RAM model is latent if it is not manifest. Because error variables are not explicitly named in the RAM model, all latent variables in the RAM model are considered as factors (non-error-type latent variables).
A variable in the RAM model is endogenous if it ever serves as an outcome variable in the RAM model. That is, an endogenous variable has at least one path (or an effect) from another variable in the model. A variable is exogenous if it is not endogenous. Endogenous variables are also referred to as dependent variables, while exogenous variables are also referred to as independent variables.
In the RAM model, distinctions between exogenous and endogenous and between latent and manifest for variables are not essential to the definitions of model matrices, although they are useful for conceptual understanding when the model matrices are partitioned.
Naming Variables in the RAM Model
Manifest variables in the RAM model are referenced in the input data set. Their names must not be longer than 32 characters. There are no further restrictions beyond those required by the SAS System.
Latent variables in the RAM model are those not being referenced in the input data set. Their names must not be longer than 32 characters. Unlike the LINEQS model, you do not need to use any specific prefix (for example, 'F' or 'f') for the latent factor names. The reason is that error or disturbance variables in the RAM model are not named explicitly in the RAM model. Thus, any variable names that are not referenced in the input data set are for latent factors.
As a general naming convention, you should not use Intercept as either a manifest or latent variable name.
Model Matrices in the RAM Model
In terms of the number of model matrices involved, the RAM model is the simplest among all the general structural equations models that are supported by PROC CALIS. Essentially, there are only three model matrices in the RAM model: one for the interrelationships among variables, one for the variances and covariances, and one for the means and intercepts. These matrices are discussed in the following subsections.
Matrix  (
( ) : Effects of Column Variables on Row Variables
) : Effects of Column Variables on Row Variables
The row and column variables of matrix are the set of manifest and latent variables in the RAM model. Unlike the LINEQS model, the set of latent variables in the RAM model matrix does not include the error or disturbance variables. Each entry or element in the matrix represents an effect of the associated column variable on the associated row variable or a path coefficient from the associated column variable to the associated row variable. A zero entry means an absence of a path or an effect.
The pattern of matrix determines whether a variable is endogenous or exogenous. A variable in the RAM model is endogenous if its associated row in the matrix has at least one nonzero entry. Any other variable in the RAM model is exogenous.
Mathematically, you do not need to arrange the set of variables for matrix in a particular order, as long as the order of variables is the same for the rows and the columns. However, arranging the variables according to whether they are endogenous or exogenous is useful for showing the partitions of the model matrices and certain mathematical properties. See the section Partitions of the RAM Model Matrices and Some Restrictions for details.
Matrix 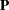 (): Variances, Covariances, Partial Variances, and Partial Covariances
(): Variances, Covariances, Partial Variances, and Partial Covariances
The row and column variables of matrix refer to the same set of manifest and latent variables that are defined in the RAM model matrix . The diagonal entries of contain variances or partial variances of variables. If a variable is exogenous, then the corresponding diagonal element in the matrix represents its variance. Otherwise, the corresponding diagonal element in the matrix represents its partial variance. This partial variance is an unsystematic source of variance that is not explained by the interrelationships of variables in the model. In most cases, you can interpret a partial variance as the error variance for an endogenous variable.
The off-diagonal elements of contain covariances or partial covariances among variables. An off-diagonal element in that is associated with exogenous row and column variables represents covariance between the two exogenous variables. An off-diagonal element in that is associated with endogenous row and column variables represents partial covariance between the two variables. This partial covariance is unsystematic, in the sense that it is not explained by the interrelationships of variables in the model. In most cases, you can interpret a partial covariance as the error covariance between the two endogenous variables involved. An off-diagonal element in that is associated with one exogenous variable and one endogenous variable in the row and column represents the covariance between the exogenous variable and the error of the endogenous variable. While this interpretation sounds a little awkward and inelegant, this kind of covariance, fortunately, is rare in most applications.
Vector 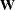 (
( ): Intercepts and Means
): Intercepts and Means
The row variables of vector refer to the same set of manifest and latent variables that are defined in the RAM model matrix . Elements in represent either intercepts or means. An element in that is associated with an exogenous row variable represents the mean of the variable. An element in that is associated with an endogenous row variable represents the intercept term for the variable.
