The NLP Procedure
- Overview
-
Getting Started

-
SyntaxFunctional SummaryDictionary of OptionsPROC NLP StatementARRAY StatementBOUNDS StatementBY StatementCRPJAC StatementDECVAR StatementGRADIENT StatementHESSIAN StatementINCLUDE StatementJACNLC StatementJACOBIAN StatementLABEL StatementLINCON StatementMATRIX StatementMIN, MAX, and LSQ StatementsMINQUAD and MAXQUAD StatementsNLINCON StatementPROFILE StatementProgram Statements
-
DetailsCriteria for OptimalityOptimization AlgorithmsFinite-Difference Approximations of DerivativesHessian and CRP Jacobian ScalingTesting the Gradient SpecificationTermination CriteriaActive Set MethodsFeasible Starting PointLine-Search MethodsRestricting the Step LengthComputational ProblemsCovariance MatrixInput and Output Data SetsDisplayed OutputMissing ValuesComputational ResourcesMemory LimitRewriting NLP Models for PROC OPTMODEL
-
Examples
- References
Rewriting NLP Models for PROC OPTMODEL
This section covers techniques for converting NLP procedure models to OPTMODEL procedure models. For information about the OPTMODEL procedure, see Chapter 5: The OPTMODEL Procedure in SAS/OR 14.1 User's Guide: Mathematical Programming.
To illustrate the basics, consider the following first version of the NLP model for Example 6.7:
/****************************************************************/ /* Rewriting NLP Models for PROC OPTMODEL */ /****************************************************************/
proc nlp all;
parms amountx amounty amounta amountb amountc
pooltox pooltoy ctox ctoy pools = 1;
bounds 0 <= amountx amounty amounta amountb amountc,
amountx <= 100,
amounty <= 200,
0 <= pooltox pooltoy ctox ctoy,
1 <= pools <= 3;
lincon amounta + amountb = pooltox + pooltoy,
pooltox + ctox = amountx,
pooltoy + ctoy = amounty,
ctox + ctoy = amountc;
nlincon nlc1-nlc2 >= 0.,
nlc3 = 0.;
max f;
costa = 6; costb = 16; costc = 10;
costx = 9; costy = 15;
f = costx * amountx + costy * amounty
- costa * amounta - costb * amountb - costc * amountc;
nlc1 = 2.5 * amountx - pools * pooltox - 2. * ctox;
nlc2 = 1.5 * amounty - pools * pooltoy - 2. * ctoy;
nlc3 = 3 * amounta + amountb - pools * (amounta + amountb);
run;
These statements define a model that has bounds, linear constraints, nonlinear constraints, and a simple objective function. The following statements are a straightforward conversion of the PROC NLP statements to PROC OPTMODEL form:
proc optmodel;
var amountx init 1 >= 0 <= 100,
amounty init 1 >= 0 <= 200;
var amounta init 1 >= 0,
amountb init 1 >= 0,
amountc init 1 >= 0;
var pooltox init 1 >= 0,
pooltoy init 1 >= 0;
var ctox init 1 >= 0,
ctoy init 1 >= 0;
var pools init 1 >=1 <= 3;
con amounta + amountb = pooltox + pooltoy,
pooltox + ctox = amountx,
pooltoy + ctoy = amounty,
ctox + ctoy = amountc;
number costa, costb, costc, costx, costy;
costa = 6; costb = 16; costc = 10;
costx = 9; costy = 15;
max f = costx * amountx + costy * amounty
- costa * amounta - costb * amountb - costc * amountc;
con nlc1: 2.5 * amountx - pools * pooltox - 2. * ctox >= 0,
nlc2: 1.5 * amounty - pools * pooltoy - 2. * ctoy >= 0,
nlc3: 3 * amounta + amountb - pools * (amounta + amountb)
= 0;
solve;
print amountx amounty amounta amountb amountc
pooltox pooltoy ctox ctoy pools;
The PROC OPTMODEL variable declarations are split into individual declarations because PROC OPTMODEL does not permit name lists in its declarations. In the OPTMODEL procedure, variable bounds are part of the variable declaration instead of a separate BOUNDS statement. The PROC NLP statements are as follows:
parms amountx amounty amounta amountb amountc
pooltox pooltoy ctox ctoy pools = 1;
bounds 0 <= amountx amounty amounta amountb amountc,
