The LOGISTIC Procedure
- Overview
- Getting Started
-
Syntax
 PROC LOGISTIC StatementBY StatementCLASS StatementCODE StatementCONTRAST StatementEFFECT StatementEFFECTPLOT StatementESTIMATE StatementEXACT StatementEXACTOPTIONS StatementFREQ StatementID StatementLSMEANS StatementLSMESTIMATE StatementMODEL StatementNLOPTIONS StatementODDSRATIO StatementOUTPUT StatementROC StatementROCCONTRAST StatementSCORE StatementSLICE StatementSTORE StatementSTRATA StatementTEST StatementUNITS StatementWEIGHT Statement
PROC LOGISTIC StatementBY StatementCLASS StatementCODE StatementCONTRAST StatementEFFECT StatementEFFECTPLOT StatementESTIMATE StatementEXACT StatementEXACTOPTIONS StatementFREQ StatementID StatementLSMEANS StatementLSMESTIMATE StatementMODEL StatementNLOPTIONS StatementODDSRATIO StatementOUTPUT StatementROC StatementROCCONTRAST StatementSCORE StatementSLICE StatementSTORE StatementSTRATA StatementTEST StatementUNITS StatementWEIGHT Statement -
DetailsMissing ValuesResponse Level OrderingLink Functions and the Corresponding DistributionsDetermining Observations for Likelihood ContributionsIterative Algorithms for Model FittingConvergence CriteriaExistence of Maximum Likelihood EstimatesEffect-Selection MethodsModel Fitting InformationGeneralized Coefficient of DeterminationScore Statistics and TestsConfidence Intervals for ParametersOdds Ratio EstimationRank Correlation of Observed Responses and Predicted ProbabilitiesLinear Predictor, Predicted Probability, and Confidence LimitsClassification TableOverdispersionThe Hosmer-Lemeshow Goodness-of-Fit TestReceiver Operating Characteristic CurvesTesting Linear Hypotheses about the Regression CoefficientsJoint Tests and Type 3 TestsRegression DiagnosticsScoring Data SetsConditional Logistic RegressionExact Conditional Logistic RegressionInput and Output Data SetsComputational ResourcesDisplayed OutputODS Table NamesODS Graphics
-
ExamplesStepwise Logistic Regression and Predicted ValuesLogistic Modeling with Categorical PredictorsOrdinal Logistic RegressionNominal Response Data: Generalized Logits ModelStratified SamplingLogistic Regression DiagnosticsROC Curve, Customized Odds Ratios, Goodness-of-Fit Statistics, R-Square, and Confidence LimitsComparing Receiver Operating Characteristic CurvesGoodness-of-Fit Tests and SubpopulationsOverdispersionConditional Logistic Regression for Matched Pairs DataExact Conditional Logistic RegressionFirth’s Penalized Likelihood Compared with Other ApproachesComplementary Log-Log Model for Infection RatesComplementary Log-Log Model for Interval-Censored Survival TimesScoring Data SetsUsing the LSMEANS StatementPartial Proportional Odds Model
- References
This section describes the two iterative maximum likelihood algorithms that are available in PROC LOGISTIC for fitting an unconditional logistic regression. For information about available optimization techniques for conditional logistic regression and models that specify the EQUALSLOPES or UNEQUALSLOPES options, see the section NLOPTIONS Statement. Exact logistic regression uses a special algorithm, which is described in the section Exact Conditional Logistic Regression.
The default maximum likelihood algorithm is the Fisher scoring method, which is equivalent to fitting by iteratively reweighted least squares. The alternative algorithm is the Newton-Raphson method. For generalized logit models and models that specify the EQUALSLOPES or UNEQUALSLOPES options, only the Newton-Raphson technique is available. Both algorithms produce the same parameter estimates. However, the estimated covariance matrix of the parameter estimators can differ slightly because Fisher scoring is based on the expected information matrix whereas the Newton-Raphson method is based on the observed information matrix. For a binary logit model, the observed and expected information matrices are identical, resulting in identical estimated covariance matrices for both algorithms. You can specify the TECHNIQUE= option to select a fitting algorithm, and you can specify the FIRTH option to perform a bias-reducing penalized maximum likelihood fit.