Covariance and Mean Structures
Assuming that  is invertible, where
is invertible, where  is an identity matrix of the same dimension as , the structured covariance matrix of all variables (including latent variables) in the RAM model is shown as follows:
is an identity matrix of the same dimension as , the structured covariance matrix of all variables (including latent variables) in the RAM model is shown as follows:
 |
The structured mean vector of all variables is shown as follows:
 |
The covariance and mean structures of all manifest variables are obtained by selecting the elements in 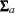 and
and 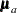 . This can be achieved by defining a selection matrix
. This can be achieved by defining a selection matrix  of dimensions
of dimensions 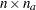 , where
, where  is the number of manifest variables in the model. The selection matrix contains zeros and ones as its elements. Each row of has exactly one nonzero element at the position that corresponds to the location of a manifest row variable in or . With each row of selecting a distinct manifest variable, the structured covariance matrix of all manifest variables is expressed as the following:
is the number of manifest variables in the model. The selection matrix contains zeros and ones as its elements. Each row of has exactly one nonzero element at the position that corresponds to the location of a manifest row variable in or . With each row of selecting a distinct manifest variable, the structured covariance matrix of all manifest variables is expressed as the following:
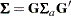 |
The structured mean vector of all observed variables is expressed as the following:
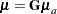 |
Partitions of the RAM Model Matrices and Some Restrictions
There are some model restrictions in the RAM model matrices. Although these restrictions do not affect the derivation of the covariance and mean structures, they are enforced in the RAM model specification.
For convenience, it is useful to assume that 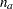 variables are arranged in the order of
variables are arranged in the order of 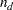 endogenous (or dependent) variables and the
endogenous (or dependent) variables and the  exogenous (independent) variables in the rows and columns of the model matrices.
exogenous (independent) variables in the rows and columns of the model matrices.
Model Restrictions on the Matrix
The matrix is partitioned as
 |
where 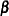 is an
is an 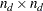 matrix for paths or effects from (column) endogenous variables to (row) endogenous variables and
matrix for paths or effects from (column) endogenous variables to (row) endogenous variables and 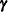 is an
is an 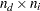 matrix for paths (effects) from (column) exogenous variables to (row) endogenous variables.
matrix for paths (effects) from (column) exogenous variables to (row) endogenous variables.
As shown in the matrix partitions, there are four submatrices. The two submatrices at the lower parts are seemingly structured to zeros. However, this should not be interpreted as restrictions imposed by the model. The zero submatrices are artifacts created by the exogenous-endogenous arrangement of the row and column variables. The only restriction on the matrix is that the diagonal elements must all be zeros. This implies that the diagonal elements of the submatrix are also zeros. This restriction prevents a direct path from any endogenous variable to itself. There are no restrictions on the pattern of .
It is useful to denote the lower partitions of the matrix by  (lower left) and
(lower left) and  (lower right) so that
(lower right) so that
 |
Although they are zero matrices in the initial model specification, their entries could become non-zero (paths) in an improved model when you modify your model by using the Lagrange multiplier statistics (see the section Modification Indices or the MODIFICATION option). Hence, you might need to reference these two submatrices when you apply the customized LM tests on them during the model modification process (see the LMTESTS statement).
For the purposes of defining specific parameter regions in customized LM tests, you might also partition the matrix in other ways. First, you can partition into the left and right portions,
 |
where 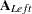 is top-down concatenation of the and matrices and
is top-down concatenation of the and matrices and 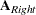 is the top-down concatenation of the and matrices. Second, you can partition into the upper and lower portions,
is the top-down concatenation of the and matrices. Second, you can partition into the upper and lower portions,
 |
where  is the side-by-side concatenation of the and matrices and
is the side-by-side concatenation of the and matrices and  is the side-by-side concatenation of the and matrices.
is the side-by-side concatenation of the and matrices.
In your initial model, because of the arrangement of the endogenous and exogenous variables is a null matrix. But if you improve your model by applying the LM tests on the entries in , some of these entries might become free paths in your improved model. Hence, some exogenous variables in your initial model now become endogenous variables in your improved model. For this reason, is also designated as a parameter region for new endogenous variables, which is exactly what the NEWENDO region means in the LMTESTS statement.
Partition of the Matrix
The matrix is partitioned as
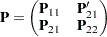 |
where 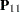 is an partial covariance matrix for the endogenous variables,
is an partial covariance matrix for the endogenous variables,  is an
is an 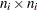 covariance matrix for the exogenous variables, and
covariance matrix for the exogenous variables, and  is an
is an 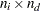 covariance matrix between the exogenous variables and the error terms for the endogenous variables. Because is symmetric, and are also symmetric.
covariance matrix between the exogenous variables and the error terms for the endogenous variables. Because is symmetric, and are also symmetric.
There are virtually no model restrictions placed on these submatrices. However, in most statistical applications, errors for endogenous variables represent unsystematic sources of effects and therefore they are not to be correlated with other systematic sources such as the exogenous variables in the RAM model. This means that in most practical applications would be a null matrix, although this is not enforced in PROC CALIS.