amountx <= 100,
amounty <= 200,
0 <= pooltox pooltoy ctox ctoy,
1 <= pools <= 3;
The following PROC OPTMODEL statements are equivalent to the PROC NLP statements:
var amountx init 1 >= 0 <= 100,
amounty init 1 >= 0 <= 200;
var amounta init 1 >= 0,
amountb init 1 >= 0,
amountc init 1 >= 0;
var pooltox init 1 >= 0,
pooltoy init 1 >= 0;
var ctox init 1 >= 0,
ctoy init 1 >= 0;
var pools init 1 >= 1 <= 3;
The linear constraints are declared in the NLP model with the following statement:
lincon amounta + amountb = pooltox + pooltoy,
pooltox + ctox = amountx,
pooltoy + ctoy = amounty,
ctox + ctoy = amountc;
The following linear constraint declarations in the PROC OPTMODEL model are quite similar to the PROC NLP LINCON declarations:
con amounta + amountb = pooltox + pooltoy,
pooltox + ctox = amountx,
pooltoy + ctoy = amounty,
ctox + ctoy = amountc;
But PROC OPTMODEL provides much more flexibility in defining linear constraints. For example, coefficients can be named parameters or any other expression that evaluates to a constant.
The cost parameters are declared explicitly in the PROC OPTMODEL model. Unlike the DATA step or PROC NLP, PROC OPTMODEL requires names
to be declared before they are used. There are multiple ways to set the values of these parameters. The preceding example
used assignments. The values could have been made part of the declaration by using the INIT expression clause or the = expression clause. The values could also have been read from a data set with the READ DATA statement.
Note in the original NLP statements that the assignment to a parameter such as costa occurs every time the objective function is evaluated. However, the assignment occurs just once in the PROC OPTMODEL code,
when the assignment statement is processed. This works because the values are constant. But the PROC OPTMODEL statements permit
the parameters to be reassigned later to interactively modify the model.
The following statements define the objective f in the NLP model:
max f;
. . .
f = costx * amountx + costy * amounty
- costa * amounta - costb * amountb - costc * amountc;
The PROC OPTMODEL version of the objective is defined with the same expression text, as follows:
max f = costx * amountx + costy * amounty
- costa * amounta - costb * amountb - costc * amountc;
But in PROC OPTMODEL the MAX statement and the assignment to the name f in the PROC NLP statements are combined. There are advantages and disadvantages to this approach. The PROC OPTMODEL formulation
is much closer to the mathematical formulation of the model. However, if there are multiple intermediate variables being used
to structure the objective, then multiple IMPVAR declarations are required.
In the PROC NLP model the nonlinear constraints use the following syntax:
nlincon nlc1-nlc2 >= 0.,
nlc3 = 0.;
. . .
nlc1 = 2.5 * amountx - pools * pooltox - 2. * ctox;
nlc2 = 1.5 * amounty - pools * pooltoy - 2. * ctoy;
nlc3 = 3 * amounta + amountb - pools * (amounta + amountb);
In the PROC OPTMODEL model the equivalent statements are as follows:
con nlc1: 2.5 * amountx - pools * pooltox - 2. * ctox >= 0,
nlc2: 1.5 * amounty - pools * pooltoy - 2. * ctoy >= 0,
nlc3: 3 * amounta + amountb - pools * (amounta + amountb)
= 0;
The nonlinear constraints in PROC OPTMODEL use the same syntax as linear constraints. In fact, if the variable pools were declared as a parameter, then all the preceding constraints would be linear. The nonlinear constraint in PROC OPTMODEL
combines the NLINCON statement of PROC NLP with the assignment in the PROC NLP statements. As in objective expressions, objective
names can be used in nonlinear constraint expressions to structure the formula.
