IMSTAT Procedure (Data and Server Management)
- Syntax
 Procedure SyntaxPROC IMSTAT (Data and Server Management) StatementBALANCE StatementCOLUMNINFO StatementCOMPRESS StatementCOMPUTE StatementCREATETABLE StatementDELETEROWS StatementDISTRIBUTIONINFO StatementDROPCOLUMN StatementDROPTABLE StatementFETCH StatementFREE StatementLIFETIME StatementNUMROWS StatementPARTITION StatementPARTITIONINFO StatementPROMOTE StatementPURGETEMPTABLES StatementREPLAY StatementSAVE StatementSCHEMA StatementSCORE StatementSERVERINFO StatementSERVERPARM StatementSERVERTERM StatementSERVERWAIT StatementSET StatementSTORE StatementTABLE StatementTABLEINFO StatementUNCOMPRESS StatementUPDATE StatementQUIT Statement
Procedure SyntaxPROC IMSTAT (Data and Server Management) StatementBALANCE StatementCOLUMNINFO StatementCOMPRESS StatementCOMPUTE StatementCREATETABLE StatementDELETEROWS StatementDISTRIBUTIONINFO StatementDROPCOLUMN StatementDROPTABLE StatementFETCH StatementFREE StatementLIFETIME StatementNUMROWS StatementPARTITION StatementPARTITIONINFO StatementPROMOTE StatementPURGETEMPTABLES StatementREPLAY StatementSAVE StatementSCHEMA StatementSCORE StatementSERVERINFO StatementSERVERPARM StatementSERVERTERM StatementSERVERWAIT StatementSET StatementSTORE StatementTABLE StatementTABLEINFO StatementUNCOMPRESS StatementUPDATE StatementQUIT Statement - Overview
- Concepts
- Examples
SCORE Statement
The SCORE statement applies scoring rules to an in-memory table. The results can take different forms. They can be displayed as tables in the SAS session, output data sets on the client, or temporary tables in the server. The most common use of the SCORE statement is to execute DATA step code on some or all rows of an in-memory table and to produce corresponding output records.
| Requirement: | The program that you use with the SCORE statement must use DATA step syntax. DS2 syntax is not supported. |
| Note: | There are some restrictions on the DATA step statements that you can use with the SCORE statement. See Restrictions in DATA Step Processing for information. |
| Examples: | Joining Data during Scoring with a DATA Step Hash Object |
Syntax
Required Argument
CODE=file-reference
specifies a file reference to the SAS program that performs the scoring.
| Alias | PGM= |
SCORE Statement Options
DROP=(variable-list)
DROP=variable-name
specifies one or more variables that you want to drop from the input data when transferring results to the scoring results. By default, the SCORE statement does not transfer any variables from the input table to the scoring results. If you specify the KEEP= option, only the specified variables are moved to the result. If you specify the DROP= option, all variables except the specified variables are moved to the result set.
| Interaction | Do not use the DROP= and KEEP= options together. The KEEP= option takes precedence. |
DSRETAIN
requests that the scoring code implements DATA step retention behavior for output symbols. By default, the server automatically retains output variables, whereas the DATA step sets variables to missing unless they are retained explicitly with a RETAIN statement. Specifying this option means that the automatic retention behavior is disabled in the server and you must specify RETAIN statements in your DATA step program to retain values.
| Alias | NOAUTORETAIN |
HASHDATA(table-name1 <, table-name2...>)
specifies the names of one or more in-memory tables in server that are used as input tables for DATA step hash objects. The names are the actual table names in the server, not names where tags are masked by the libref. The names must match the names that you use in the DECLARE HASH statements in the scoring program.
| Alias | HASH |
| Example | Joining Data during Scoring with a DATA Step Hash Object |
KEEP=(variable-list)
KEEP=variable-name
specifies one or more variables that you want to transfer from the input data to the scoring results. You can use _ALL_ for all variables, _NUMERIC_ for all numeric variables, and other valid variable list names. If this option is not specified, then no variables are transferred from the input data (the table that is being scored), unless they are assigned values in the scoring code.
