Usage Note 70221: Estimate and plot the effect of changing a continuous predictor in a spline
 |  |  |
When a continuous predictor in a model has an unknown, complex association with the response, one common approach is to include higher-order effects of the predictor (quadratic, cubic, and so on) in the model. These polynomial effects can capture aspects of the complexity of the predictor's association, but the shapes that they can accommodate are limited. A more flexible approach is to use a spline effect to represent the predictor. A spline is a series of piecewise polynomials joined at points called knots. You can use the EFFECT statement to define splines for one or more predictors in your model. The EFFECT statement offers many ways to define a spline. See "EFFECT Statement: Spline Effects" in the "Shared Concepts and Topics" chapter of the SAS/STAT User's Guide. See also SAS Note 57975 for more on using spline effects.
Tools for assessing a continuous variable involved in interactions, with and without splines, are discussed further in SAS Note 67024. As described there, the Margins macro (SAS Note 63038) is generally the most useful tool. However, that macro does not support some models including models with constructed effects such as splines.
After fitting a model that includes a spline effect for a continuous predictor, it is often of interest to plot the association of the spline and the estimated response mean. This can be done using either the PLOTS= option or the EFFECTPLOT statement in the modeling procedure, if available. Alternatively, if the procedure offers the STORE statement, you can use the STORE statement followed by the EFFECTPLOT statement in PROC PLM.
In addition, you might want to estimate the effect of changing the original predictor by one or more units and plot how that effect changes across the predictor's range. For a categorical predictor, the effect of changing it can be assessed using the LSMEANS and related statements, but those statements do not operate on continuous predictors. When the effect measure is the response mean difference over a one unit change, it approximates the slope of a line drawn tangent to the spline curve at each setting of the original predictor and any other predictors in the model. This is the marginal effect of the predictor. For a binary response model such as a logistic model, the odds ratio or relative risk (prevalence ratio) might be the preferred effect measure to be estimated and plotted as it changes over the original predictor.
The following illustrates how these plots can be obtained.
Plot the Change in the Odds Ratio over a Splined Predictor
For a binary response model, such as a logistic model, the odds ratio is typically a statistic of interest that assesses how a unit change in a predictor changes the odds of the response event. If the predictor appears as a main effect in the model, its estimated odds ratio is a single value. But if the predictor is represented in the model by a spline effect, the odds ratio changes at each level of the original predictor.
The ODDSRATIO statement in PROC LOGISTIC can present a plot of the changing odds ratio estimates along with confidence limits at each requested value. Without the PLOTS= option, it presents the plot in a vertical orientation. To get the more usual horizontal orientation, add the PLOTS= option as shown below.
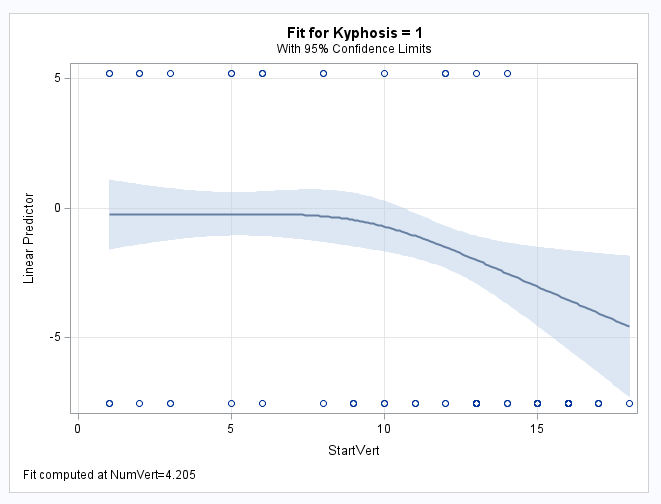
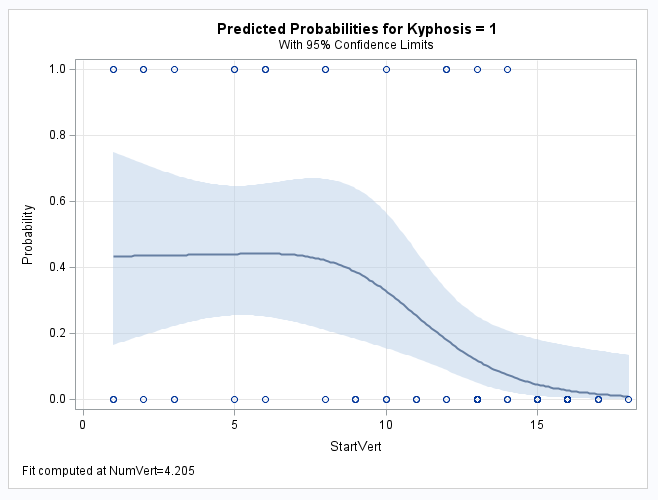
The following example uses the Kyphosis data in the example titled "Generalized Additive Model with Binary Data" in the PROC GAM documentation. The EFFECT statement defines a natural (or restricted) cubic spline on the StartVert predictor and includes it in the model along with another predictor, NumVert. The first EFFECTPLOT statement plots the spline against the predicted event probability over the range of StartVert. The second EFFECTPLOT statement with the LINK option does the same but with the log odds (or logit, which is the linear predictor) on the vertical axis. The ODDSRATIO statement provides a table and plot of the odds ratio estimates for StartVert over the range from 2 to 15. The PLOTS= option uses the TYPE= suboption to change the orientation of the plot. The STORE statement saves the fitted model for use in the next example.
