The NLP Procedure
- Overview
-
Getting Started

-
SyntaxFunctional SummaryDictionary of OptionsPROC NLP StatementARRAY StatementBOUNDS StatementBY StatementCRPJAC StatementDECVAR StatementGRADIENT StatementHESSIAN StatementINCLUDE StatementJACNLC StatementJACOBIAN StatementLABEL StatementLINCON StatementMATRIX StatementMIN, MAX, and LSQ StatementsMINQUAD and MAXQUAD StatementsNLINCON StatementPROFILE StatementProgram Statements
-
DetailsCriteria for OptimalityOptimization AlgorithmsFinite-Difference Approximations of DerivativesHessian and CRP Jacobian ScalingTesting the Gradient SpecificationTermination CriteriaActive Set MethodsFeasible Starting PointLine-Search MethodsRestricting the Step LengthComputational ProblemsCovariance MatrixInput and Output Data SetsDisplayed OutputMissing ValuesComputational ResourcesMemory LimitRewriting NLP Models for PROC OPTMODEL
-
Examples
- References
Covariance Matrix
The COV= option must be specified to compute an approximate covariance matrix for the parameter estimates under asymptotic theory for least squares, maximum-likelihood, or Bayesian estimation, with or without corrections for degrees of freedom as specified by the VARDEF= option.
Two groups of six different forms of covariance matrices (and therefore approximate standard errors) can be computed corresponding to the following two situations:
![\[ \min f(x) = \sum _{i=1}^ m f^2_ i(x) \]](images/ormplpug_nlp0349.png)
![\[ \textrm{opt} \, f(x) = \sum _{i=1}^ m f_ i(x) \]](images/ormplpug_nlp0350.png)
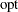
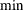
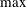
In either case, the following matrices are used:
![\[ G = \nabla ^2 f(x) \]](images/ormplpug_nlp0354.png)
![\[ J(f) = (\nabla f_1,\ldots ,\nabla f_ m) = \left( \frac{\partial f_ i}{\partial x_ j} \right) \]](images/ormplpug_nlp0355.png)
![\[ JJ(f) = J(f)^ T J(f) \]](images/ormplpug_nlp0356.png)
![\[ V = J(f)^ T \textrm{diag}(f_ i^2) J(f) \]](images/ormplpug_nlp0357.png)
![\[ W = J(f)^ T \textrm{diag}(f_ i^{\dagger }) J(f) \]](images/ormplpug_nlp0358.png)
where
![\[ f_ i^{\dagger } = \left\{ \begin{array}{ll} 0, & \mbox{if }f_ i=0 \\ 1 / f_ i, & \mbox{otherwise} \end{array} \right. \]](images/ormplpug_nlp0359.png)
For unconstrained minimization, or when none of the final parameter estimates are subjected to linear equality or active inequality constraints, the formulas of the six types of covariance matrices are as follows:
Table 6.3: Central-Difference Approximations
|
COV |
MIN or MAX Statement |
LSQ Statement |
|
|
1 |
M |
|
|
|
2 |
H |
|
|
|
3 |
J |
|
|
|
4 |
B |
|
|
|
5 |
E |
|
|
|
6 |
U |
|
|
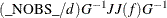
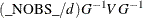
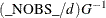
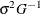
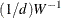
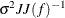
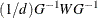
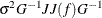
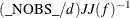
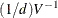
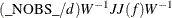
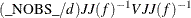
The value of d depends on the VARDEF= option and on the value of the _NOBS_ variable:
![\[ d = \left\{ \begin{array}{ll} \max (1, \_ \text {NOBS}\_ - \_ \text {DF}\_ ), & \mbox{for VARDEF=DF} \\ \_ \text {NOBS}\_ , & \mbox{for VARDEF=N} \end{array} \right. \]](images/ormplpug_nlp0372.png)
where _DF_ is either set in the program statements or set by default to n (the number of parameters) and _NOBS_ is either set in the program statements or set by default to nobs  mfun, where nobs is the number of observations in the data set and mfun is the number of functions listed in the LSQ
, MIN
, or MAX
statement.
mfun, where nobs is the number of observations in the data set and mfun is the number of functions listed in the LSQ
, MIN
, or MAX
statement.
The value 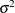 depends on the specification of the SIGSQ=
option and on the value of d:
depends on the specification of the SIGSQ=
option and on the value of d:
![\[ \sigma ^2 = \left\{ \begin{array}{ll} sq \times \_ NOBS\_ / d, & \mbox{if SIGSQ=$sq$ is specified} \\ 2 f(x^*) / d, & \mbox{if SIGSQ= is not specified} \end{array} \right. \]](images/ormplpug_nlp0374.png)
where 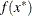 is the value of the objective function at the optimal parameter estimates
is the value of the objective function at the optimal parameter estimates 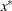 .
.