| Alias | TABLEVARS= |
NOPREPARSE
specifies to prevent pre-parsing and pre-generating the program code that is referenced in the CODE= option. If you know the code is correct, you can specify this option to save resources. The code is always parsed by the server, but you might get more detailed error messages when the procedure parses the code rather than the server. The server assumes that the code is correct. If the code fails to compile, the server indicates that it could not parse the code, but not where the error occurred.
| Alias | NOPREP |
OUT=libref.member-name
specifies the name of an output data set in which to store the scoring results. If the result set contains variables that match those in the input data set, then format information is transferred to the output data set. The OUT= option and the TEMPTABLE option are mutually exclusive. If you specify the OUT= option, a temporary table is not created in the server.
| Alias | DATA= |
PARTITION <=partition-key>
specifies to take advantage
of partitioning for tables that are partitioned. When this option
is specified, the scoring code is executed in the order of the partitions.
If the data are also ordered within the partition, the observations
are processed in that order. If the scoring code uses the reserved
symbols __first_in_partition or __last_in_partition,
then the data are also processed in partitioned order. Although the
observations are processed in a specific order, the execution occurs
in concurrent threads (in parallel). Different threads are assigned
to work on different partitions.
score / partition="F 11"; /* passed directly to the server */ score / partition="F","11"; /* composed by the procedure */
| Alias | PART= |
| Interaction | This option is effective when used with partitioned in-memory tables only. |
SAVE=table-name
saves the result table so that you can use it in other IMSTAT procedure statements like STORE, REPLAY, and FREE. The value for table-name must be unique within the scope of the procedure execution. The name of a table that has been freed with the FREE statement can be used again in subsequent SAVE= options.
SETSIZE
requests that the server estimate the size of the result set. The procedure does not create a result table if the SETSIZE option is specified. Instead, the procedure reports the number of rows that are returned by the request and the expected memory consumption for the result set (in KB). If you specify the SETSIZE option, the SAS log includes the number of observations and the estimated result set size. See the following log sample:
NOTE: The LASR Analytic Server action request for the STATEMENT
statement would return 17 rows and approximately
3.641 kBytes of data.SYMBOLS=(symbol-list)
specifies one or more symbols that are calculated in the scoring code that you want to transfer as columns to the scoring results. If the SYMBOLS= option is not specified, then all symbols that are assigned values in the program—and that are not just placeholders for intermediate calculations—are transferred to the results. If you use a large program with many assignments, you might want to use the SYMBOLS= option to limit the columns in the results.
| Alias | SYM= |
TEMPTABLE
generates an in-memory temporary table from the result set. The IMSTAT procedure displays the name of the table and stores it in the _TEMPLAST_ macro variable, provided that the statement executed successfully.
Details
Using Partitioning and Scoring
__lasr_output symbol
in your SAS program. When this symbol is set to 1, the row is output.
You can also use the __first_in_partition and __last_in_partition variables
to programmatically determine the first and last observation in a
partition.
__lasr_output = 0; if __first_in_partition then do; 1 totalmsrp = msrp; minmsrp = msrp; numCars = 1; end; else do; totalmsrp + msrp; numCars + 1; if (msrp < minmsrp) then minmsrp = msrp; end; orgdrive = Origin || drivetrain; 2 mpgdiff = mpg_highway - mpg_city; if __last_in_partition then 3 __lasr_output = 1;
| 1 | For the first observation within a partition, three variables are initialized. The minimum MSRP, the total MSRP, and the number of records in the partition are then computed. |
| 2 | The variable ORGDRIVE is obtained by concatenating the strings of the ORIGIN and DRIVETRAIN variables |
| 3 | When
the last record within the partition is reached, the __lasr_output automatic
variable is set to 1, this is used to add of the current record to
the result set.