proc logistic data=kyphosis plots(only)=oddsratio(type=vertical);
effect SplSV=spline(StartVert/naturalcubic);
model Kyphosis(event="1") = SplSV NumVert;
effectplot fit(x=StartVert);
effectplot fit(x=StartVert) / link;
oddsratio StartVert / at(StartVert=2 to 15);
store kmod;
ods output orplot=or;
run;
The first two plots from the EFFECTPLOT statements show how the spline on StartVert is associated with the event probability and the log odds of the event (the linear predictor). As noted at the bottom of the plots from the EFFECTPLOT statements, the plots control for NumVert by holding NumVert at its mean. The plot from the ODDSRATIO statement shows how the event odds change for a unit increase in StartVert for unit increases starting at each of the specified values. Notice in the second plot how a unit increase in StartVert has almost zero change on the log odds from 2 to 6. Since the difference in log odds is a log odds ratio, a zero log odds ratio translates to an odds ratio estimate of 1 by exponentiation and that is what the ODDSRATIO plot shows for StartVert values from 2 to 6 where the log odds plot begins to drop, which translates to the odds ratio becoming less than 1. From about StartVert=12, that drop is constant implying that the odds ratio stays approximately the same - at about 0.6:
 |
 |
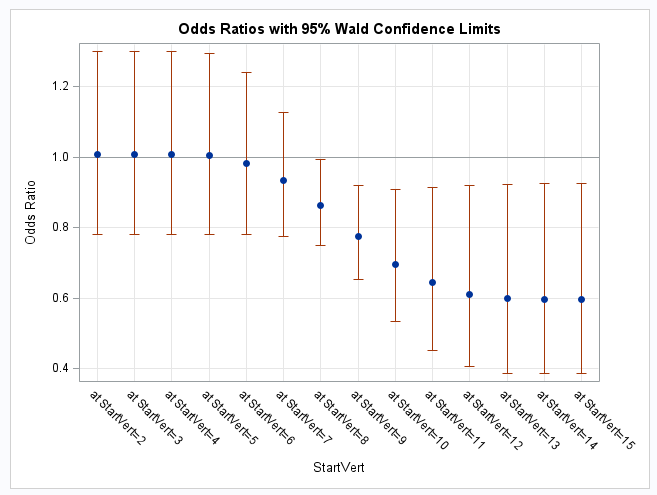 |
Instead of using bars for the individual odds ratios as above, the odds ratios can be displayed as a curved line fitted to the odds ratios and a confidence band. This can be done by adding an ODS OUTPUT statement to save the data that produces the plot and then using the capabilities of PROC SGPLOT to redraw the plot as desired. This is one of the methods for modifying ODS graphs discussed in SAS Note 24529.
Using the odds ratio plot data saved by the ODS OUTPUT statement above, the following statements create a numeric variable, XVAL, containing the value of StartVert that appears in the text labels on the horizontal axis in the above odds ratio plot. Then, in PROC SGPLOT, the BAND and SERIES statements are used with the appropriate variables in the saved plot data to create the desired plot.
data or; set or(where=(displaylabel ? 'StartVert'));
length xval 8;
xval=scan(displaylabel,-1,'=');
run;
proc sgplot noautolegend;
band upper=uppercldisplay lower=lowercldisplay
x=xval / transparency=.5;
series y=oddsratioestdisplay x=xval;
xaxis label='Startvert start point' grid;
yaxis label='Odds Ratio' grid;
refline 1 / axis=y;
title "Odds Ratios with 95% Wald Confidence Limits";
run;
 |
Estimate and Plot the Risk Difference over a Splined Predictor
In the previous model, suppose that the effect of changing StartVert on the risk difference—that is, the difference in the probability of kyphosis—is of interest rather than the odds ratio. Note that the event probability is the response mean in a logistic model. Since the model does not use the identity link, you can use the following method that employs the NLMeans macro (SAS Note 62362). This method can similarly be used for estimating and plotting differences in means for other generalized linear models that do not use the identity link.
