The HPGENSELECT Procedure

- Performance Information
- Model Information
- Class Level Information
- Number of Observations
- Response Profile
- Entry and Removal Candidates
- Selection Information
- Selection Summary
- Selection Details
- Stop Reason
- Selection Reason
- Selected Effects
- Iteration History
- Convergence Status
- Dimensions
- Optimization Stage Details
- Fit Statistics
- Parameter Estimates
- Parameter Estimates Correlation Matrix
- Parameter Estimates Covariance Matrix
- Zero-Inflation Parameter Estimates
The following sections describe the output that PROC HPGENSELECT produces by default. The output is organized into various tables, which are discussed in the order of their appearance.
The “Performance Information” table is produced by default. It displays information about the execution mode. For single-machine mode, the table displays the number of threads used. For distributed mode, the table displays the grid mode (symmetric or asymmetric), the number of compute nodes, and the number of threads per node.
If you specify the DETAILS option in the PERFORMANCE statement, the procedure also produces a “Timing” table in which elapsed times (absolute and relative) for the main tasks of the procedure are displayed.
The “Model Information” table displays basic information about the model, such as the response variable, frequency variable, link function, and the model category that the HPGENSELECT procedure determined based on your input and options. The “Model Information” table also displays the distribution of the data that is assumed by the HPGENSELECT procedure. For information about how the procedure determines the response distribution, see the section Response Distributions.
The “Class Level Information” table lists the levels of every variable that is specified in the CLASS statement. You should check this information to make sure that the data are correct. You can adjust the order of the CLASS variable levels by specifying the ORDER= option in the CLASS statement. You can suppress the “Class Level Information” table completely or partially by specifying the NOCLPRINT= option in the PROC HPGENSELECT statement.
If the classification variables use reference parameterization, the “Class Level Information” table also displays the reference value for each variable.
The “Number of Observations” table displays the number of observations that are read from the input data set and the number of observations that are used in the analysis. If a FREQ statement is present, the sum of the frequencies read and used is displayed. If the events/trials syntax is used, the number of events and trials is also displayed.
The “Response Profile” table displays the ordered value from which the HPGENSELECT procedure determines the probability being modeled as an event in binary models and the ordering of categories in multinomial models. For each response category level, the frequency that is used in the analysis is reported. You can affect the ordering of the response values by specifying response-options in the MODEL statement. For binary and generalized logit models, the note that follows the “Response Profile” table indicates which outcome is modeled as the event in binary models and which value serves as the reference category.
The “Response Profile” table is not produced for binomial data. You can find information about the number of events and trials in the “Number of Observations” table.
When you specify the DETAILS=ALL or DETAILS=STEPS option in the SELECTION statement, the HPGENSELECT procedure produces “Entry Candidates” and “Removal Candidates” tables that display the effect names and the values of the criterion that is used to select entering or departing effects at each step of the selection process. The effects are displayed in sorted order from best to worst of the selection criterion.
When you specify the SELECTION statement, the HPGENSELECT procedure produces by default a series of tables that have information about the model selection. The “Selection Information” table informs you about the model selection method, selection and stop criteria, and other parameters that govern the selection. You can suppress this table by specifying DETAILS=NONE in the SELECTION statement.
When you specify the SELECTION statement, the HPGENSELECT procedure produces the “Selection Summary” table, which contains information about which effects were entered into or removed from the model at the steps of the model selection process. The p-value for the score chi-square test that led to the removal or entry decision is also displayed. You can request further details about the model selection steps by specifying DETAILS=STEPS or DETAILS=ALL in the SELECTION statement. You can suppress the display of the “Selection Summary” table by specifying DETAILS=NONE in the SELECTION statement.
When you specify the DETAILS=ALL option in the SELECTION statement, the HPGENSELECT procedure produces the “Selection Details” table, which contains information about which effects were entered into or removed from the model at the steps of the model selection process. The p-value and the chi-square test statistic that led to the removal or entry decision are also displayed. Fit statistics for the model at the steps are also displayed.
When you specify the SELECTION statement, the HPGENSELECT procedure produces a simple table that tells you why model selection stopped.