|
data lasrlib.cars(partition=(type));
set sashelp.cars;
run;
filename fref '/path/to/scorepgm.sas';
proc imstat;
table lasrlib.cars;
score pgm=fref / partition;
run;
Scoring Results for Table WORK.CARS
totalmsrp minmsrp numCars orgdrive mpgdiff Type
59760 19110 3.000000 Asia Front -8.000000 Hybrid
2087415 17163 60.000000 EuropeAll 5.000000 SUV
7800688 10280 262.000000 EuropeFront 7.000000 Sedan
2615966 18345 49.000000 Asia Rear 6.000000 Sports
598593 12800 24.000000 Asia All 3.000000 Truck
865216 11905 30.000000 EuropeAll 7.000000 Wagon
ODS Table Names
|
ODS Table Name
|
Description
|
Option
|
|---|---|---|
|
TempTable
|
Information about a
temporary table
|
TEMPTABLE
|
|
Fetch
|
Fetching rows from the
table of a LASR Analytic Server
|
Default, when TEMPTABLE
is not specified
|
Examples
Example 1: Joining Data during Scoring with a DATA Step Hash Object
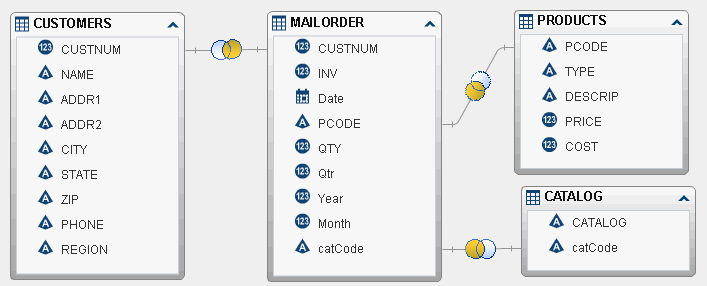
-
MailOrder is the fact table.
-
Customers joins to MailOrder on the CustNum column.
-
Products joins to MailOrder on the PCode column.
-
Catalog joins to MailOrder on the CatCode column.
Scoring Program
length catcode $6; 1 length pcode $6; length catalog $20; length type $15; length name $32; length city $20; length state $3 ; length cost 8 ; length price 8 ; declare hash cst(dataset:"star.customers"); 2 rc = cst.defineKey ('custnum'); 3 rc = cst.defineData('name' ); 4 rc = cst.defineData('city' ); rc = cst.defineData('state' ); rc = cst.defineDone(); rc_cst = cst.find(); if ((rc_cst=0) and (state = 'NJ ')) then do; 5 declare hash cat(dataset:"star.catalog"); rc = cat.defineKey ('catcode'); rc = cat.defineData('catalog'); rc = cat.defineDone(); declare hash prd(dataset:"star.products"); rc = prd.defineKey ('pcode'); rc = prd.defineData('type' ); rc = prd.defineData('price'); rc = prd.defineData('cost' ); rc = prd.defineDone(); rc_cat = cat.find(); rc_prd = prd.find(); if (rc_cat=0 and rc_prd=0) then output; 6 end;
| 1 | The LENGTH statements define the variables that are accessed from the dimension tables through the hash objects. The specified types and lengths must match the data types and lengths in the dimension tables. |
| 2 | Three hash objects are declared in the program, one for each dimension table. The DECLARE HASH statement defines and names the object. The DATASET option specifies the in-memory table to use for populating the hash object. The names specified in the program code are the actual table names in the server, and not the names where a libref masks the tag. |
| 3 | The DEFINEKEY function defines the key for the hash object. The keys in the example are the same that would be used in a star schema to join the dimension tables to the fact table. |
| 4 | The DEFINEDATA function lists the columns from the dimension tables that you want to make available to the scoring step through the hash object. |
| 5 | Because this example uses the STATE variable as a filter, the program determines whether a record matches New Jersey first. Only then does the program look for matching records in the other hash objects. The FIND function is used to locate a matching record for the particular hash object. The code compares the State variable against the literal 'NJ ' after the CST.FIND() call. Otherwise, the State variable would not have been updated with the value that corresponds to the current record in the fact table. |
| 6 | A record that passes the filter and can be successfully looked up in the hash objects is output to the scoring result set. |
filename fref './hash_schema.txt'; 1 proc imstat; table lasr.mailorder; score pgm=fref hashdata(star.catalog, 2 star.products, star.customers) symbols(catalog cost price type name city state) 3 keep (date year) temptable; 4 run;
| 1 | The
scoring program is saved in a file that is named hash_schema.txt.
