The HPLOGISTIC Procedure
-
Overview

-
Getting Started
-
Syntax
-
DetailsMissing ValuesResponse DistributionsLog-Likelihood FunctionsExistence of Maximum Likelihood EstimatesUsing Validation and Test DataModel Fit and Assessment StatisticsThe Hosmer-Lemeshow Goodness-of-Fit TestComputational Method: MultithreadingChoosing an Optimization AlgorithmDisplayed OutputODS Table Names
-
Examples
- References
Binary Logistic Regression
The following DATA step contains 100 observations on a dichotomous response variable (y), a character variable (C), and 10 continuous variables (x1–x10):
data getStarted; input C$ y x1-x10; datalines; D 0 10.2 6 1.6 38 15 2.4 20 0.8 8.5 3.9 F 1 12.2 6 2.6 42 61 1.5 10 0.6 8.5 0.7 D 1 7.7 1 2.1 38 61 1 90 0.6 7.5 5.2 J 1 10.9 7 3.5 46 42 0.3 0 0.2 6 3.6 E 0 17.3 6 3.8 26 47 0.9 10 0.4 1.5 4.7 A 0 18.7 4 1.8 2 34 1.7 80 1 9.5 2.2 B 0 7.2 1 0.3 48 61 1.1 10 0.8 3.5 4 D 0 0.1 3 2.4 0 65 1.6 70 0.8 3.5 0.7 H 1 2.4 4 0.7 38 22 0.2 20 0 3 4.2 J 0 15.6 7 1.4 0 98 0.3 0 1 5 5.2 J 0 11.1 3 2.4 42 55 2.2 60 0.6 4.5 0.7 F 0 4 6 0.9 4 36 2.1 30 0.8 9 4.6 A 0 6.2 2 1.8 14 79 1.1 70 0.2 0 5.1 H 0 3.7 3 0.8 12 66 1.3 40 0.4 0.5 3.3 A 1 9.2 3 2.3 48 51 2.3 50 0 6 5.4 G 0 14 3 2 18 12 2.2 0 0 3 3.4 E 1 19.5 6 3.7 26 81 0.1 30 0.6 5 4.8 C 0 11 3 2.8 38 9 1.7 50 0.8 6.5 0.9 I 0 15.3 7 2.2 20 98 2.7 100 0.4 7 0.8 H 1 7.4 4 0.5 28 65 1.3 60 0.2 9.5 5.4 F 0 11.4 2 1.4 42 12 2.4 10 0.4 1 4.5 C 1 19.4 1 0.4 42 4 2.4 10 0 6.5 0.1 G 0 5.9 4 2.6 12 57 0.8 50 0.4 2 5.8 G 1 15.8 6 3.7 34 8 1.3 90 0.6 2.5 5.7 I 0 10 3 1.9 16 80 3 90 0.4 9.5 1.9 E 0 15.7 1 2.7 32 25 1.7 20 0.2 8.5 6 G 0 11 5 2.9 48 53 0.1 50 1 3.5 1.2 J 1 16.8 0 0.9 14 86 1.4 40 0.8 9 5 D 1 11 4 3.2 48 63 2.8 90 0.6 0 2.2 J 1 4.8 7 3.6 24 1 2.2 20 1 8.5 0.5 J 1 10.4 5 2 42 56 1 20 0 3.5 4.2 G 0 12.7 7 3.6 8 56 2.1 70 1 4.5 1.5 G 0 6.8 1 3.2 30 27 0.6 0 0.8 2 5.6 E 0 8.8 0 3.2 2 67 0.7 10 0.4 1 5 I 1 0.2 0 2.9 10 41 2.3 60 0.2 9 0.3 J 1 4.6 7 3.9 50 61 2.1 50 0.4 3 4.9 J 1 2.3 2 3.2 36 98 0.1 40 0.6 4.5 4.3 I 0 10.8 3 2.7 28 58 0.8 80 0.8 3 6 B 0 9.3 2 3.3 44 44 0.3 50 0.8 5.5 0.4 F 0 9.2 6 0.6 4 64 0.1 0 0.6 4.5 3.9 D 0 7.4 0 2.9 14 0 0.2 30 0.8 7.5 4.5 G 0 18.3 3 3.1 8 60 0.3 60 0.2 7 1.9 F 0 5.3 4 0.2 48 63 2.3 80 0.2 8 5.2 C 0 2.6 5 2.2 24 4 1.3 20 0 2 1.4 F 0 13.8 4 3.6 4 7 1.1 10 0.4 3.5 1.9 B 1 12.4 6 1.7 30 44 1.1 60 0.2 6 1.5 I 0 1.3 1 1.3 8 53 1.1 70 0.6 7 0.8 F 0 18.2 7 1.7 26 92 2.2 30 1 8.5 4.8 J 0 5.2 2 2.2 18 12 1.4 90 0.8 4 4.9 G 1 9.4 2 0.8 22 86 0.4 30 0.4 1 5.9 J 1 10.4 2 1.7 26 31 2.4 10 0.2 7 1.6 J 0 13 1 1.8 14 11 2.3 50 0.6 5.5 2.6 A 0 17.9 4 3.1 46 58 2.6 90 0.6 1.5 3.2 D 1 19.4 6 3 20 50 2.8 100 0.2 9 1.2 I 0 19.6 3 3.6 22 19 1.2 0 