These statements use the saved model to provide the predicted mean values at the desired StartVert values and with NumVert fixed at its mean:
data chk;
do StartVert=2 to 15; output; end;
run;
proc summary data=kyphosis;
var NumVert;
output out=mns(keep=NumVert) mean=;
run;
data chk; set chk;
if _n_=1 then set mns;
run;
proc plm restore=kmod;
score data=chk out=chk2 predicted stderr uclm lclm / ilink;
run;
The LSMEANS statement cannot be used for comparisons among levels of a continuous predictor. However, by duplicating the data and creating a dummy categorical variable with one value in each duplicate, the LSMEANS statement can be used for the dummy variable to generate the coefficients needed in the NLMeans macro to compare the StartVert levels. As is the default with the LSMEANS statement, the coefficients for any categorical covariate are equal proportions across its levels and for continuous covariates are set at their means. The E option produces the coefficients tables, and the ODS OUTPUT statement saves them in data set C. Since the analysis results should otherwise be ignored, the ODS EXCLUDE and ODS SELECT statements are used to suppress their display:
data k2;
set kyphosis(in=in1) kyphosis;
dummy=in1;
run;
ods exclude all;
proc logistic data=k2;
class dummy / param=glm;
effect SplSV=spline(StartVert/naturalcubic);
model Kyphosis(event="1") = dummy SplSV NumVert;
lsmeans dummy / at StartVert=2 e;
lsmeans dummy / at StartVert=3 e;
lsmeans dummy / at StartVert=4 e;
lsmeans dummy / at StartVert=5 e;
lsmeans dummy / at StartVert=6 e;
lsmeans dummy / at StartVert=7 e;
lsmeans dummy / at StartVert=8 e;
lsmeans dummy / at StartVert=9 e;
lsmeans dummy / at StartVert=10 e;
lsmeans dummy / at StartVert=11 e;
lsmeans dummy / at StartVert=12 e;
lsmeans dummy / at StartVert=13 e;
lsmeans dummy / at StartVert=14 e;
lsmeans dummy / at StartVert=15 e;
ods output coef=c(drop=row2 where=(parameter ^? "dummy"));
run;
ods select all;
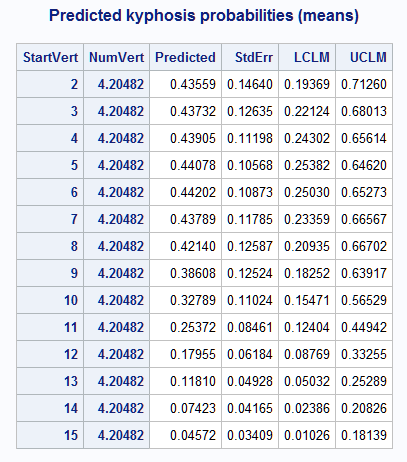
The following PRINT step displays the predicted means at each StartVert level and at mean NumVert. The NLMeans macro call reads the original saved model and the coefficients generated in the previous step to compute the differences between successive pairs of means as specified by diff=seq. Since the original model is a logistic model, link=logit is specified. Because the coefficients come from multiple LSMEANS statements, options=joint is specified so that comparisons can be made among all of the coefficient sets. To compute the differences as the effects of increasing StartVert, reverse is also specified in options=:
