The Decomposition Algorithm
- Overview
-
Getting Started

-
SyntaxDecomposition Algorithm Options in the PROC OPTLP Statement or the SOLVE WITH LP Statement in PROC OPTMODELDecomposition Algorithm Options in the PROC OPTMILP Statement or the SOLVE WITH MILP Statement in PROC OPTMODELDECOMP StatementDECOMP_MASTER StatementDECOMP_MASTER_IP StatementDECOMP_SUBPROB Statement
-
Details
-
ExamplesMulticommodity Flow Problem and METHOD=NETWORKGeneralized Assignment ProblemBlock-Diagonal Structure and METHOD=CONCOMP in Single-Machine ModeBlock-Diagonal Structure and METHOD=CONCOMP in Distributed ModeBlock-Angular Structure and METHOD=AUTOBin Packing ProblemResource Allocation ProblemVehicle Routing ProblemATM Cash Management in Single-Machine ModeATM Cash Management in Distributed ModeKidney Donor Exchange and METHOD=SET
- References
Overview: Decomposition Algorithm
The SAS/OR decomposition algorithm (DECOMP) provides an alternative method of solving linear programs (LPs) and mixed integer linear programs (MILPs) by exploiting the ability to efficiently solve a relaxation of the original problem. The algorithm is available as an option in the OPTMODEL, OPTLP, and OPTMILP procedures and is based on the methodology described in Galati (2009).
A standard linear or mixed integer linear program has the formulation
![\[ \begin{array}{rllllll} \mbox{minimize} & \mathbf{c}^{\top } \mathbf{x} & + & \mathbf{f}^{\top } \mathbf{y} \\ \mbox{subject to} & \mathbf{D x} & + & \mathbf{B y} & \{ \geq , =, \leq \} & \mathbf{d} & \mbox{(master)} \\ & \mathbf{A x} & & & \{ \geq , =, \leq \} & \mathbf{b} & \mbox{(subproblem)} \\ & \multicolumn{5}{l}{\underline{x}_ i \leq x_ i \leq \overline{x}_ i, \; \; x_ i \in \mathbb {Z} \; \; i \in \mathcal{S}_ x} \\ & \multicolumn{5}{l}{\underline{y}_ i \leq y_ i \leq \overline{y}_ i, \; \; y_ i \in \mathbb {Z} \; \; i \in \mathcal{S}_ y} \\ \end{array} \]](images/ormpug_decomp0001.png)
where
|
|
is the vector of structural variables |
|
|
is the vector of master-only structural variables |
|
|
is the vector of objective function coefficients that are associated with variables |
|
|
is the vector of objective function coefficients that are associated with variables |
|
|
is the matrix of master constraint coefficients that are associated with variables |
|
|
is the matrix of master constraint coefficients that are associated with variables |
|
|
is the matrix of subproblem constraint coefficients |
|
|
is the vector of master constraints’ right-hand sides |
|
|
is the vector of subproblem constraints’ right-hand sides |
|
|
is the vector of lower bounds on variables |
|
|
is the vector of upper bounds on variables |
|
|
is the vector of lower bounds on variables |
|
|
is the vector of upper bounds on variables |
|
|
is a subset of the set |
|
|
is a subset of the set |
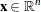
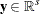
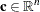

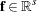
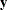
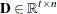
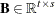
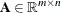
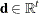
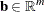
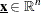
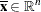
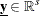
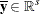
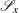
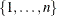
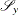
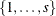
You can form a relaxation
of the preceding mathematical program by removing the master constraints,
which are defined by the matrices 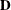 and
and 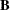 . The resulting constraint system, defined by the matrix
. The resulting constraint system, defined by the matrix 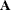 , forms the subproblem,
which can often be solved much more efficiently than the entire original problem. This is one of the key motivators for using
the decomposition algorithm.
, forms the subproblem,
which can often be solved much more efficiently than the entire original problem. This is one of the key motivators for using
the decomposition algorithm.
The decomposition algorithm works by finding convex combinations of extreme points of the subproblem polyhedron that satisfy the constraints defined in the master. For MILP subproblems, the strength of the relaxation is another important motivator for using this method. If the subproblem polyhedron defines feasible solutions that are close to the original feasible space, the chance of success for the algorithm increases.