The two groups of formulas distinguish between two situations:
-
For least squares estimates, the error variance can be estimated from the objective function value and is used in three of the six different forms of covariance matrices. If you have an independent estimate of the error variance, you can specify it with the SIGSQ= option.
-
For maximum-likelihood or Bayesian estimates, the objective function should be the logarithm of the likelihood or of the posterior density when using the MAX statement.
For minimization, the inversion of the matrices in these formulas is done so that negative eigenvalues are considered zero, resulting always in a positive semidefinite covariance matrix.
In small samples, estimates of the covariance matrix based on asymptotic theory are often too small and should be used with caution.
If the final parameter estimates are subjected to 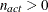 linear equality or active linear inequality constraints, the formulas of the covariance matrices are modified similar to
Gallant (1987) and Cramer (1986, p. 38) and additionally generalized for applications with singular matrices. In the constrained case, the value of d used in the scalar factor is defined by
linear equality or active linear inequality constraints, the formulas of the covariance matrices are modified similar to
Gallant (1987) and Cramer (1986, p. 38) and additionally generalized for applications with singular matrices. In the constrained case, the value of d used in the scalar factor is defined by
![\[ d = \left\{ \begin{array}{ll} \max (1, \_ \text {NOBS}\_ - \_ \text {DF}\_ + n_\mi {act}), & \mbox{for VARDEF=DF} \\ \_ \text {NOBS}\_ , & \mbox{for VARDEF=N} \end{array} \right. \]](images/ormplpug_nlp0377.png)
where 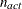 is the number of active constraints and _NOBS_ is set as in the unconstrained case.
is the number of active constraints and _NOBS_ is set as in the unconstrained case.
For minimization, the covariance matrix should be positive definite; for maximization it should be negative definite. There are several options available to check for a rank deficiency of the covariance matrix:
-
The ASINGULAR= , MSINGULAR= , and VSINGULAR= options can be used to set three singularity criteria for the inversion of the matrix A needed to compute the covariance matrix, when A is either the Hessian or one of the crossproduct Jacobian matrices. The singularity criterion used for the inversion is
![\[ |d_{j,j}| \le \max (\emph{ASING}, \emph{VSING} \times |A_{j,j}|, \emph{MSING} \times \max (|A_{1,1}|,\ldots ,|A_{n,n}|)) \]](images/ormplpug_nlp0378.png)
where
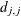 is the diagonal pivot of the matrix A, and ASING, VSING and MSING are the specified values of the ASINGULAR=
, VSINGULAR=
, and MSINGULAR=
options. The default values are
is the diagonal pivot of the matrix A, and ASING, VSING and MSING are the specified values of the ASINGULAR=
, VSINGULAR=
, and MSINGULAR=
options. The default values are
Note: In many cases, a normalized matrix
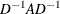 is decomposed and the singularity criteria are modified correspondingly.
is decomposed and the singularity criteria are modified correspondingly.
-
If the matrix A is found singular in the first step, a generalized inverse is computed. Depending on the G4= option, a generalized inverse is computed that satisfies either all four or only two Moore-Penrose conditions. If the number of parameters n of the application is less than or equal to G4= i, a G4 inverse is computed; otherwise only a G2 inverse is computed. The G4 inverse is computed by (the computationally very expensive but numerically stable) eigenvalue decomposition; the G2 inverse is computed by Gauss transformation. The G4 inverse is computed using the eigenvalue decomposition
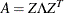 , where Z is the orthogonal matrix of eigenvectors and
, where Z is the orthogonal matrix of eigenvectors and 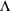 is the diagonal matrix of eigenvalues,
is the diagonal matrix of eigenvalues, 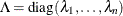 . If the PEIGVAL
option is specified, the eigenvalues
. If the PEIGVAL
option is specified, the eigenvalues
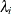 are displayed. The G4 inverse of A is set to
are displayed. The G4 inverse of A is set to
![\[ A^- = Z \Lambda ^- Z^ T \]](images/ormplpug_nlp0384.png)
where the diagonal matrix
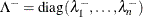 is defined using the COVSING=
option:
is defined using the COVSING=
option:
![\[ \lambda ^-_ i = \left\{ \begin{array}{ll} 1 / \lambda _ i, & \mbox{if }|\lambda _ i| > \mi{COVSING} \\ 0, & \mbox{if }|\lambda _ i| \le \mi{COVSING} \end{array} \right. \]](images/ormplpug_nlp0386.png)
If the COVSING= option is not specified, the
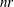 smallest eigenvalues are set to zero, where is the number of rank deficiencies found in the first step.
smallest eigenvalues are set to zero, where is the number of rank deficiencies found in the first step.
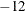
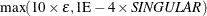

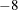
For optimization techniques that do not use second-order derivatives, the covariance matrix is usually computed using finite-difference approximations of the derivatives. By specifying TECH= NONE, any of the covariance matrices can be computed using analytical derivatives. The covariance matrix specified by the COV= option can be displayed (using the PCOV option) and is written to the OUTEST= data set.