The SSM Procedure (Experimental)
-
Overview

- Getting Started
-
Syntax
-
Details
The State Space Model and Notation Types of Data Organization Overview of Model Specification Syntax Likelihood, Filtering, and Smoothing Contrasting PROC SSM with Other SAS Procedures Predefined Trend Models Predefined Structural Models Covariance Parameterization Missing Values Computational Issues Displayed Output ODS Table Names OUT= Data Set
-
Examples
- References
| Likelihood, Filtering, and Smoothing |
The Kalman filter and smoother (KFS) algorithm is the main computational tool for using SSM for data analysis. This subsection briefly describes the basic quantities generated by this algorithm and their relationship to the output generated by the SSM procedure. For proper treatment of SSMs with a diffuse initial condition or when regression variables are present, a modified version of the traditional KFS, called diffuse Kalman filter and smoother (DKFS), is needed. A good discussion of the different variants of the traditional and diffuse KFS can be found in Durbin and Koopman (2001). The DKFS implemented in the SSM procedure closely follows the treatment in de Jong and Chu-Chun-Lin (2003). Additional details can be found in these references.
The state space model equations (see the section The State Space Model and Notation) imply that the combined response data vector  has a Gaussian probability distribution. This probability distribution is proper if
has a Gaussian probability distribution. This probability distribution is proper if 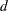 , the dimension of the diffuse vector
, the dimension of the diffuse vector 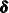 in the initial condition, is zero and if
in the initial condition, is zero and if 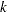 , the number of regression variables in the observation equation, is also zero (the regression parameter
, the number of regression variables in the observation equation, is also zero (the regression parameter 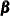 is also treated as a diffuse vector). Otherwise, this probability distribution is improper. The KFS algorithm is a combination of two iterative phases: a forward pass through the data, called filtering, and a backward pass through the data, called smoothing, that uses the quantities generated during filtering. One of the advantages of using the SSM formulation to analyze the time series data is its ability to handle the missing values in the response variables. The KFS algorithm appropriately handles the missing values in
is also treated as a diffuse vector). Otherwise, this probability distribution is improper. The KFS algorithm is a combination of two iterative phases: a forward pass through the data, called filtering, and a backward pass through the data, called smoothing, that uses the quantities generated during filtering. One of the advantages of using the SSM formulation to analyze the time series data is its ability to handle the missing values in the response variables. The KFS algorithm appropriately handles the missing values in 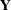 . For additional information about how PROC SSM handles missing values, see the section Missing Values.
. For additional information about how PROC SSM handles missing values, see the section Missing Values.
Filtering Pass
The filtering pass sequentially computes the following quantities for 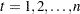 and
and 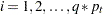 :
:
|
One-step-ahead prediction of the response values |
|
One-step-ahead prediction residuals |
|
Variance of the one-step-ahead prediction |
|
One-step-ahead prediction of the state vector |
|
Covariance of |
|
|
|
|
|
Estimate of |
|
Covariance of |
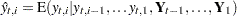
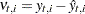
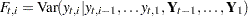
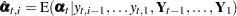
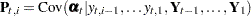