Partition of the Vector
The vector is partitioned as
 |
where  is an
is an 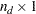 vector for intercepts of the endogenous variables and
vector for intercepts of the endogenous variables and  is an
is an 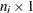 vector for the means of the exogenous variables. There is no model restriction on these subvectors.
vector for the means of the exogenous variables. There is no model restriction on these subvectors.
Summary of Matrices and Submatrices in the RAM Model
Let be the total number of manifest and latent variables in the RAM model. Of these variables, are endogenous and are exogenous. Suppose that the rows and columns of the RAM model matrices and and the rows of are arranged in the order of endogenous variables and then exogenous variables. The names, roles, and dimensions of the RAM model matrices and submatrices are summarized in the following table.
Matrix |
Name |
Description |
Dimensions |
|---|---|---|---|
Model Matrices |
|||
|
_A_ or _RAMA_ |
Effects of column variables on row variables, or paths from the column variables to the row variables |
|
|
_P_ or _RAMP_ |
(Partial) variances and covariances |
|
|
_W_ or _RAMW_ |
Intercepts and means |
|
Submatrices |
|||
|
_RAMBETA_ |
Effects of endogenous variables on endogenous variables |
|
|
_RAMGAMMA_ |
Effects of exogenous variables on endogenous variables |
|
|
_RAMA_LL_ |
The null submatrix at the lower left portion of _A_ |
|
|
_RAMA_LR_ |
The null submatrix at the lower right portion of _A_ |
|
|
_RAMA_LEFT_ |
The left portion of _A_, including |
|
|
_RAMA_RIGHT_ |
The right portion of _A_, including |
|
|
_RAMA_UPPER_ |
The upper portion of _A_, including |
|
|
_RAMA_LOWER_ |
The lower portion of _A_, including |
|
|
_RAMP11_ |
Error variances and covariances for endogenous variables |
|
|
_RAMP21_ |
Covariances between exogenous variables and error terms for endogenous variables |
|
|
_RAMP22_ |
Variances and covariances for exogenous variables |
|
|
_RAMALPHA_ |
Intercepts for endogenous variables |
|
|
_RAMNU_ |
Means for exogenous variables |
|


Specification of the RAM Model
In PROC CALIS, the RAM model specification is a matrix-oriented modeling language. That is, you have to define the row and column variables for the model matrices and specify the parameters in terms of matrix entries. The VAR= option specifies the variables (including manifest and latent) in the model. For example, the following statement specifies five variables in the model:
RAM var= v1 v2 v3;
The order of variables in the VAR= option is important. The same order is used for the row and column variables in the model matrices. After you specify the variables in the model, you can specify three types of parameters, which correspond to the elements in the three model matrices. The three types of RAM entries are described in the following.
(1) Specification of Effects or Paths in Model Matrix
If there is a path from V2 to V1 in your model and the associated effect parameter is named parm1 with 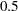 as the starting value, you can use the following RAM statement:
as the starting value, you can use the following RAM statement:
RAM var= v1 v2 v3, _A_ 1 2 parm1(0.5);
The ram-entry that starts with _A_ means that an element of the ram matrix is being specified. The row number and the column number of this element are 1 and 2, respectively. With reference to the VAR= list, the row number 1 refers to variable v1, and the column number 2 refers to variable v2. Therefore, the effect of V2 on V1 is a parameter named parm1, with an initial value of 0.5.
You can specify fixed values in the ram-entries too. Suppose the effect of v3 on v1 is fixed at 1.0. You can use the following specification:
RAM var= v1 v2 v3, _A_ 1 2 parm1(0.5), _A_ 1 3 1.0;
(2) Specification of the Latent Factors in the Model
In the RAM model, you specify the list of variables in VAR= list of the RAM statement. The list of variables can include the latent variables in the model. Because observed variables have references in the input data sets, those variables that do not have references in the data sets are treated as latent factors automatically. Unlike the LINEQS model, you do not need to use 'F' or 'f' prefix to denote latent factors in the RAM model. It is recommended that you use meaningful names for the latent factors. See the section Naming Variables and Parameters for the general rules about naming variables and parameters.
For example, suppose that SES_Factor and Education_Factor are names that are not used as variable names in the input data set. These two names represent two latent factors in the model, as shown in the following specification:
RAM var= v1 v2 v3 SES_FACTOR Education_Factor, _A_ 1 4 b1, _A_ 2 5 b2, _A_ 3 5 1.0;
This specification shows that the effect of SES_Factor on v1 is a free parameter named b1, and the effects of Education_Factor on v2 and v3 are a free parameter named b2 and a fixed value of 1.0, respectively.