The file is referenced with a FILENAME statement.
|
| 2 | The HASHDATA option specifies the names of the dimension tables. In this example, the table names do not match the libref that is used for accessing the fact table. Specify the tables in the HASHDATA option as they are shown in the results of the TABLEINFO / HOST="hostname.example.com" PORT=number statement. The names in the DATASET options in the DECLARE HASH statements of the scoring program must match. |
| 3 | The SYMBOLS option specifies the columns to transfer from the dimension tables to the result set. Although these are columns in an in-memory table, they are not columns in the active table, and therefore must be transferred explicitly to the result set. The KEEP option specifies the columns from the active table, MailOrder, to transfer to the result set. |
| 4 | The TEMPTABLE option specifies to store the result set as an in-memory table. Otherwise, the result set is transferred to your SAS session. |
Example 2: Using the RETAIN Statement
-
The active table must be partitioned by one or more variables.
-
The active table must be ordered by one or more variables.
-
You must specify the DSRETAIN option and the PARTITION option.
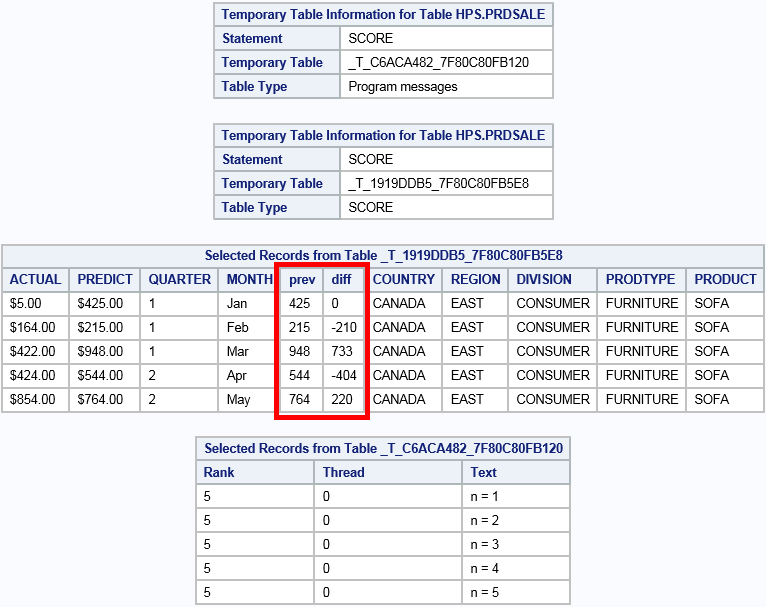
libname example host="grid001.example.com" port=10010 tag="hps"; data example.prdsale(partition=(COUNTRY REGION DIVISION PRODTYPE PRODUCT) orderby=(year month)); set sashelp.prdsale; run; filename ret "/data/retain.pgm"; data _null_; file "/data/retain.pgm"; put "retain prev;"; 1 put "if __first_in_partition then do;"; put " prev = predict;"; put "end;"; put "diff = predict - prev;"; put "prev = predict;"; put "put 'n = ' _n_;"; 2 run; proc imstat pgmmsg; 3 table example.prdsale; score code=ret dsretain temptable keep=(actual predict quarter month) partition="CANADA", "EAST", "CONSUMER", "FURNITURE", "SOFA"; 4 run; table example.&_TEMPLAST_; fetch / format to=5; run; table example.&_PGMMSG_; fetch / format to=5; run;
| 1 | The RETAIN statement is used in the DATA step program to submit to the server. |
| 2 | The PUT statement is not necessary for the analysis. It is included in the example to demonstrate how a PUT statement adds records to the &_PGMMSG_ temporary table instead of the SAS log. |
| 3 | The PGMMSG option is required for the server to create the &_PGMMSG_ table. |
| 4 | The
SCORE statement includes the DSRETAIN option so that only the variables
specified in a RETAIN statement are retained. The TEMPTABLE option
is used to generate a temporary table for the scored results. The
PARTITION option is required in order to use the __first_in_partition variable.
In this example, it also specifies the partition to score. This can
be used to avoid computing values for partitions that you are not
interested in.
|