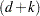 -dimensional vector
-dimensional vector 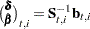
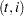
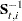
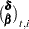
Here the notation 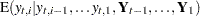 denotes the conditional expectation of
denotes the conditional expectation of 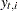 given the history up to the index
given the history up to the index 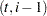 :
: 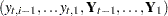 . Similarly
. Similarly 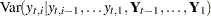 denotes the corresponding conditional variance.
denotes the corresponding conditional variance.  is set to missing whenever
is set to missing whenever 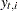 is missing. In the diffuse case, the conditional expectations must be appropriately interpreted. The vector
is missing. In the diffuse case, the conditional expectations must be appropriately interpreted. The vector 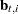 and the matrix
and the matrix  contain some accumulated quantities that are needed for the estimation of and . Of course, when
contain some accumulated quantities that are needed for the estimation of and . Of course, when 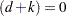 (the nondiffuse case), these quantities are not needed. In the diffuse case, as the matrix is sequentially accumulated (starting at
(the nondiffuse case), these quantities are not needed. In the diffuse case, as the matrix is sequentially accumulated (starting at 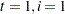 ), it might not be invertible until some
), it might not be invertible until some 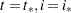 . The filtering process is called initialized after . In some situations, this initialization might not happen even after the entire sample is processed—that is, the filtering process remains uninitialized. This can happen if the regression variables are collinear or if the data are not sufficient to estimate the initial condition for some other reason.
. The filtering process is called initialized after . In some situations, this initialization might not happen even after the entire sample is processed—that is, the filtering process remains uninitialized. This can happen if the regression variables are collinear or if the data are not sufficient to estimate the initial condition for some other reason.
The filtering process is used for a variety of purposes. One important use of filtering is to compute the likelihood of the data. In the model fitting phase, the unknown model parameters 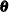 are estimated by maximum likelihood. This requires repeated evaluation of the likelihood at different trial values of . After is estimated, it is treated as a known vector. The filtering process is used again with the fitted model in the forecasting phase, when the one-step-ahead forecasts and residuals based on the fitted model are provided. In addition, this filtering output is needed by the smoothing phase to produce the full-sample component estimates.
are estimated by maximum likelihood. This requires repeated evaluation of the likelihood at different trial values of . After is estimated, it is treated as a known vector. The filtering process is used again with the fitted model in the forecasting phase, when the one-step-ahead forecasts and residuals based on the fitted model are provided. In addition, this filtering output is needed by the smoothing phase to produce the full-sample component estimates.
Likelihood Computation and Model Fitting Phase
In view of the Gaussian nature of the response vector, the likelihood of 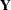 ,
, 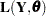 , can be computed by using the prediction-error decomposition, which leads to the formula
, can be computed by using the prediction-error decomposition, which leads to the formula
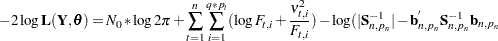 |
where 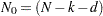 ,
, 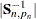 denotes the determinant of
denotes the determinant of 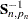 , and
, and 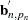 denotes the transpose of the column vector
denotes the transpose of the column vector  . In the preceding formula, the terms associated with the missing response values are excluded and
. In the preceding formula, the terms associated with the missing response values are excluded and 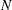 denotes the total number of nonmissing response values in the sample. If
denotes the total number of nonmissing response values in the sample. If 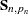 is not invertible, then a generalized inverse is used in place of , and is computed based on the nonzero eigenvalues of . Moreover, in this case
is not invertible, then a generalized inverse is used in place of , and is computed based on the nonzero eigenvalues of . Moreover, in this case 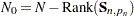 . When has proper distribution (that is, when ), the terms that involve
. When has proper distribution (that is, when ), the terms that involve 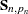 and are absent and the preceding likelihood is proper. Otherwise, it is called the diffuse likelihood or the restricted likelihood.
and are absent and the preceding likelihood is proper. Otherwise, it is called the diffuse likelihood or the restricted likelihood.
When the model specification contains any unknown parameters , they are estimated by maximizing the preceding likelihood function. This is done by using a nonlinear optimization process that involves repeated evaluations of at different values of . The maximum likelihood (ML) estimate of is denoted by 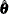 . When the restricted likelihood is used for computing , the estimate is called the restricted maximum likelihood (REML) estimate. Approximate standard errors of are computed by taking the square root of the diagonal elements of its (approximate) covariance matrix. This covariance is computed as
. When the restricted likelihood is used for computing , the estimate is called the restricted maximum likelihood (REML) estimate. Approximate standard errors of are computed by taking the square root of the diagonal elements of its (approximate) covariance matrix. This covariance is computed as 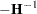 where
where 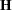 is the Hessian (the matrix of the second-order partials) of
is the Hessian (the matrix of the second-order partials) of 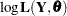 , evaluated at the optimum .
, evaluated at the optimum .
Let 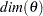 denote the dimension of the parameter vector . After the parameter estimation is completed, a table, called "Likelihood-Based Fit Statistics" is printed. It summarizes the likelihood calculations at . The first half of this table contains the information shown in Table 27.6.
denote the dimension of the parameter vector . After the parameter estimation is completed, a table, called "Likelihood-Based Fit Statistics" is printed. It summarizes the likelihood calculations at . The first half of this table contains the information shown in Table 27.6.
Statistic |
Formula |
|---|---|
Nonmissing response values used |
|
Estimated parameters |
|
Initialized diffuse state elements |
|
Normalized residual sum of squares |
|
Full log likelihood |
|