The region that defines the subproblem space is often separable. That is, the formulation of the preceding mathematical program can be written in block-angular form as
![\[ \begin{array}{rlllllllllll} \mbox{minimize} & {\mathbf{c}^1} \mathbf{x}^1 & + & {\mathbf{c}}^2 \mathbf{x}^2 & + & \cdots & + & {\mathbf{c}^{\kappa }} \mathbf{x}^{\kappa } & + & \mathbf{f}^{\top } y \\ \mbox{subject to} & \mathbf{D}^1 \mathbf{x}^1 & + & \mathbf{D}^2 \mathbf{x}^2 & + & \cdots & + & \mathbf{D}^{\kappa } \mathbf{x}^{\kappa } & + & \mathbf{B} \mathbf{y} & \{ \geq , =, \leq \} & \mathbf{d} \\ & \mathbf{A}^1 \mathbf{x}^1 & & & & & & & & & \{ \geq , =, \leq \} & \mathbf{b}^1 \\ & & & \mathbf{A}^2 \mathbf{x}^2 & & & & & & & \{ \geq , =, \leq \} & \mathbf{b}^2 \\ & & & & & \ddots & & & & & \{ \geq , =, \leq \} & \vdots \\ & & & & & & & \mathbf{A}^{\kappa } \mathbf{x}^{\kappa } & & & \{ \geq , =, \leq \} & \mathbf{b}^{\kappa } \\ & \multicolumn{11}{l}{\underline{x}_ i \leq x_ i \leq \overline{x}_ i, \; \; x_ i \in \mathbb {Z} \; \; i \in \mathcal{S}_ x} \\ & \multicolumn{11}{l}{\underline{y}_ i \leq y_ i \leq \overline{y}_ i, \; \; y_ i \in \mathbb {Z} \; \; i \in \mathcal{S}_ y} \\ \end{array} \]](images/ormpug_decomp0024.png)
where 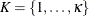 defines a partition of the constraints (and variables) into independent subproblems (blocks)
such that
defines a partition of the constraints (and variables) into independent subproblems (blocks)
such that ![$\mathbf{A} = [\mathbf{A}^1 \dots \mathbf{A}^\kappa ]$](images/ormpug_decomp0026.png) ,
, ![$\mathbf{D} = [\mathbf{D}^1 \dots \mathbf{D}^\kappa ]$](images/ormpug_decomp0027.png) ,
, ![$\mathbf{c} = [\mathbf{c}^1 \dots \mathbf{c}^\kappa ]$](images/ormpug_decomp0028.png) ,
, ![$\mathbf{b} = [\mathbf{b}^1 \dots \mathbf{b}^\kappa ]$](images/ormpug_decomp0029.png) ,
, ![$\mathbf{\underline{x}} = [\mathbf{\underline{x}}^1 \dots \mathbf{\underline{x}}^\kappa ]$](images/ormpug_decomp0030.png) ,
, ![$\mathbf{\overline{x}} = [\mathbf{\overline{x}}^1 \dots \mathbf{\overline{x}}^\kappa ]$](images/ormpug_decomp0031.png) , and
, and ![$\mathbf{x}= [\mathbf{x}^1 \dots \mathbf{x}^\kappa ]$](images/ormpug_decomp0032.png) . This type of structure is relatively common in modeling mathematical programs. For example, consider a model that defines
a workplace that has separate departmental restrictions (defined as the subproblem constraints), which are coupled together
by a company-wide budget across departments (defined as the master constraint).
By relaxing the budget (master) constraint, the decomposition algorithm can take advantage of the fact that the decoupled
subproblems are separable, and it can process them in parallel. A special case of block-angular form, called block-diagonal form,
occurs when the set of master constraints is empty. In this special case, the subproblem matrices define the entire original
problem.
. This type of structure is relatively common in modeling mathematical programs. For example, consider a model that defines
a workplace that has separate departmental restrictions (defined as the subproblem constraints), which are coupled together
by a company-wide budget across departments (defined as the master constraint).
By relaxing the budget (master) constraint, the decomposition algorithm can take advantage of the fact that the decoupled
subproblems are separable, and it can process them in parallel. A special case of block-angular form, called block-diagonal form,
occurs when the set of master constraints is empty. In this special case, the subproblem matrices define the entire original
problem.
An important indicator of a problem that is well suited for decomposition is the amount by which the subproblems cover the original problem with respect to both variables and constraints in the original presolved model. This value, which is expressed as a percentage of the original model, is known as the coverage. For LPs, the decomposition algorithm usually performs better than standard approaches only if the subproblems cover a significant amount of the original problem. For MILPs, the correlation between performance and coverage is more difficult to determine, because the strength of the subproblem with respect to integrality is not always proportional to the size of the system. Regardless, it is unlikely that the decomposition algorithm will outperform more standard methods (such as branch-and-cut) in problems that have small coverage.
The primary input and output for the decomposition algorithm are identical to those that are needed and produced by the OPTLP, OPTMILP, and OPTMODEL procedures. For more information, see the following sections:
The only additional input that can be provided for the decomposition algorithm is an explicit definition of the partition of the subproblem constraints. The following section gives a simple example of providing this input for both PROC OPTMILP and PROC OPTMODEL.