The PROC OPTMODEL model does not use a RUN statement to invoke the solver. Instead the solver is invoked interactively by the SOLVE statement in PROC OPTMODEL. By default, the OPTMODEL procedure prints much less data about the optimization process. Generally these data consist of messages from the solver (such as the termination reason) in addition to a short status display. The PROC OPTMODEL statements add a PRINT statement in order to display the variable estimates from the solver.
The model for Example 6.8 illustrates how to convert PROC NLP statements that handle arrays into PROC OPTMODEL form. The PROC NLP model is as follows:
proc nlp tech=tr pall;
array c[10] -6.089 -17.164 -34.054 -5.914 -24.721
-14.986 -24.100 -10.708 -26.662 -22.179;
array x[10] x1-x10;
min y;
parms x1-x10 = .1;
bounds 1.e-6 <= x1-x10;
lincon 2. = x1 + 2. * x2 + 2. * x3 + x6 + x10,
1. = x4 + 2. * x5 + x6 + x7,
1. = x3 + x7 + x8 + 2. * x9 + x10;
s = x1 + x2 + x3 + x4 + x5 + x6 + x7 + x8 + x9 + x10;
y = 0.;
do j = 1 to 10;
y = y + x[j] * (c[j] + log(x[j] / s));
end;
run;
The model finds an equilibrium state for a mixture of chemicals. The following statements show a corresponding PROC OPTMODEL model:
proc optmodel;
set CMP = 1..10;
number c{CMP} = [-6.089 -17.164 -34.054 -5.914 -24.721
-14.986 -24.100 -10.708 -26.662 -22.179];
var x{CMP} init 0.1 >= 1.e-6;
con 2. = x[1] + 2. * x[2] + 2. * x[3] + x[6] + x[10],
1. = x[4] + 2. * x[5] + x[6] + x[7],
1. = x[3] + x[7] + x[8] + 2. * x[9] + x[10];
/* replace the variable s in the NLP model */
impvar s = sum{i in CMP} x[i];
min y = sum{j in CMP} x[j] * (c[j] + log(x[j] / s));
solve;
print x y;
The PROC OPTMODEL model uses the set CMP to represent the set of compounds, which are numbered 1 to 10 in the example. The array c was initialized by using the equivalent PROC OPTMODEL syntax. The individual array locations could also have been initialized
by assignment or READ DATA statements.
The VAR declaration for variable x combines the VAR and BOUNDS statements of the PROC NLP model. The index set of the array is based on the set of compounds
CMP, to simplify changes to the model.
The linear constraints are similar in form to the PROC NLP model. However, the PROC OPTMODEL version uses the array form of the variable names because the OPTMODEL procedure treats arrays as distinct variables, not as aliases of lists of scalar variables.
The implicit variable s replaces the intermediate variable
of the same name in the PROC NLP model. This is an example of translating an intermediate variable from the other models to
PROC OPTMODEL. An alternative way is to use an additional constraint for every intermediate variable. In the preceding statements,
instead of declaring objective s, you can use the following statements:
. . .
var s;
con s = sum{i in CMP} x[i];
. . .
Note that this alternative formulation passes an extra variable and constraint to the solver. This formulation can sometimes be solved more efficiently, depending on the characteristics of the model.
The PROC OPTMODEL version uses a SUM operator over the set CMP, which enhances the flexibility of the model to accommodate possible changes in the set of compounds.
In the PROC NLP model the objective function y is determined by an explicit loop. With PROC OPTMODEL, the DO loop is replaced by a SUM aggregation operation. The accumulation
in the PROC NLP model is now performed by PROC OPTMODEL with the SUM operator.