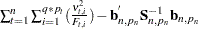
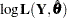
The second half of "Likelihood-Based Fit Statistics" table reports a variety of information-based criteria, which are functions of 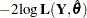 ,
, 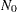 , and
, and 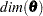 . Table 27.7 summarizes the reported information criteria in smaller-is-better form:
. Table 27.7 summarizes the reported information criteria in smaller-is-better form:
Criterion |
Formula |
Reference |
|---|---|---|
AIC |
|
Akaike (1974) |
AICC |
|
Hurvich and Tsai (1989) |
Burnham and Anderson (1998) |
||
HQIC |
|
Hannan and Quinn (1979) |
BIC |
|
Schwarz (1978) |
CAIC |
|
Bozdogan (1987) |
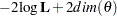
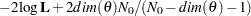

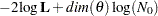

Forecasting Phase
After the model fitting phase, the filtering process is repeated again to produce the model-based one-step-ahead response variable forecasts (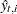 ), residuals (), and their standard errors (
), residuals (), and their standard errors (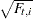 ). In addition, one-step-ahead forecasts of the components specified in the model statements, and any other user-defined linear combination of
). In addition, one-step-ahead forecasts of the components specified in the model statements, and any other user-defined linear combination of 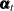 , are also produced. These forecasts are set to missing until the index
, are also produced. These forecasts are set to missing until the index 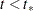 (that is, until the filtering process is initialized). If the filtering process remains uninitialized, then all the one-step-ahead forecast related quantities, (such as and ) are reported as missing.
(that is, until the filtering process is initialized). If the filtering process remains uninitialized, then all the one-step-ahead forecast related quantities, (such as and ) are reported as missing.
Smoothing Phase
After the filtering phase of KFS produces the one-step-ahead predictions of the response variables and the underlying state vectors, the smoothing phase of KFS produces the full-sample versions of these quantities—that is, rather than using the history up to , the entire sample is used. The smoothing phase of KFS is a backward algorithm, which begins at 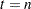 and
and 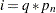 and goes back towards
and goes back towards 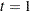 and
and 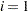 . It produces the following quantities:
. It produces the following quantities:
|
Interpolated response value |
|
Variance of the interpolated response value |
|
Full-sample estimate of the state vector |
|
Covariance of |
|
Full-sample estimate of |
|
Covariance of |
|
Estimate of additive outlier |
|
Variance of |
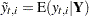
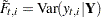
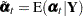
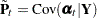
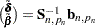
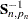
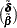
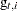
Note that if 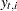 is not missing, then
is not missing, then 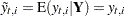 and
and 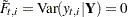 since, given ,
since, given , 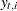 is completely known. Therefore,
is completely known. Therefore, 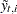 provides nontrivial information only when is missing—in which case represents the best estimate of based on the available data. The full sample estimates of components specified in the model equations are based on the corresponding linear combinations of
provides nontrivial information only when is missing—in which case represents the best estimate of based on the available data. The full sample estimates of components specified in the model equations are based on the corresponding linear combinations of 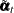 . Similarly, their standard errors are computed by using appropriate functions of
. Similarly, their standard errors are computed by using appropriate functions of 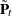 . The estimate of additive outlier,
. The estimate of additive outlier, 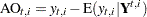 , is the difference between the observed response value and its estimate using all the data except , which is denoted by
, is the difference between the observed response value and its estimate using all the data except , which is denoted by 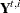 . The estimate
. The estimate 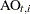 is missing when is missing. For more information about the computation of additive outliers, see de Jong and Penzer (1998).
is missing when is missing. For more information about the computation of additive outliers, see de Jong and Penzer (1998).
If the filtering process remains uninitialized until the end of the sample (that is, if is not invertible), some linear combinations of and are not estimable. This, in turn, implies that some linear combinations of are also inestimable. These inestimable quantities are reported as missing. For more information about the estimability of the state effects see Selukar (2010).
Note: This procedure is experimental.