The CALIS Procedure
-
Overview

-
Getting Started
-
Syntax
Classes of Statements in PROC CALIS Single-Group Analysis Syntax Multiple-Group Multiple-Model Analysis Syntax PROC CALIS Statement BOUNDS Statement BY Statement COSAN Statement COV Statement DETERM Statement EFFPART Statement FACTOR Statement FITINDEX Statement FREQ Statement GROUP Statement LINCON Statement LINEQS Statement LISMOD Statement LMTESTS Statement MATRIX Statement MEAN Statement MODEL Statement MSTRUCT Statement NLINCON Statement NLOPTIONS Statement OUTFILES Statement PARAMETERS Statement PARTIAL Statement PATH Statement PCOV Statement PVAR Statement RAM Statement REFMODEL Statement RENAMEPARM Statement SAS Programming Statements SIMTESTS Statement STD Statement STRUCTEQ Statement TESTFUNC Statement VAR Statement VARIANCE Statement VARNAMES Statement WEIGHT Statement
-
Details
Input Data Sets Output Data Sets The COSAN Model The FACTOR Model The LINEQS Model The LISMOD Model and Submodels The MSTRUCT Model The PATH Model The RAM Model Naming Variables and Parameters Setting Constraints on Parameters Automatic Variable Selection Estimation Criteria Relationships among Estimation Criteria Gradient, Hessian, Information Matrix, and Approximate Standard Errors Counting the Degrees of Freedom Assessment of Fit Total, Direct, and Indirect Effects Standardized Solutions Modification Indices Missing Values and the Analysis of Missing Patterns Measures of Multivariate Kurtosis Initial Estimates Use of Optimization Techniques Computational Problems Displayed Output ODS Table Names ODS Graphics
-
Examples
Estimating Covariances and Correlations Estimating Covariances and Means Simultaneously Testing Uncorrelatedness of Variables Testing Covariance Patterns Testing Some Standard Covariance Pattern Hypotheses Linear Regression Model Multivariate Regression Models Measurement Error Models Testing Specific Measurement Error Models Measurement Error Models with Multiple Predictors Measurement Error Models Specified As Linear Equations Confirmatory Factor Models Confirmatory Factor Models: Some Variations The Full Information Maximum Likelihood Method Comparing the ML and FIML Estimation Path Analysis: Stability of Alienation Simultaneous Equations with Mean Structures and Reciprocal Paths Fitting Direct Covariance Structures Confirmatory Factor Analysis: Cognitive Abilities Testing Equality of Two Covariance Matrices Using a Multiple-Group Analysis Testing Equality of Covariance and Mean Matrices between Independent Groups Illustrating Various General Modeling Languages Testing Competing Path Models for the Career Aspiration Data Fitting a Latent Growth Curve Model Higher-Order and Hierarchical Factor Models Linear Relations among Factor Loadings Multiple-Group Model for Purchasing Behavior Fitting the RAM and EQS Models by the COSAN Modeling Language Second-Order Confirmatory Factor Analysis Linear Relations among Factor Loadings: COSAN Model Specification Ordinal Relations among Factor Loadings Longitudinal Factor Analysis
- References
| Relationships among Estimation Criteria |
There is always some arbitrariness to classify the estimation methods according to certain mathematical or numerical properties. The discussion in this section is not meant to be a thorough classification of the estimation methods available in PROC CALIS. Rather, classification is done here with the purpose of clarifying the uses of different estimation methods and the theoretical relationships of estimation criteria.
Assumption of Multivariate Normality
GLS, ML, and FIML assume multivariate normality of the data, while ULS, WLS, and DWLS do not. Although the ML method with covariance structure analysis alone can also be based on the Wishart distribution of the sample covariance matrix, for convenience GLS, ML, and FIML are usually classified as normal-theory based methods, while ULS, WLS, and DWLS are usually classified as distribution-free methods.
An intuitive or even naive notion is usually that methods without distributional assumptions such as WLS and DWLS are preferred to normal theory methods such as ML and GLS in practical situations where multivariate normality is doubt. This notion might need some qualifications because there are simply more factors to consider in judging the quality of estimation methods in practice. For example, the WLS method might need a very large sample size to enjoy its purported asymptotic properties, while the ML might be robust against the violation of multi-normality assumption under certain circumstances. No recommendations regarding which estimation criterion should be used are attempted here, but you should make your choice based more than the assumption of multivariate normality.