0.6 5 4.1 I 1 6 2 1.5 30 30 2.2 20 0.4 8.5 5.3 G 0 13.8 1 2.7 0 52 2.4 20 0.8 6 2 B 0 14.3 4 2.9 30 11 0.6 90 0.6 0.5 4.9 E 0 15.6 0 0.4 38 79 0.4 80 0.4 1 3.3 D 0 14 2 1 22 61 3 90 0.6 2 0.1 C 1 9.4 5 0.4 12 53 1.7 40 0 3 1.1 H 0 13.2 1 1.6 40 15 0.7 40 0.2 9 5.5 A 0 13.5 5 2.4 18 89 1.6 20 0.4 9.5 4.7 E 0 2.6 4 2.3 38 6 0.8 20 0.4 5 5.3 E 0 12.4 3 1.3 26 8 2.8 10 0.8 6 5.8 D 0 7.6 2 0.9 44 89 1.3 50 0.8 6 0.4 I 0 12.7 1 2.3 42 6 2.4 10 0.4 1 3 C 1 10.7 4 3.2 28 23 2.2 90 0.8 5.5 2.8 H 0 10.1 2 2.3 10 62 0.9 50 0.4 2.5 3.7 C 1 16.6 1 0.5 12 88 0.1 20 0.6 5.5 1.8 I 1 0.2 3 2.2 8 71 1.7 80 0.4 0.5 5.5 C 0 10.8 4 3.5 30 70 2.3 60 0.4 4.5 5.9 F 0 7.1 4 3 14 63 2.4 70 0 7 3.1 D 0 16.5 1 3.3 30 80 1.6 40 0 3.5 2.7 H 0 17.1 7 2.1 30 45 1.5 60 0.6 0.5 2.8 D 0 4.3 1 1.5 24 44 0 70 0 5 0.5 H 0 15 2 0.2 14 87 1.8 50 0 4.5 4.7 G 0 19.7 3 1.9 36 99 1.5 10 0.6 3 1.7 H 1 2.8 6 0.6 34 21 2 60 1 9 4.7 G 0 16.6 3 3.3 46 1 1.4 70 0.6 1.5 5.3 E 0 11.7 5 2.7 48 4 0.9 60 0.8 4.5 1.6 F 0 15.6 3 0.2 4 79 0.5 0 0.8 1.5 2.9 C 1 5.3 6 1.4 8 64 2 80 0.4 9 4.2 B 1 8.1 7 1.7 40 36 1.4 60 0.6 6 3.9 I 0 14.8 2 3.2 8 37 0.4 10 0 4.5 3 D 0 7.4 4 3 12 3 0.6 60 0.6 7 0.7 D 0 4.8 3 2.3 44 41 1.9 60 0.2 3 3.1 A 0 4.5 0 0.2 4 48 1.7 80 0.8 9 4.2 D 0 6.9 6 3.3 14 92 0.5 40 0.4 7.5 5 B 0 4.7 4 0.9 14 99 2.4 80 1 0.5 0.7 I 1 7.5 4 2.1 20 79 0.4 40 0.4 2.5 0.7 C 0 6.1 0 1.4 38 18 2.3 60 0.8 4.5 0.7 C 0 18.3 1 1 26 98 2.7 20 1 8.5 0.5 F 0 16.4 7 1.2 32 94 2.9 40 0.4 5.5 2.1 I 0 9.4 2 2.3 32 42 0.2 70 0.4 8.5 0.3 F 1 17.9 4 1.3 32 42 2 40 0.2 1 5.4 H 0 14.9 3 1.6 36 74 2.6 60 0.2 1 2.3 C 0 12.7 0 2.6 0 88 1.1 80 0.8 0.5 2.1 F 0 5.4 4 1.5 2 1 1.8 70 0.4 5.5 3.6 J 1 12.1 4 1.8 20 59 1.3 60 0.4 3 3.8 ;
The following statements fit a logistic model to these data by using a classification effect for variable C and 10 regressor effects for x1–x10:
proc hplogistic data=getStarted; class C; model y = C x1-x10; run;
The default output from this analysis is presented in Figure 54.1 through Figure 54.11.
The "Performance Information" table in Figure 54.1 shows that the procedure executes in single-machine mode—that is, the model is fit on the machine where the SAS session executes. This run of the HPLOGISTIC procedure was performed on a multicore machine with the same number of CPUs as there are threads; that is, one computational thread was spawned per CPU.
Figure 54.1: Performance Information
Figure 54.2 displays the "Model Information" table. The HPLOGISTIC procedure uses a Newton-Raphson algorithm to model a binary distribution
for the variable y with a logit link function. The CLASS
variable C is parameterized using the GLM parameterization, which is the default.
