The HPGENSELECT Procedure

MODEL response <(response-options)> = <effects> </ model-options> ;
MODEL events / trials = <effects> </ model-options> ;
The MODEL statement defines the statistical model in terms of a response variable (the target) or an events/trials specification. You can also specify model effects that are constructed from variables in the input data set, and you can specify options. An intercept is included in the model by default. You can remove the intercept by specifying the NOINT option.
You can specify a single response variable that contains your interval, binary, ordinal, or nominal response values. When you have binomial data, you can specify the events/trials form of the response, where one variable contains the number of positive responses (or events) and another variable contains the number of trials. The values of both events and (trials – events) must be nonnegative, and the value of trials must be positive. If you specify a single response variable that is in a CLASS statement, then the response is assumed to be either binary or multinomial, depending on the number of levels.
For information about constructing the model effects, see the section Specification and Parameterization of Model Effects of Chapter 4: Shared Statistical Concepts.
There are two sets of options in the MODEL statement. The response-options determine how the HPGENSELECT procedure models probabilities for binary and multinomial data. The model-options control other aspects of model formation and inference. Table 7.3 summarizes these options.
Table 7.3: MODEL Statement Options
|
Option |
Description |
|---|---|
|
Response Variable Options for Binary and Multinomial Models |
|
|
Reverses the response categories |
|
|
Specifies the event category |
|
|
Specifies the sort order |
|
|
Specifies the reference category |
|
|
Model Options |
|
|
Specifies the confidence level for confidence limits |
|
|
Requests confidence limits |
|
|
Specifies a fixed dispersion parameter |
|
|
Specifies the response distribution |
|
|
Includes effects in all models for model selection |
|
|
Specifies a starting value of the dispersion parameter |
|
|
Specifies the link function |
|
|
Requests that continuous main effects not be centered and scaled |
|
|
Suppresses the intercept |
|
|
Specifies the offset variable |
|
|
Specifies the fraction of the data to be used to compute starting |
|
|
values for the Tweedie distribution |
|
|
Includes effects in the initial model for model selection |
|
Response variable options determine how the HPGENSELECT procedure models probabilities for binary and multinomial data.
You can specify the following response-options by enclosing them in parentheses after the response or trials variable.
- ALPHA=number
-
requests that confidence intervals for each of the parameters that are requested by the CL option be constructed with confidence level 1–number. The value of number must be between 0 and 1; the default is 0.05.
- CL
-
requests that confidence limits be constructed for each of the parameter estimates. The confidence level is 0.95 by default; this can be changed by specifying the ALPHA= option.
- DISPERSION=number
-
specifies a fixed dispersion parameter for those distributions that have a dispersion parameter. The dispersion parameter used in all computations is fixed at number, and not estimated.
- DISTRIBUTION=keyword
-
specifies the response distribution for the model. The keywords and the associated distributions are shown in Table 7.5.
Table 7.5: Built-In Distribution Functions
Distribution
DISTRIBUTION=
Function
BINARY
Binary
BINOMIAL
Binary or binomial
GAMMA
Gamma
INVERSEGAUSSIAN | IG
Inverse Gaussian
MULTINOMIAL | MULT
Multinomial
NEGATIVEBINOMIAL | NB
Negative binomial
NORMAL | GAUSSIAN
Normal
POISSON
Poisson
TWEEDIE<(Tweedie-options)>
Tweedie
ZINB
Zero-inflated negative binomial
ZIP
Zero-inflated Poisson
When DISTRIBUTION=TWEEDIE, you can specify the following Tweedie-options:
If you do not specify a link function with the LINK= option, a default link function is used. The default link function for each distribution is shown in Table 7.6. For the binary and multinomial distributions, only the link functions shown in Table 7.6 are available. For the other distributions, you can use any link function shown in Table 7.7 by specifying the LINK= option. Other commonly used link functions for each distribution are shown in Table 7.6.
Table 7.6: Default and Commonly Used Link Functions
Default
Other Commonly Used
DISTRIBUTION=
Link Function
Link Functions
BINARY
Logit
Probit, complementary log-log, log-log
BINOMIAL
Logit
Probit, complementary log-log, log-log
GAMMA
Reciprocal
Log
INVERSEGAUSSIAN | IG
Reciprocal square
Log
MULTINOMIAL | MULT
Logit (ordinal)
Probit, complementary log-log, log-log
MULTINOMIAL | MULT
Generalized logit (nominal)
NEGATIVEBINOMIAL | NB
Log
NORMAL | GAUSSIAN
Identity
Log
POISSON
Log
TWEEDIE
Log
ZINB
Log
ZIP
Log
-
INCLUDE=n
INCLUDE=single-effect
INCLUDE=(effects) -
forces effects to be included in all models. If you specify INCLUDE=n, then the first n effects that are listed in the MODEL statement are included in all models. If you specify INCLUDE=single-effect or if you specify a list of effects within parentheses, then the specified effects are forced into all models. The effects that you specify in this option must be explanatory effects that are specified in the MODEL statement before the slash (/).
- INITIAL-PHI=number
-
specifies a starting value for iterative maximum likelihood estimation of the dispersion parameter for distributions that have a dispersion parameter.
- LINK=keyword
-
specifies the link function for the model. The keywords and the associated link functions are shown in Table 7.7. Default and commonly used link functions for the available distributions are shown in Table 7.6.
Table 7.7: Built-In Link Functions
Link
LINK=
Function
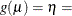
CLOGLOG | CLL
Complementary log-log
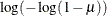
GLOGIT | GENLOGIT
Generalized logit
IDENTITY | ID
Identity
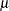
INV | RECIP
Reciprocal
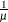
INV2
Reciprocal square
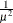
LOG
Logarithm
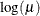
LOGIT
Logit
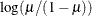
LOGLOG
Log-log
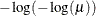
PROBIT
Probit
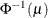
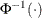 denotes the quantile function of the standard normal distribution.
denotes the quantile function of the standard normal distribution.
If a multinomial response variable has more than two categories, the HPGENSELECT procedure fits a model by using a cumulative link function that is based on the specified link. However, if you specify LINK=GLOGIT, the procedure assumes a generalized logit model for nominal (unordered) data, regardless of the number of response categories.
- NOCENTER
-
requests that continuous main effects not be centered and scaled internally. (Continuous main effects are centered and scaled by default to aid in computing maximum likelihood estimates.) Parameter estimates and related statistics are always reported on the original scale.
- NOINT
-
requests that no intercept be included in the model. (An intercept is included by default.) The NOINT option is not available in multinomial models.
- OFFSET=variable
-
specifies a variable to be used as an offset to the linear predictor. An offset plays the role of an effect whose coefficient is known to be 1. The offset variable cannot appear in the CLASS statement or elsewhere in the MODEL statement. Observations that have missing values for the offset variable are excluded from the analysis.
- SAMPLEFRAC=number
-
specifies a fraction of the data to be used to determine starting values for iterative estimation of the parameters of a Tweedie model. The sampled data are used in an extended quasi-likelihood estimation of the model parameters. The estimated parameters are then used as starting values in a full maximum likelihood estimation of the model parameters that uses all of the data.
-
START=n
START=single-effect
START=(effects) -
begins the selection process from the designated initial model for the FORWARD and STEPWISE selection methods. If you specify START=n, then the starting model includes the first n effects that are listed in the MODEL statement. If you specify START=single-effect or if you specify a list of effects within parentheses, then the starting model includes those specified effects. The effects that you specify in the START= option must be explanatory effects that are specified in the MODEL statement before the slash (/). The START= option is not available when you specify METHOD=BACKWARD in the SELECTION statement.