The NLP Procedure
- Overview
-
Getting Started

-
SyntaxFunctional SummaryDictionary of OptionsPROC NLP StatementARRAY StatementBOUNDS StatementBY StatementCRPJAC StatementDECVAR StatementGRADIENT StatementHESSIAN StatementINCLUDE StatementJACNLC StatementJACOBIAN StatementLABEL StatementLINCON StatementMATRIX StatementMIN, MAX, and LSQ StatementsMINQUAD and MAXQUAD StatementsNLINCON StatementPROFILE StatementProgram Statements
-
DetailsCriteria for OptimalityOptimization AlgorithmsFinite-Difference Approximations of DerivativesHessian and CRP Jacobian ScalingTesting the Gradient SpecificationTermination CriteriaActive Set MethodsFeasible Starting PointLine-Search MethodsRestricting the Step LengthComputational ProblemsCovariance MatrixInput and Output Data SetsDisplayed OutputMissing ValuesComputational ResourcesMemory LimitRewriting NLP Models for PROC OPTMODEL
-
Examples
- References
Since nonlinear optimization is an iterative process that depends on many factors, it is difficult to estimate how much computer time is necessary to compute an optimal solution satisfying one of the termination criteria. The MAXTIME=, MAXITER=, and MAXFUNC= options can be used to restrict the amount of real time, the number of iterations, and the number of function calls in a single run of PROC NLP.
In each iteration ![]() , the NRRIDG and LEVMAR techniques use symmetric Householder transformations to decompose the
, the NRRIDG and LEVMAR techniques use symmetric Householder transformations to decompose the ![]() Hessian (crossproduct Jacobian) matrix
Hessian (crossproduct Jacobian) matrix ![]() ,
,
to compute the (Newton) search direction ![]() :
:
The QUADAS, TRUREG, NEWRAP, and HYQUAN techniques use the Cholesky decomposition to solve the same linear system while computing the search direction. The QUANEW, DBLDOG, CONGRA, and NMSIMP techniques do not need to invert or decompose a Hessian or crossproduct Jacobian matrix and thus require fewer computational resources then the first group of techniques.
The larger the problem, the more time is spent computing function values and derivatives. Therefore, many researchers compare optimization techniques by counting and comparing the respective numbers of function, gradient, and Hessian (crossproduct Jacobian) evaluations. You can save computer time and memory by specifying derivatives (using the GRADIENT, JACOBIAN, CRPJAC, or HESSIAN statement) since you will typically produce a more efficient representation than the internal derivative compiler.
Finite-difference approximations of the derivatives are expensive since they require additional function or gradient calls.
-
Forward-difference formulas:
-
First-order derivatives:
 additional function calls are needed.
additional function calls are needed.
-
Second-order derivatives based on function calls only: for a dense Hessian,
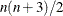 additional function calls are needed.
additional function calls are needed.
-
Second-order derivatives based on gradient calls:
additional gradient calls are needed.
-
-
Central-difference formulas:
-
First-order derivatives:
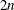 additional function calls are needed.
additional function calls are needed.
-
Second-order derivatives based on function calls only: for a dense Hessian,
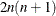 additional function calls are needed.
additional function calls are needed.
-
Second-order derivatives based on gradient:
additional gradient calls are needed.
-
Many applications need considerably more time for computing second-order derivatives (Hessian matrix) than for first-order derivatives (gradient). In such cases, a (dual) quasi-Newton or conjugate gradient technique is recommended, which does not require second-order derivatives.
The following table shows for each optimization technique which derivatives are needed (FOD: first-order derivatives; SOD:
second-order derivatives), what kinds of constraints are supported (BC: boundary constraints; LIC: linear constraints), and
the minimal memory (number of double floating point numbers) required. For various reasons, there are additionally about ![]() double floating point numbers needed.
double floating point numbers needed.
|
Quadratic Programming |
FOD |
SOD |
BC |
LIC |
Memory |
|
LICOMP |
- |
- |
x |
x |
|
|
QUADAS |
- |
- |
x |
x |
|
|
General Optimization |
FOD |
SOD |
BC |
LIC |
Memory |
|
TRUREG |
x |
x |
x |
x |
|
|
NEWRAP |
x |
x |
x |
x |
|
|
NRRIDG |
x |
x |
x |
x |
|
|
QUANEW |
x |
- |
x |
x |
|
|
DBLDOG |
x |
- |
x |
x |
|
|
CONGRA |
x |
- |
x |
x |
|
|
NMSIMP |
- |
- |
x |
x |
|
|
Least Squares |
FOD |
SOD |
BC |
LIC |
Memory |
|
LEVMAR |
x |
- |
x |
x |
|
|
HYQUAN |
x |
- |
x |
x |
|
Notes:
-
Here,
denotes the number of parameters, 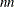 the squared number of parameters, and
the squared number of parameters, and 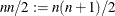 .
.
-
The value of
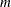 is the product of the number of functions specified in the MIN, MAX, or LSQ statement and the maximum number of observations in each BY group of a DATA= input data set. The following table also contains the number
is the product of the number of functions specified in the MIN, MAX, or LSQ statement and the maximum number of observations in each BY group of a DATA= input data set. The following table also contains the number  of variables in the DATA= data set that are used in the program statements.
of variables in the DATA= data set that are used in the program statements.
-
For a diagonal Hessian matrix, the
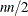 term in QUADAS, TRUREG, NEWRAP, and NRRIDG is replaced by .
term in QUADAS, TRUREG, NEWRAP, and NRRIDG is replaced by .
-
If the TRUREG, NRRIDG, or NEWRAP method is used to minimize a least squares problem, the second derivatives are replaced by the crossproduct Jacobian matrix.
-
The memory needed by the TECH=NONE specification depends on the output specifications (typically, it needs
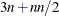 double floating point numbers and an additional
double floating point numbers and an additional 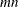 if the Jacobian matrix is required).
if the Jacobian matrix is required).
The total amount of memory needed to run an optimization technique consists of the technique-specific memory listed in the preceding table, plus additional blocks of memory as shown in the following table.
|
double |
int |
long |
8byte |
|
|
Basic Requirement |
|
|
|
|
|
DATA= data set |
|
- |
- |
|
|
JACOBIAN statement |
|
- |
- |
- |
|
CRPJAC statement |
|
- |
- |
- |
|
HESSIAN statement |
|
- |
- |
- |
|
COV= option |
|
- |
- |
- |
|
Scaling vector |
|
- |
- |
- |
|
BOUNDS statement |
|
|
- |
- |
|
Bounds in INEST= |
|
- |
- |
- |
|
LINCON and TRUREG |
|
|
- |
- |
|
LINCON and other |
|
|
- |
- |
Notes:
-
For TECH=LICOMP, the total amount of memory needed for the linear or boundary constrained case is
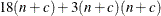 , where
, where  is the number of constraints.
is the number of constraints.
-
The amount of memory needed to specify derivatives with a GRADIENT, JACOBIAN, CRPJAC, or HESSIAN statement (shown in this table) is small compared to that needed for using the internal function compiler to compute the derivatives. This is especially so for second-order derivatives.
-
If the CONGRA technique is used, specifying the GRADCHECK=DETAIL option requires an additional
double floating point numbers to store the finite-difference Hessian matrix.