Contribution of the Off-Diagonal Elements to the Estimation of Covariance or Correlation Structures
If only the covariance or correlation structures are considered, the six estimation functions, 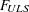 ,
, 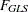 ,
, 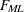 ,
, 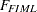 ,
, 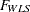 , and
, and 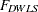 , belong to the following two groups:
, belong to the following two groups:
The functions
, , , and take into account all 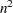 elements of the symmetric residual matrix
elements of the symmetric residual matrix 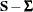 . This means that the off-diagonal residuals contribute twice to the discrepancy function
. This means that the off-diagonal residuals contribute twice to the discrepancy function 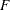 , as lower and as upper triangle elements.
, as lower and as upper triangle elements. The functions
and take into account only the 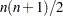 lower triangular elements of the symmetric residual matrix . This means that the off-diagonal residuals contribute to the discrepancy function only once.
lower triangular elements of the symmetric residual matrix . This means that the off-diagonal residuals contribute to the discrepancy function only once.
The function used in PROC CALIS differs from that used by the LISREL 7 program. Formula (1.25) of the LISREL 7 manual (Jöreskog and Sörbom; 1985, p. 23) shows that LISREL groups the function in the first group by taking into account all elements of the symmetric residual matrix .
Relationship between DWLS and WLS:
PROC CALIS: The and discrepancy functions deliver the same results for the special case that the weight matrix 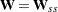 used by WLS estimation is a diagonal matrix.
used by WLS estimation is a diagonal matrix.
LISREL 7: This is not the case.-
Relationship between DWLS and ULS:
LISREL 7: The and estimation functions deliver the same results for the special case that the diagonal weight matrix used by DWLS estimation is an identity matrix.
PROC CALIS: To obtain the same results with and estimation, set the diagonal weight matrix used in DWLS estimation to: 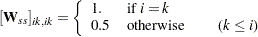
Because the reciprocal elements of the weight matrix are used in the discrepancy function, the off-diagonal residuals are weighted by a factor of 2.
ML and FIML Methods
Both the ML and FIML methods can be derived from the log-likelihood function for multivariate normal data. The preceding section Estimation Criteria mentions that is essentially the same as 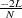 , where
, where 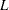 is the log-likelihood function for multivariate normal data. For the ML estimation, you can also consider as a part of the discrepancy function that contains the information regarding the model parameters (while the rest the function contains some constant terms given the data). That is, with some algebraic manipulations and assuming that there is no missing value in the analysis (so that all
is the log-likelihood function for multivariate normal data. For the ML estimation, you can also consider as a part of the discrepancy function that contains the information regarding the model parameters (while the rest the function contains some constant terms given the data). That is, with some algebraic manipulations and assuming that there is no missing value in the analysis (so that all 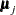 and
and 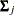 are the same as
are the same as 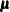 and
and 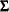 , respectively), it can shown that
, respectively), it can shown that
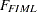 |
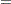 |
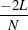 |
|||
 |
|
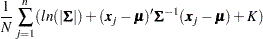 |
|||
|
|
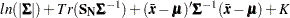 |
where 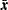 is the sample mean and
is the sample mean and 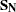 is the biased sample covariance matrix. Compare this FIML function with the ML function shown in the following expression, which shows that both functions are very similar:
is the biased sample covariance matrix. Compare this FIML function with the ML function shown in the following expression, which shows that both functions are very similar:
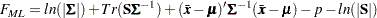 |
The two expressions differ only in the constant terms, which are independent of the model parameters, and in the formulas for computing the sample covariance matrix. While the FIML method assumes the biased formula (with 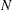 as the divisor, by default) for the sample covariance matrix, the ML method (as implemented in PROC CALIS) uses the unbiased formula (with
as the divisor, by default) for the sample covariance matrix, the ML method (as implemented in PROC CALIS) uses the unbiased formula (with 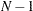 as the divisor, by default).
as the divisor, by default).
The similarity (or dissimilarity) of the ML and FIML discrepancy functions leads to some useful conclusions here:
Because the constant terms in the discrepancy functions play no part in parameter estimation (except for shifting the function values), overriding the default ML method with VARDEF=N (that is, using
as the divisor in the covariance matrix formula) leads to the same estimation results as that of the FIML method, given that there are no missing values in the analysis. Because the FIML function is evaluated at the level of individual observations, it is much more expensive to compute than the ML function. As compared with ML estimation, FIML estimation takes longer and uses more computing resources. Hence, for data without missing values, the ML method should always be chosen over the FIML method.
The advantage of the FIML method lies solely in its ability to handle data with random missing values. While the FIML method uses the information maximally from each observation, the ML method (as implemented in PROC CALIS) simply throws away any observations with at least one missing value. If it is important to use the information from observations with random missing values, the FIML method should be given consideration over the ML method.
See Example 26.14 for an application of the FIML method and Example 26.15 for an empirical comparison of the ML and FIML methods.