Figure 54.2: Model Information
The CLASS
variable C has 10 unique formatted levels, and these are displayed in the "Class Level Information" table in Figure 54.3.
Figure 54.3: Class Level Information
Figure 54.4 displays the "Number of Observations" table. All 100 observations in the data set are used in the analysis.
The "Response Profile" table in Figure 54.5 is produced by default for binary and multinomial response variables. It shows the breakdown of the response variable levels
by frequency. By default for binary data, the HPLOGISTIC procedure models the probability of the event with the lower-ordered
value in the "Response Profile" table—this is indicated by the note that follows the table. In this example, the values represented
by y = '0' are modeled as the "successes" in the Bernoulli experiments.
Figure 54.5: Response Profile
You can use the response-variable options in the MODEL statement to affect which value of the response variable is modeled.
Figure 54.6 displays the "Dimensions" table for this model. This table summarizes some important sizes of various model components. For
example, it shows that there are 21 columns in the design matrix 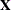 , which correspond to one column for the intercept, 10 columns for the effect associated with the classification variable
, which correspond to one column for the intercept, 10 columns for the effect associated with the classification variable
C, and one column each for the continuous variables x1–x10. However, the rank of the crossproducts matrix is only 20. Because the classification variable C uses GLM parameterization and because the model contains an intercept, there is one singularity in the crossproducts matrix
of the model. Consequently, only 20 parameters enter the optimization.
Figure 54.6: Dimensions in Binomial Logistic Regression
The "Iteration History" table is shown in Figure 54.7. The Newton-Raphson algorithm with ridging converged after four iterations, not counting the initial setup iteration.
Figure 54.7: Iteration History
Figure 54.8 displays the final convergence status of the Newton-Raphson algorithm. The GCONV= relative convergence criterion is satisfied.
The "Fit Statistics" table is shown in Figure 54.9. The –2 log likelihood at the converged estimates is 88.7007. You can use this value to compare the model to nested model alternatives by means of a likelihood-ratio test. To compare models that are not nested, information criteria such as AIC (Akaike’s information criterion), AICC (Akaike’s bias-corrected information criterion), and BIC (Schwarz’ Bayesian information criterion) are used. These criteria penalize the –2 log likelihood for the number of parameters. Because of the large number of parameters relative to the number of observations, the discrepancy between the –2 log likelihood and, say, AIC, is substantial in this case.
Figure 54.9: Fit Statistics
Figure 54.10 shows the global test for the null hypothesis that all model effects jointly do not affect the probability of success of the binary response. The test is significant (p-value = 0.0135). One or more of the model effects thus significantly affects the probability of observing an event.
Figure 54.10: Null Test
However, a look at the "Parameter Estimates" table in Figure 54.11 shows that many parameters have fairly large p-values, indicating that one or more of the model effects might not be necessary.
Figure 54.11: Parameter Estimates
| Parameter Estimates | |||||
|---|---|---|---|---|---|
| Parameter | Estimate | Standard Error |
DF | t Value | Pr > |t| |
| Intercept | 1.2101 | 1.7507 | Infty | 0.69 | 0.4894 |
| C A | 3.4341 | 1.6131 | Infty | 2.13 | 0.0333 |
| C B | 2.1638 | 1.4271 | Infty | 1.52 | 0.1295 |
| C C | 0.6552 | 1.0810 | Infty | 0.61 | 0.5445 |
| C D | 2.4945 | 1.1094 | Infty | 2.25 | 0.0245 |
| C E | 3.2449 | 1.4321 | Infty | 2.27 | 0.0235 |
| C F | 3.6054 | 1.3070 | Infty | 2.76 | 0.0058 |
| C G | 2.0841 | 1.1898 | Infty | 1.75 | 0.0798 |
| C H | 2.9368 | 1.2939 | Infty | 2.27 | 0.0232 |
| C I | 1.3785 | 1.0319 | Infty | 1.34 | 0.1816 |
| C J | 0 | . | . | . | . |
| x1 | 0.03218 | 0.05710 | Infty | 0.56 | 0.5730 |
| x2 | -0.3677 | 0.1538 | Infty | -2.39 | 0.0168 |
| x3 | 0.3146 | 0.3574 | Infty | 0.88 | 0.3787 |
| x4 | -0.05196 | 0.02443 | Infty | -2.13 | 0.0334 |
| x5 | -0.00683 | 0.01056 | Infty | -0.65 | 0.5177 |
| x6 | 0.2539 | 0.3785 | Infty | 0.67 | 0.5024 |
| x7 | -0.00723 | 0.01073 | Infty | -0.67 | 0.5004 |
| x8 | 2.5370 | 0.9942 | Infty | 2.55 | 0.0107 |
| x9 | -0.1675 | 0.1068 | Infty | -1.57 | 0.1168 |
| x10 | -0.2222 | 0.1577 | Infty | -1.41 | 0.1590 |