The MCMC Procedure
-
Overview

-
Getting Started
-
Syntax
-
DetailsHow PROC MCMC WorksBlocking of ParametersSampling MethodsTuning the Proposal DistributionDirect SamplingConjugate SamplingInitial Values of the Markov ChainsAssignments of ParametersStandard DistributionsUsage of Multivariate DistributionsSpecifying a New DistributionUsing Density Functions in the Programming StatementsTruncation and CensoringSome Useful SAS FunctionsMatrix Functions in PROC MCMCCreate Design MatrixModeling Joint LikelihoodAccess Lag and Lead VariablesCALL ODE and CALL QUAD SubroutinesRegenerating Diagnostics PlotsCaterpillar PlotAutocall Macros for PostprocessingGamma and Inverse-Gamma DistributionsPosterior Predictive DistributionHandling of Missing DataFunctions of Random-Effects ParametersFloating Point Errors and OverflowsHandling Error MessagesComputational ResourcesDisplayed OutputODS Table NamesODS Graphics
-
ExamplesSimulating Samples From a Known DensityBox-Cox TransformationLogistic Regression Model with a Diffuse PriorLogistic Regression Model with Jeffreys’ PriorPoisson RegressionNonlinear Poisson Regression ModelsLogistic Regression Random-Effects ModelNonlinear Poisson Regression Multilevel Random-Effects ModelMultivariate Normal Random-Effects ModelMissing at Random AnalysisNonignorably Missing Data (MNAR) AnalysisChange Point ModelsExponential and Weibull Survival AnalysisTime Independent Cox ModelTime Dependent Cox ModelPiecewise Exponential Frailty ModelNormal Regression with Interval CensoringConstrained AnalysisImplement a New Sampling AlgorithmUsing a Transformation to Improve MixingGelman-Rubin DiagnosticsOne-Compartment Model with Pharmacokinetic Data
- References
PREDDIST Statement
-
PREDDIST <'label'> OUTPRED=SAS-data-set <NSIM=n> <COVARIATES=SAS-data-set><STATISTICS=options>;
The PREDDIST statement creates a new SAS data set that contains random samples from the posterior predictive distribution
of the response variable. The posterior predictive distribution is the distribution of unobserved observations (prediction)
conditional on the observed data. Let 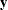 be the observed data,
be the observed data, 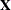 be the covariates,
be the covariates, 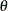 be the parameter, and
be the parameter, and 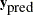 be the unobserved data. The posterior predictive distribution is defined to be the following:
be the unobserved data. The posterior predictive distribution is defined to be the following:
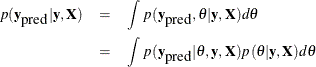
Given the assumption that the observed and unobserved data are conditional independent given , the posterior predictive distribution can be further simplified as the following:
![\[ p(\mb{y}_{\mbox{pred}} | \mb{y}, \mb{X} ) = \int p(\mb{y}_{\mbox{pred}} | \theta ) p(\theta | \mb{y}, \mb{X}) d\theta \]](images/statug_mcmc0098.png)
The posterior predictive distribution is an integral of the likelihood function 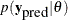 with respect to the posterior distribution
with respect to the posterior distribution 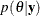 . The PREDDIST statement generates samples from a posterior predictive distribution based on draws from the posterior distribution
of .
. The PREDDIST statement generates samples from a posterior predictive distribution based on draws from the posterior distribution
of .
The PREDDIST statement works only on response variables that have standard distributions, and it does not support either the GENERAL or DGENERAL functions. Multiple PREDDIST statements can be specified, and an optional label (specified as a quoted string) helps identify the output.
The following list explains specifications in the PREDDIST statement:
For an example that uses the PREDDIST statement, see the section Posterior Predictive Distribution.