proc print data=chk2;
id StartVert Numvert;
title "Predicted kyphosis probabilities (means)";
run;
%nlmeans(instore=kmod, coef=c, link=logit, diff=seq, options=joint reverse)
In the Label column in the NLMeans results, "1" in the kth position and "-1" in the (k-1)st position indicate that the (k-1)st mean in the previous table of means is subtracted from the kth mean forming the risk difference estimate in the Estimate column. So, 0.0017 is the risk difference from increasing StartVert from 2 to 3 and -0.0285 is the risk difference from an increase from 14 to 15:
 |
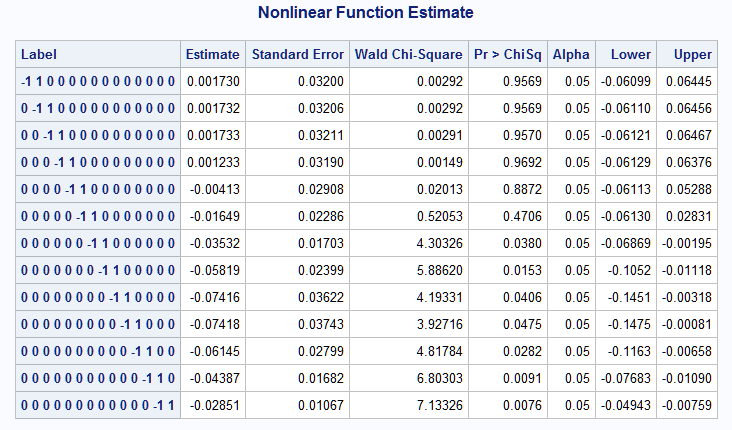 |
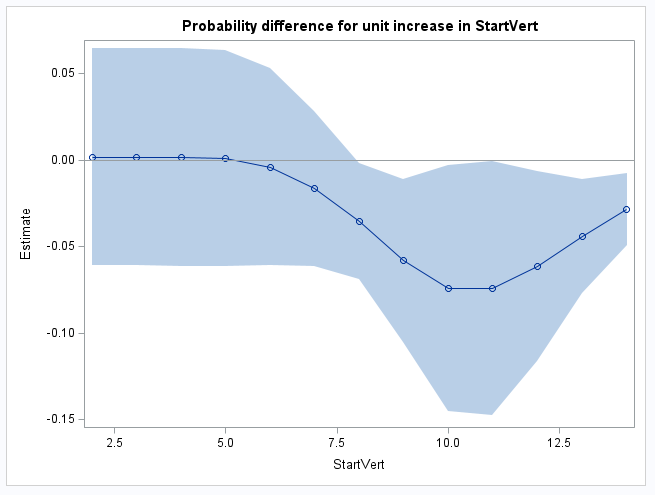
The NLMeans macro automatically saves its results in a data set named EST. The following DATA step adds the StartVert values that begin each one unit increase from the previous data set of predicted means. The differences in response mean (probability of kyphosis) are then plotted using PROC SGPLOT:
data kplot; merge chk est(in=inest);
if inest then output;
run;
proc sgplot data=kplot noautolegend;
band upper=upper lower=lower x=StartVert;
scatter y=estimate x=StartVert;
series y=estimate x=StartVert;
refline 0;
title "Probability difference for unit increase in StartVert";
run;
 |
Estimate and Plot the Relative Risk over a Splined Predictor
Now suppose that the effect of changing StartVert on the relative risk—that is, the ratio of kyphosis probabilities—is of interest rather than the odds ratio or risk difference. The NLMeans macro can again be used just by adding ratio in options=. This method can be used for estimating and plotting ratios of means for any generalized linear model that does not use the identity link:
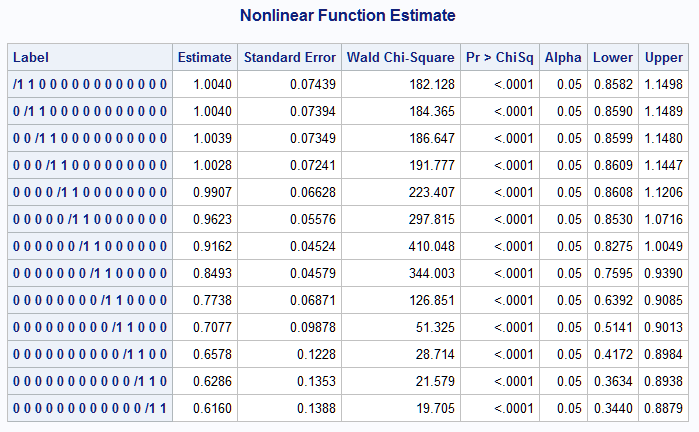
%nlmeans(instore=kmod, coef=c, link=logit, diff=seq, options=joint ratio reverse)
data kplot; merge chk est(in=inest);
if inest then output;
run;
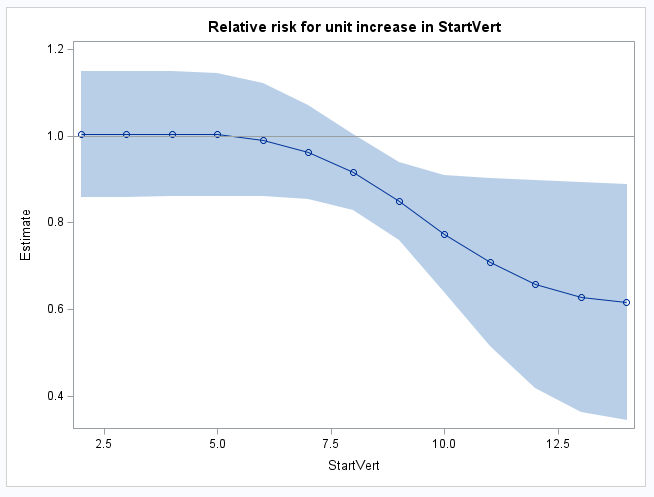
proc sgplot data=kplot noautolegend;
band upper=upper lower=lower x=StartVert;
scatter y=estimate x=StartVert;
series y=estimate x=StartVert;
refline 1;