This PROC OPTMODEL model can be further generalized. Note that the array initialization and constraints assume a fixed set
of compounds. You can rewrite the model to handle an arbitrary number of compounds and chemical elements. The new model loads
the linear constraint coefficients from a data set along with the objective coefficients for the parameter c, as follows:
data comp;
input c a_1 a_2 a_3;
datalines;
-6.089 1 0 0
-17.164 2 0 0
-34.054 2 0 1
-5.914 0 1 0
-24.721 0 2 0
-14.986 1 1 0
-24.100 0 1 1
-10.708 0 0 1
-26.662 0 0 2
-22.179 1 0 1
;
data atom;
input b @@;
datalines;
2. 1. 1.
;
proc optmodel;
set CMP;
set ELT;
number c{CMP};
number a{ELT,CMP};
number b{ELT};
read data atom into ELT=[_n_] b;
read data comp into CMP=[_n_]
c {i in ELT} < a[i,_n_]=col("a_"||i) >;
var x{CMP} init 0.1 >= 1.e-6;
con bal{i in ELT}: b[i] = sum{j in CMP} a[i,j]*x[j];
impvar s = sum{i in CMP} x[i];
min y = sum{j in CMP} x[j] * (c[j] + log(x[j] / s));
print a b;
solve;
print x;
This version adds coefficients for the linear constraints to the COMP data set. The data set variable a_n represents the number of atoms in the compound for element n. The READ DATA statement for COMP uses the iterated column syntax to read each of the data set variables a_n into the appropriate location in the array a. In this example the expanded data set variable names are a_1, a_2, and a_3.
The preceding version also adds a new set, ELT, of chemical elements and a numeric parameter, b, that represents the left-hand side of the linear constraints. The data values for the parameters ELT and b are read from the data set ATOM. The model can handle varying sets of chemical elements because of this extra data set and
the new parameters.
The linear constraints have been converted to a single indexed family of constraints. One constraint is applied for each chemical
element in the set ELT. The constraint expression uses a simple form that applies generally to linear constraints. The following PRINT statement
in the model shows the values read from the data sets to define the linear constraints:
print a b;
The PRINT statements in the model produce the results shown in Figure 6.11.
Figure 6.11: PROC OPTMODEL Output
In the preceding model the chemical elements and compounds are designated by numbers. So in the PRINT output, for example,
the row that is labeled "3" represents the amount of the compound 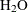 . PROC OPTMODEL is capable of using more symbolic strings to designate array indices. The following version of the model uses
strings to index arrays:
. PROC OPTMODEL is capable of using more symbolic strings to designate array indices. The following version of the model uses
strings to index arrays:
data comp;
input name $ c a_h a_n a_o;
datalines;
H -6.089 1 0 0
H2 -17.164 2 0 0
H2O -34.054 2 0 1
N -5.914 0 1 0
N2 -24.721 0 2 0
NH -14.986 1 1 0
NO -24.100 0 1 1
O -10.708 0 0 1
O2 -26.662 0 0 2
OH -22.179 1 0 1
;
data atom;
input name $ b;
datalines;
H 2.
N 1.
O 1.
;
proc optmodel;
set<string> CMP;
set<string> ELT;
number c{CMP};
number a{ELT,CMP};
number b{ELT};
read data atom into ELT=[name] b;
read data comp into CMP=[name]
c {i in ELT} < a[i,name]=col("a_"||i) >;
var x{CMP} init 0.1 >= 1.e-6;
con bal{i in ELT}: b[i] = sum{j in CMP} a[i,j]*x[j];
impvar s = sum{i in CMP} x[i];
min y = sum{j in CMP} x[j] * (c[j] + log(x[j] / s));
solve;
print x;
In this model, the sets CMP and ELT are now sets of strings. The data sets provide the names of the compounds and elements. The names of the data set variables
for atom counts in the data set COMP now include the chemical element symbol as part of their spelling. For example, the atom
count for element H (hydrogen) is named a_h. Note that these changes did not require any modification to the specifications of the linear constraints or the objective.
The PRINT statement in the preceding statements produces the results shown in Figure 6.12. The indices of variable x are now strings that represent the actual compounds.
Figure 6.12: PROC OPTMODEL Output with Strings