Consider the multinomial variable ![]() such that
such that
With ![]() denoting the probability that the jth observation has response value i, the expected value of
denoting the probability that the jth observation has response value i, the expected value of ![]() is
is ![]() where
where ![]() . The covariance matrix of
. The covariance matrix of ![]() is
is ![]() , which is the covariance matrix of a multinomial random variable for one trial with parameter vector
, which is the covariance matrix of a multinomial random variable for one trial with parameter vector ![]() . Let
. Let ![]() be the vector of regression parameters; in other words,
be the vector of regression parameters; in other words, ![]() . Let
. Let ![]() be the matrix of partial derivatives of
be the matrix of partial derivatives of ![]() with respect to
with respect to ![]() . The estimating equation for the regression parameters is
. The estimating equation for the regression parameters is
where ![]() ,
, ![]() and
and ![]() are the weight and frequency of the jth observation, and
are the weight and frequency of the jth observation, and ![]() is a generalized inverse of
is a generalized inverse of ![]() . PROC LOGISTIC chooses
. PROC LOGISTIC chooses ![]() as the inverse of the diagonal matrix with
as the inverse of the diagonal matrix with ![]() as the diagonal.
as the diagonal.
With a starting value of ![]() , the maximum likelihood estimate of
, the maximum likelihood estimate of ![]() is obtained iteratively as
is obtained iteratively as
where ![]() ,
, ![]() , and
, and ![]() are evaluated at
are evaluated at ![]() . The expression after the plus sign is the step size. If the likelihood evaluated at
. The expression after the plus sign is the step size. If the likelihood evaluated at ![]() is less than that evaluated at
is less than that evaluated at ![]() , then
, then ![]() is recomputed by step-halving or ridging as determined by the value of the RIDGING=
option. The iterative scheme continues until convergence is obtained—that is, until
is recomputed by step-halving or ridging as determined by the value of the RIDGING=
option. The iterative scheme continues until convergence is obtained—that is, until ![]() is sufficiently close to
is sufficiently close to ![]() . Then the maximum likelihood estimate of
. Then the maximum likelihood estimate of ![]() is
is ![]() .
.
The covariance matrix of ![]() is estimated by
is estimated by
where ![]() and
and ![]() are, respectively,
are, respectively, ![]() and
and ![]() evaluated at
evaluated at ![]() .
. ![]() is the information matrix, or the negative expected Hessian matrix, evaluated at
is the information matrix, or the negative expected Hessian matrix, evaluated at ![]() .
.
By default, starting values are zero for the slope parameters, and for the intercept parameters, starting values are the observed cumulative logits (that is, logits of the observed cumulative proportions of response). Alternatively, the starting values can be specified with the INEST= option.
For cumulative models, let the parameter vector be ![]() , and for the generalized logit model let
, and for the generalized logit model let ![]() . The gradient vector and the Hessian matrix are given, respectively, by
. The gradient vector and the Hessian matrix are given, respectively, by
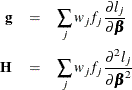
where ![]() is the log likelihood for the jth observation. With a starting value of
is the log likelihood for the jth observation. With a starting value of ![]() , the maximum likelihood estimate
, the maximum likelihood estimate ![]() of
of ![]() is obtained iteratively until convergence is obtained:
is obtained iteratively until convergence is obtained:
where ![]() and
and ![]() are evaluated at
are evaluated at ![]() . If the likelihood evaluated at
. If the likelihood evaluated at ![]() is less than that evaluated at
is less than that evaluated at ![]() , then
, then ![]() is recomputed by step-halving or ridging.
is recomputed by step-halving or ridging.
The covariance matrix of ![]() is estimated by
is estimated by
where the observed information matrix ![]() is computed by evaluating
is computed by evaluating ![]() at
at ![]() .
.
Firth’s method is currently available only for binary logistic models. It replaces the usual score (gradient) equation
where p is the number of parameters in the model, with the modified score equation
where the ![]() s are the ith diagonal elements of the hat matrix
s are the ith diagonal elements of the hat matrix ![]() and
and ![]() . The Hessian matrix is not modified by this penalty, and the optimization method is performed in the usual manner.
. The Hessian matrix is not modified by this penalty, and the optimization method is performed in the usual manner.