title "Relative risk for unit increase in StartVert";
run;
In the Label column, similar to the table of differences above, "1" in the kth position and "/1" in the (k-1)st position indicate that the kth mean in the previous table of means is the numerator and the (k-1)st mean is the denominator forming the relative risk estimate in the Estimate column:
 |
 |
Estimate and Plot the Mean Difference in an Ordinary Regression Model
In the following example, the GLMSELECT procedure is used to model the logSalary variable in the SASHELP.BASEBALL data set. Ordinary regression models similar to this model the response mean directly, which is equivalent to a generalized linear model using the normal distribution and identity link. In models with an identity link, the NLMeans macro cannot be used as above, but the mean difference can be estimated using the ESTIMATE statement. When the model includes a spline effect, it is easiest to use the nonpositional syntax available in that statement, particularly when many estimates are needed. To obtain a single or very few estimates, you can use the HAZARDRATIO approach shown in the spline example in SAS Note 67024 to show the coefficients needed in the ESTIMATE statement using the traditional, positional syntax.
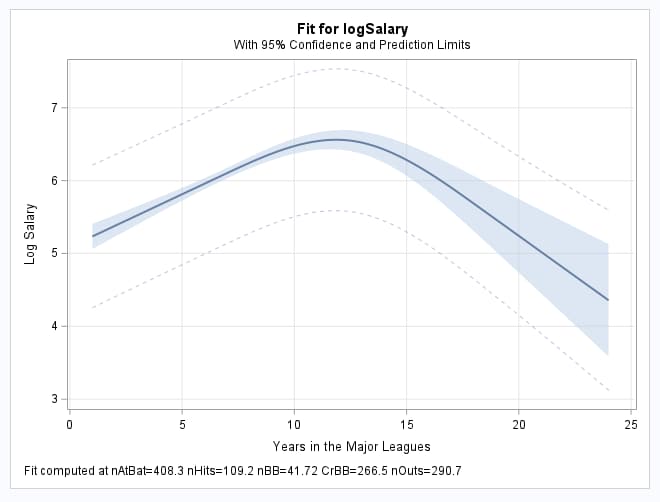
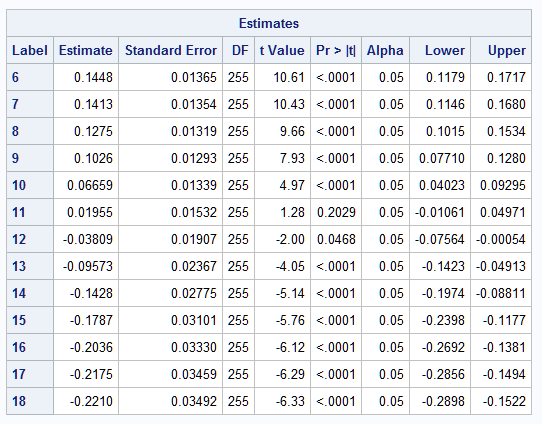
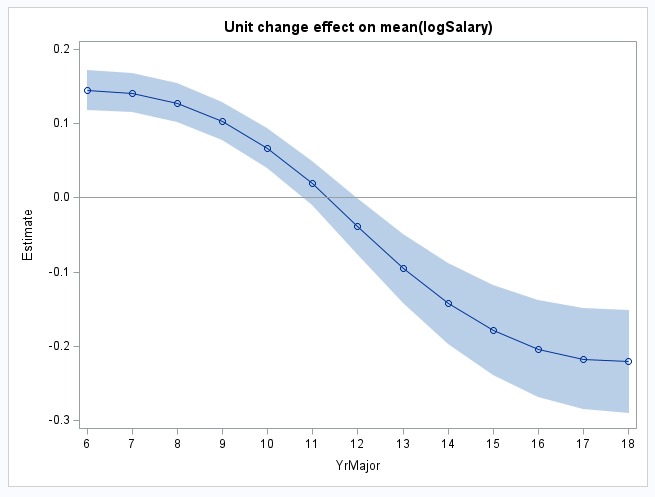
After fitting the model and saving it with the STORE statement in PROC GLMSELECT below, PROC PLM reads the saved model, and the EFFECTPLOT statement plots the curve showing the association of the YrMajor predictor on the logSalary mean while holding the covariates at their means. The ESTIMATE statement estimates the effects of changing YrMajor by one unit starting at values from YrMajor=6 to 18. The nonpositional syntax allows you to specify coefficients that apply to levels of YrMajor by referring to values of YrMajor directly without having to deal with the individual spline components. The statement then translates that specification into the coefficients that apply to the individual spline components. So, a specification such as splYr [-1,6] [1,7] computes the YrMajor=7 - YrMajor=6 difference in the same way as a specification such as GROUP -1 1 differences the parameters of a binary GROUP predictor in a model that has GROUP as a CLASS variable.
