The UCM Procedure
- Overview
-
Getting Started

-
Syntax
Functional Summary PROC UCM Statement AUTOREG Statement BLOCKSEASON Statement BY Statement CYCLE Statement DEPLAG Statement ESTIMATE Statement FORECAST Statement ID Statement IRREGULAR Statement LEVEL Statement MODEL Statement NLOPTIONS Statement OUTLIER Statement RANDOMREG Statement SEASON Statement SLOPE Statement SPLINEREG Statement SPLINESEASON Statement
-
Details
-
Examples
- References
| Computational Issues |
Convergence Problems
As explained in the section Parameter Estimation, the model parameters are estimated by nonlinear optimization of the likelihood. This process is not guaranteed to succeed. For some data sets, the optimization algorithm can fail to converge. Nonconvergence can result from a number of causes, including flat or ridged likelihood surfaces and ill-conditioned data. It is also possible for the algorithm to converge to a point that is not the global optimum of the likelihood.
If you experience convergence problems, the following points might be helpful:
Data that are extremely large or extremely small can adversely affect results because of the internal tolerances used during the filtering steps of the likelihood calculation. Rescaling the data can improve stability.
Examine your model for redundancies in the included components and regressors. If some of the included components or regressors are nearly collinear to each other, then the optimization process can become unstable.
Experimenting with different options offered by the NLOPTIONS statement can help.
Lack of convergence can indicate model misspecification or a violation of the normality assumption.
Computer Resource Requirements
The computing resources required for the UCM procedure depend on several factors. The memory requirement for the procedure is largely dependent on the number of observations to be processed and the size of the state vector underlying the specified model. If  denotes the sample size and
denotes the sample size and  denotes the size of the state vector, the memory requirement for the smoothing stage of the Kalman filter is of the order of
denotes the size of the state vector, the memory requirement for the smoothing stage of the Kalman filter is of the order of 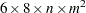 bytes, ignoring the lower-order terms. If the smoothed component estimates are not needed then the memory requirement is of the order of
bytes, ignoring the lower-order terms. If the smoothed component estimates are not needed then the memory requirement is of the order of 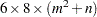 bytes. Besides and , the computing time for the parameter estimation depends on the type of components included in the model. For example, the parameter estimation is usually faster if the model parameter vector consists only of disturbance variances, because in this case there is an efficient way to compute the likelihood gradient.
bytes. Besides and , the computing time for the parameter estimation depends on the type of components included in the model. For example, the parameter estimation is usually faster if the model parameter vector consists only of disturbance variances, because in this case there is an efficient way to compute the likelihood gradient.