When you specify the SELECTION statement, the HPGENSELECT procedure produces a simple table that tells you why the final model was selected.
When you specify the SELECTION statement, the HPGENSELECT procedure produces a simple table that tells you which effects were selected to be included in the final model.
For each iteration of the optimization, the “Iteration History” table displays the number of function evaluations (including gradient and Hessian evaluations), the value of the objective function, the change in the objective function from the previous iteration, and the absolute value of the largest (projected) gradient element. The objective function used in the optimization in the HPGENSELECT procedure is normalized by default to enable comparisons across data sets that have different sampling intensity. You can control normalization by specifying the NORMALIZE= option in the PROC HPGENSELECT statement.
If you specify the ITDETAILS option in the PROC HPGENSELECT statement, information about the parameter estimates and gradients in the course of the optimization is added to the “Iteration History” table. To generate the history from a model selection process, specify the ITSELECT option.
The convergence status table is a small ODS table that follows the “Iteration History” table in the default output. In the listing it appears as a message that indicates whether the optimization succeeded and
which convergence criterion was met. If the optimization fails, the message indicates the reason for the failure. If you save
the convergence status table to an output data set, a numeric Status variable is added that enables you to programmatically assess convergence. The values of the Status variable encode the following:
- 0
-
Convergence was achieved, or an optimization was not performed because TECHNIQUE=NONE is specified.
- 1
-
The objective function could not be improved.
- 2
-
Convergence was not achieved because of a user interrupt or because a limit (such as the maximum number of iterations or the maximum number of function evaluations) was reached. To modify these limits, see the MAXITER=, MAXFUNC=, and MAXTIME= options in the PROC HPGENSELECT statement.
- 3
-
Optimization failed to converge because function or derivative evaluations failed at the starting values or during the iterations or because a feasible point that satisfies the parameter constraints could not be found in the parameter space.
The “Dimensions” table displays size measures that are derived from the model and the environment. It displays the number of effects in the model, the number of columns in the design matrix, and the number of parameters for which maximum likelihood estimates are computed.
The “Optimization Stage Details” table displays the optimization stages that are used to fit Tweedie models. The type of optimization, the percentage of observations used, and the number of observations used are displayed for each stage.
The “Fit Statistics” table displays a variety of likelihood-based measures of fit. All statistics are presented in “smaller is better” form.
The calculation of the information criteria uses the following formulas, where ![]() denotes the number of effective parameters,
denotes the number of effective parameters, ![]() denotes the number of frequencies used, and
denotes the number of frequencies used, and ![]() is the log likelihood evaluated at the converged estimates:
is the log likelihood evaluated at the converged estimates:
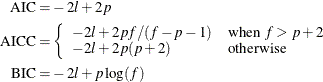
If no FREQ statement is given, ![]() equals
equals ![]() , the number of observations used.
, the number of observations used.
The values displayed in the “Fit Statistics” table are not based on a normalized log-likelihood function.
The “Parameter Estimates” table displays the parameter estimates, their estimated (asymptotic) standard errors, chi-square statistics, and p-values for the hypothesis that the parameter is 0.
If you request confidence intervals by specifying the CL option in the MODEL statement, confidence limits for regression parameters are produced for the estimate on the linear scale. Confidence limits for the dispersion parameter of those distributions that possess a dispersion parameter are produced on the log scale, because the dispersion must be greater than 0. Similarly, confidence limits for the power parameter of the Tweedie distribution are produced on the log scale.
When you specify the CORR option in the PROC HPGENSELECT statement, the correlation matrix of the parameter estimates is displayed.
When you specify the COV option in the PROC HPGENSELECT statement, the covariance matrix of the parameter estimates is displayed. The covariance matrix is computed as the inverse of the negative of the matrix of second derivatives of the log-likelihood function with respect to the model parameters (the Hessian matrix), evaluated at the parameter estimates.
The parameter estimates for zero-inflation probability in zero-inflated models, their estimated (asymptotic) standard errors, chi-square statistics, and p-values for the hypothesis that the parameter is 0 are presented in the “Parameter Estimates” table. If you request confidence intervals by specifying the CL option in the MODEL statement, confidence limits for regression parameters are produced for the estimate on the linear scale.