However, naming latent factors is not compulsory. The preceding specification is equivalent to the following specification:
RAM var= v1 v2 v3, _A_ 1 4 b1, _A_ 2 5 b2, _A_ 3 5 1.0;
Although you do not name the fourth and the fifth variables in the VAR= list, PROC CALIS generates the names for these two latent variables. In this case, the fourth variable is named _Factor1 and the fifth variable is named _Factor2.
(3) Specification of (Partial) Variances and (Partial) Covariances in Model Matrix
Suppose now you want to specify the variance of v2 as a free parameter named parm2. You can add a new ram-entry for this variance parameter, as shown in the following statement:
RAM var= v1 v2 v3, _A_ 1 2 parm1(0.5), _A_ 1 3 1.0, _P_ 2 2 parm2;
The ram-entry that starts with _P_ means that an element of the RAM matrix is being specified. The (2,2) element of , which is the variance of v2, is a parameter named parm2. You do not specify an initial value for this parameter.
You can also specify the error variance of v1 similarly, as shown in the following statement:
RAM var= v1 v2 v3, _A_ 1 2 parm1(0.5), _A_ 1 3 1.0, _P_ 2 2 parm2, _P_ 1 1;
In the last ram-entry, the (1,1) element of , which is the error variance of v1, is an unnamed free parameter.
Covariance parameters are specified in the same manner. For example, the following specification adds a ram-entry for the covariance parameter between v2 and v3:
RAM var= v1 v2 v3, _A_ 1 2 parm1(0.5), _A_ 1 3 1.0, _P_ 2 2 parm2, _P_ 1 1, _P_ 2 3 (.5);
The covariance between v2 and v3 is an unnamed parameter with an initial value of 0.5.
(4) Specification of Means and Intercepts in Model Matrix _W_
To specifying means or intercepts, you need to start the ram-entries with the _W_ keyword. For example, the last two entries of following statement specify the intercept of v1 and the mean of v2, respectively:
RAM var= v1 v2 v3, _A_ 1 2 parm1(0.5), _A_ 1 3 1.0, _P_ 2 2 parm2, _P_ 1 1 , _P_ 2 3 (.5), _W_ 1 1 int_v1, _W_ 2 2 mean_v2;
The intercept of v1 is a free parameter named int_v1, and the mean of v2 is a free parameter named mean_v2.
Default Parameters in the RAM Model
There are two types of default of parameters of the RAM model in PROC CALIS. One is the free parameters; the other is the fixed zeros.
By default, certain sets of model matrix elements in the RAM model are free parameters. These parameters are set automatically by PROC CALIS, although you can also specify them explicitly in the ram-entries. In general, default free parameters enable you to specify only what are absolutely necessary for defining your model. PROC CALIS automatically sets those commonly assumed free parameters so that you do not need to specify them routinely. The sets of default free parameters of the RAM model are as follows:
Diagonal elements of the _P_ matrix—this includes the variance of exogenous variables (latent or observed) and error variances of all endogenous variables (latent or observed)
The off-diagonal elements that pertain to the exogenous variables of the _P_ matrix—this includes all the covariances among exogenous variables, latent or observed
If the mean structures are modeled, the elements that pertain to the observed variables (but not the latent variables) in the _W_ vector— this includes all the means of exogenous observed variables and the intercepts of all endogenous observed variables
For example, suppose you are fitting a RAM model with three observed variables x1, x2, and y3, you specify a simple multiple-regression model with x1 and x2 predicting y3 by the following statements:
proc calis meanstr;
ram var= x1-x2 y3,
_A_ 3 1 ,
_A_ 3 2 ;
In the RAM statement, you specify that path coefficients represented by _A_[3,1] and _A_[3,2] are free parameters in the model. In addition to these free parameters, PROC CALIS sets several other free parameters by default. _P_[1,1], _P_[2,2], and _P_[3,3] are set as free parameters for the variance of x1, the variance of x2, and the error variance of x3, respectively. _P_[2,1] (and hence _P_[1,2]) is set as a free parameter for the covariance between the exogenous variables x1 and x2. Because the mean structures are also analyzed by the MEANSTR option in the PROC CALIS statement, _W_[1,1], _W_[2,1], and _W_[3,1] are also set as free parameters for the mean of x1, the mean of x2, and the intercept of x3, respectively. In the current situation, this default parameterization is consistent with using PROC REG for multiple regression analysis, where you only need to specify the functional relationships among variables.
If a matrix element is not a default free parameter in the RAM model, then it is a fixed zero by default. You can override almost all default fixed zeros in the RAM model matrices by specifying the ram-entries. The diagonal elements of the _A_ matrix are exceptions. These elements are always fixed zeros. You cannot set these elements to free parameters or other fixed values—this reflects a model restriction that prevents a variable from having a direct effect on itself.
Copyright © SAS Institute, Inc. All Rights Reserved.