Finally, the results from the ESTIMATE statement are saved in data set DIFFS. The RENAME option changes the name of the variable that contains the labels in the ESTIMATE statements from LABEL to YrMajor. This data set is then used in PROC SGPLOT to plot the mean difference estimates along with their confidence limits. A reference line is drawn at a mean difference of zero:
proc glmselect data=sashelp.baseball;
effect splYr=spline(YrMajor / naturalcubic);
model logSalary = splYr nAtBat nHits nBB crBB nOuts / selection=none;
store bb;
run;
proc plm restore=bb;
effectplot fit(x=YrMajor);
estimate
'6' splYr [-1,6] [1,7] ,
'7' splYr [-1,7] [1,8] ,
'8' splYr [-1,8] [1,9] ,
'9' splYr [-1,9] [1,10] ,
'10' splYr [-1,10] [1,11],
'11' splYr [-1,11] [1,12],
'12' splYr [-1,12] [1,13],
'13' splYr [-1,13] [1,14],
'14' splYr [-1,14] [1,15],
'15' splYr [-1,15] [1,16],
'16' splYr [-1,16] [1,17],
'17' splYr [-1,17] [1,18],
'18' splYr [-1,18] [1,19] / cl;
ods output estimates=diffs(rename=(label=YrMajor));
run;
proc sgplot data=diffs noautolegend;
band upper=upper lower=lower x=YrMajor;
scatter y=estimate x=YrMajor;
series y=estimate x=YrMajor;
refline 0;
title "Unit change effect on mean(logSalary)";
run;
As with the logistic model above, if you imagine lines drawn tangent to the spline curve in the first plot at YrMajor values from 6 to 18, you can see that those lines have positive slope beginning at 6, then the slope decreases to zero at the peak of the curve near 11, and then becomes negative beyond 11. This trend can be seen in the table of response mean differences and is depicted in the plot from PROC SGPLOT:
 |
 |
 |
Estimating a Splined Predictor's Effect when the Spline Is Involved in Interaction
If the spline effect is involved in interactions with other predictors, then the effect of a unit change in the splined predictor is a function of more than just the spline parameters. As a result, the ESTIMATE statement specification is more complex. But the nonpositional syntax in the ESTIMATE statement makes it relatively easy to write. As noted in the previous example, you can use the HAZARDRATIO approach shown in the spline example in SAS Note 67024 to show the coefficients needed in the ESTIMATE statement using the traditional, positional syntax when only a few estimates are needed.
Consider the spline example discussed in SAS Note 67024 in which the splined BaseDeficit predictor interacts with age and the square of age. As shown there, the contrast of model parameters that estimates the change in response mean for a unit change in BaseDeficit involves only model effects that contain the spline. The parameters for the intercept, age, and the square of age drop out when estimating the difference in two BaseDeficit settings. Then, for each model term, the two sets of brackets that follow first contain a 1 for the higher BaseDeficit level in the difference or a -1 for the lower level. This is followed by a comma and then the level(s) needed for that term. For the spline term, only the BaseDeficit value is needed. For example, s [-1,-10] [1,-9] is the spline term contribution to the change from -10 to -9 in BaseDeficit. Similarly, s*age [-1, 10 -10] [1,10 -9] is the contribution for the s*age interaction term when age=10. Note that the value of the spline always follows ordinary variable values. Finally, s*age*age [-1, 10 10 -10] [1,10 10 -9] is the contribution for s*age*age. Note that age appears twice in the term, so its value, 10, must also appear twice in the brackets before the BaseDeficit value.
