The Nonlinear Programming Solver
- Overview
-
Getting Started

-
Syntax
-
Details
-
ExamplesSolving Highly Nonlinear Optimization ProblemsSolving Unconstrained and Bound-Constrained Optimization ProblemsSolving NLP Problems with Range ConstraintsSolving Large-Scale NLP ProblemsSolving NLP Problems That Have Several Local MinimaMaximum Likelihood Weibull EstimationFinding an Irreducible Infeasible Set
- References
Basic Definitions and Notation
The gradient of a function 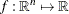 is the vector of all the first partial derivatives of f and is denoted by
is the vector of all the first partial derivatives of f and is denoted by
![\[ \nabla f(x) = \left(\frac{\partial f}{\partial x_{1}}, \frac{\partial f}{\partial x_{2}}, \ldots , \frac{\partial f}{\partial x_{n}} \right)^\mr {T} \]](images/ormpug_nlpsolver0047.png)
where the superscript T denotes the transpose of a vector.
The Hessian matrix of f, denoted by 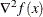 , or simply by
, or simply by 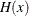 , is an
, is an 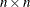 symmetric matrix whose
symmetric matrix whose 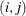 element is the second partial derivative of
element is the second partial derivative of 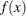 with respect to
with respect to 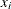 and
and 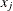 . That is,
. That is, 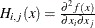 .
.
Consider the vector function, 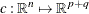 , whose first p elements are the equality constraint functions
, whose first p elements are the equality constraint functions 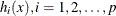 , and whose last q elements are the inequality constraint functions
, and whose last q elements are the inequality constraint functions 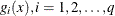 . That is,
. That is,
![\[ c(x) = (h(x) : g(x))^\mr {T} = (h_{1}(x), \ldots , h_{p}(x) : g_{1}(x), \ldots , g_{q}(x))^\mr {T} \]](images/ormpug_nlpsolver0059.png)
The 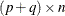 matrix whose ith row is the gradient of the ith element of
matrix whose ith row is the gradient of the ith element of 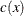 is called the Jacobian matrix of (or simply the Jacobian of the NLP problem) and is denoted by
is called the Jacobian matrix of (or simply the Jacobian of the NLP problem) and is denoted by 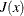 . You can also use
. You can also use 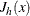 to denote the
to denote the 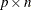 Jacobian matrix of the equality constraints and use
Jacobian matrix of the equality constraints and use 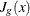 to denote the
to denote the 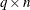 Jacobian matrix of the inequality constraints.
Jacobian matrix of the inequality constraints.