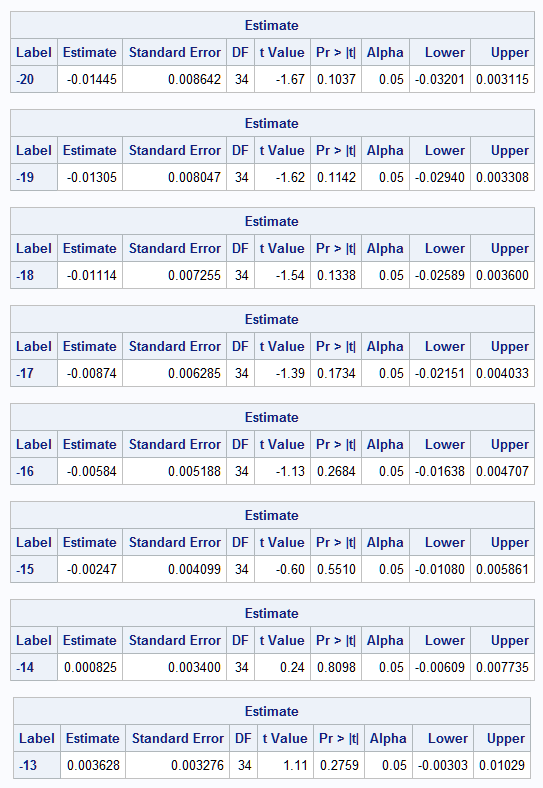
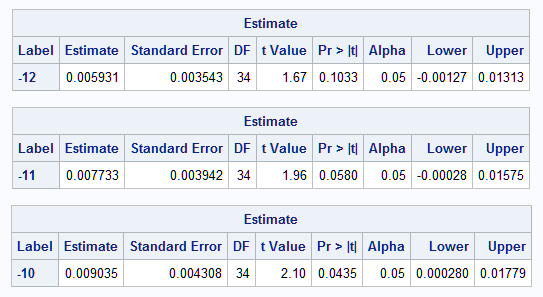
Rather than writing multiple specifications for the one unit differences at multiple levels of BaseDeficit, a simple macro can be written to generate them. The BD macro below generates a separate ESTIMATE statement as described above. The resulting ESTIMATE statements generate estimates of the mean response change for unit increases in BaseDeficit starting at BaseDeficit values from -20 to -10 and with age fixed at 10:
%macro bd();
%do i=-20 %to -10;
estimate "&i"
s [-1,&i] [1,%eval(&i+1)]
s*age [-1,10 &i] [1,10 %eval(&i+1)]
s*age*age [-1,10 10 &i] [1,10 10 %eval(&i+1)] / cl;
%end;
%mend;
proc orthoreg data=diabetes;
effect s = spline(BaseDeficit / naturalcubic);
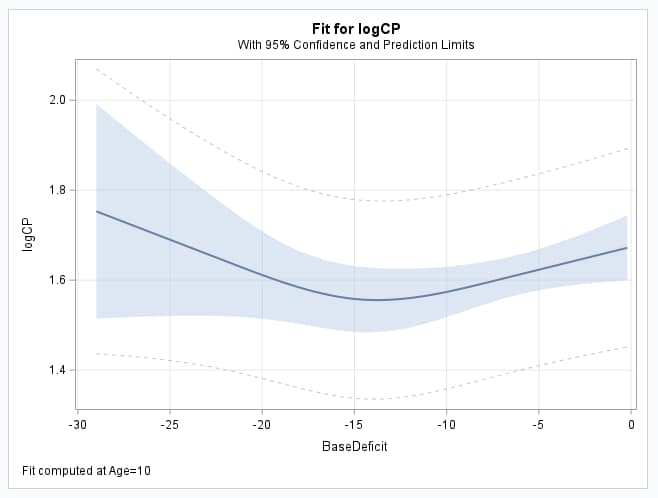
model logCP = s|age|age;
effectplot fit(x=BaseDeficit) / at (age=10);
%bd()
ods select fitplot estimates;
ods output estimates=diffs(rename=(label=BaseDeficit));
run;
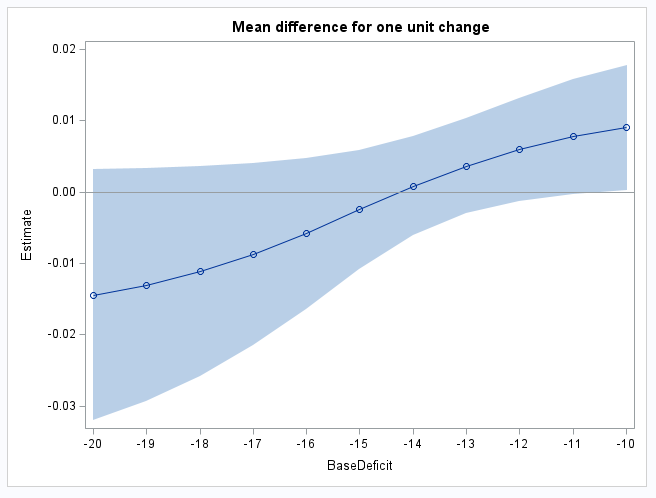
proc sgplot data=diffs noautolegend;
band upper=upper lower=lower x=BaseDeficit;
scatter y=estimate x=BaseDeficit;
series y=estimate x=BaseDeficit;
refline 0;
title "Mean difference for one unit change";
run;
The first plot shows how the BaseDeficit spline is associated with the response mean. Note the downward trend, leveling at about BaseDeficit=-14, and then increasing. This is reflected in the difference estimates that follow and in the plot of the differences:
 |
 |
 |
 |
Operating System and Release Information
| Product Family | Product | System | SAS Release | |
| Reported | Fixed* | |||
| SAS System | SAS/STAT | z/OS | ||
| z/OS 64-bit | ||||
| OpenVMS VAX | ||||
| Microsoft® Windows® for 64-Bit Itanium-based Systems | ||||
| Microsoft Windows Server 2003 Datacenter 64-bit Edition | ||||
| Microsoft Windows Server 2003 Enterprise 64-bit Edition | ||||
| Microsoft Windows XP 64-bit Edition | ||||
| Microsoft® Windows® for x64 | ||||
| OS/2 | ||||
| Microsoft Windows 8 Enterprise 32-bit | ||||
| Microsoft Windows 8 Enterprise x64 | ||||
| Microsoft Windows 8 Pro 32-bit | ||||
| Microsoft Windows 8 Pro x64 | ||||
| Microsoft Windows 8.1 Enterprise 32-bit | ||||
| Microsoft Windows 8.1 Enterprise x64 | ||||
| Microsoft Windows 8.1 Pro 32-bit | ||||
| Microsoft Windows 8.1 Pro x64 | ||||
| Microsoft Windows 10 | ||||
| Microsoft Windows 11 | ||||
| Microsoft Windows 95/98 | ||||
| Microsoft Windows 2000 Advanced Server | ||||
| Microsoft Windows 2000 Datacenter Server | ||||
| Microsoft Windows 2000 Server | ||||
| Microsoft Windows 2000 Professional | ||||
| Microsoft Windows NT Workstation | ||||
| Microsoft Windows Server 2003 Datacenter Edition | ||||
| Microsoft Windows Server 2003 Enterprise Edition | ||||
| Microsoft Windows Server 2003 Standard Edition | ||||
| Microsoft Windows Server 2003 for x64 | ||||
| Microsoft Windows Server 2008 | ||||
| Microsoft Windows Server 2008 R2 | ||||
| Microsoft Windows Server 2008 for x64 | ||||
| Microsoft Windows Server 2012 Datacenter | ||||
| Microsoft Windows Server 2012 R2 Datacenter | ||||
| Microsoft Windows Server 2012 R2 Std | ||||
| Microsoft Windows Server 2012 Std | ||||
| Microsoft Windows Server 2016 | ||||
| Microsoft Windows Server 2019 | ||||
| Microsoft Windows Server 2022 | ||||
| Microsoft Windows XP Professional | ||||
| Windows 7 Enterprise 32 bit | ||||
| Windows 7 Enterprise x64 | ||||
| Windows 7 Home Premium 32 bit | ||||
| Windows 7 Home Premium x64 | ||||
| Windows 7 Professional 32 bit | ||||
| Windows 7 Professional x64 | ||||
| Windows 7 Ultimate 32 bit | ||||
| Windows 7 Ultimate x64 | ||||
| Windows Millennium Edition (Me) | ||||
| Windows Vista | ||||
| Windows Vista for x64 | ||||
| 64-bit Enabled AIX | ||||
| 64-bit Enabled HP-UX | ||||
| 64-bit Enabled Solaris | ||||
| ABI+ for Intel Architecture | ||||
| AIX | ||||
| HP-UX | ||||
| HP-UX IPF | ||||
| IRIX | ||||
| Linux | ||||
| Linux for x64 | ||||
| Linux on Itanium | ||||
| OpenVMS Alpha | ||||
| OpenVMS on HP Integrity | ||||
| Solaris | ||||
| Solaris for x64 | ||||
| Tru64 UNIX | ||||
| Type: | Usage Note |
| Priority: | |
| Topic: | Analytics ==> Regression Analytics ==> Statistical Graphics SAS Reference ==> Macro SAS Reference ==> Procedures ==> GLMSELECT SAS Reference ==> Procedures ==> LOGISTIC SAS Reference ==> Procedures ==> ORTHOREG SAS Reference ==> Procedures ==> PLM |
| Date Modified: | 2025-10-21 15:52:08 |
| Date Created: | 2023-06-29 15:52:25 |