| What's New |
What's New in SAS/ETS 9.22
Overview
This chapter summarizes the new features available in SAS/ETS 9.22.
If you have used SAS/ETS procedures in the past, you can review this chapter to learn about the new features that have been added. When you see a new feature that might be useful for your work, turn to the appropriate chapter to read about the feature in detail.
Highlights of Enhancements
The following new procedures have been added to SAS/ETS software:
The SEVERITY procedure (Experimental)
The TIMEID procedure (Experimental)
The SIMILARITY procedure, which performs similarity analysis for sets of time series, was experimental in the previous release and is now production status.
A new Java application, called the SAS/ETS Model Editor (Experimental), provides a graphical user interface for editing nonlinear statistical models and provides a convenient way to use the MODEL procedure.
New features have been added to the following SAS/ETS components:
New features for defining custom time intervals have been added to Base SAS software that might be of interest to SAS/ETS users. For more information, see SAS Language Reference: Dictionary.
Highlights of Enhancements in SAS/ETS 9.2
Users who are updating directly to SAS/ETS 9.22 from a release prior to SAS/ETS 9.2 can find information about the SAS/ETS 9.2 changes and enhancements in What's New in SAS/ETS for SAS 9.2.
AUTOREG Procedure
The following new features have been added to the AUTOREG procedure:
Three asymmetric GARCH models, namely quadratic GARCH, threshold GARCH, and power GARCH, are implemented to measure the impact of news on the future volatility. Power GARCH also considers the long memory property in the volatility.
Besides the existing two tests for the existence of ARCH effect, Lee and King’s ARCH test and Wong and Li’s ARCH test are implemented. Lee and King’s ARCH test is a one-sided locally most mean powerful (LMMP) test; Wong and Li’s ARCH test is robust to outliers. If the NLAG= option is specified, the statistics based on the final model residuals, along with the OLS residuals, can also be computed.
The Hannan-Quinn criterion (HQC) is implemented and included in the summary statistics.
Four statistical tests of independence are implemented: BDS test, runs test, turning point test, and rank version of the von Neumann ratio test. They are powerful tools for model selection and specification test.
The augmented Dickey-Fuller (ADF) test for unit root is implemented. This test accounts for some form of dependence between the innovations of the time series. The ADF formulation includes lags of the order
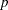 in the regression. When the lag is specified to be zero, it reduces to the standard Dickey-Fuller Unit root test. In the presence of regressors, the Engle-Granger cointegration test is performed using the augmented Dickey-Fuller test statistic.
in the regression. When the lag is specified to be zero, it reduces to the standard Dickey-Fuller Unit root test. In the presence of regressors, the Engle-Granger cointegration test is performed using the augmented Dickey-Fuller test statistic. The Elliott-Rothenberg-Stock (ERS) unit root and Ng-Perron (NP) unit root test are implemented. These tests also perform automatic lag length selection by using the information criterion. The Bayesian information criterion (BIC) is used in the ERS test, and the modified Akaike information criterion (AICc) is used in Ng-Perron test.
The CLASS statement is now supported. A CLASS statement enables you to declare classification variables for use as explanatory effects in a model. When a CLASS variable is used as a predictor in the MODEL statement, the procedure automatically creates a dummy regressor that corresponds to each discrete value or level of the CLASS variable.
The MODEL statement now supports the use of CLASS variables and interaction terms as predictors.
The AR, GARCH, and HETERO parameters can be specified in the TEST and RESTRICT statements.
The likelihood ratio (LR) test and the Lagrange multiplier (LM) test are supported in TEST statement when GARCH= option is specified.
COUNTREG Procedure
The following new features have been added to the COUNTREG procedure:
The CLASS statement is now supported. A CLASS statement enables you to declare classification variables for use as explanatory effects in a model. When a CLASS variable is used as a predictor in the MODEL statement, the procedure automatically creates a dummy regressor that corresponds to each discrete value or level of the CLASS variable.
The MODEL statement now supports the use of CLASS variables and interaction terms as predictors.
The FREQ statement is now supported. A FREQ statement specifies a variable whose values indicate the number of cases that are represented by each observation. That is, the procedure treats each observation as if it had appeared
 times in the input data set, where is the value of the FREQ variable.
times in the input data set, where is the value of the FREQ variable. The WEIGHT statement is now supported. A WEIGHT statement specifies a variable whose values supply weights for each observation in the dataset. These weights control the importance (weight) given to the data observations in fitting the model.
The NLOPTIONS statement enables you to specify options for the subsystem that is used for the nonlinear optimization.
MDC Procedure
The following new features have been added to the MDC procedure:
The CLASS statement is now supported. A CLASS statement enables you to declare classification variables for use as explanatory effects in a model. When a CLASS variable is used as a predictor in the MODEL statement, the procedure automatically creates a dummy regressor that corresponds to each discrete value or level of the CLASS variable.
The MODEL statement now supports the use of CLASS variables and interaction terms as predictors.
The TEST statement is now supported to test linear equality restrictions on the parameters. Three tests are available: Wald, Lagrange multiplier, and likelihood ratio.
MODEL Procedure
The following feature has been added to the MODEL procedure:
For the GMM estimation method, Hansen’s J statistic for the test of overidentifying restrictions is reported along with its probabilty.
QLIM Procedure
The following new features have been added to the QLIM procedure:
The TE1 and TE2 options output technical efficiency measures for each producer in stochastic frontier models as suggested by Battese and Coelli (1988) and Jondrow at al. (1982).
The WEIGHT statement is now supported. A WEIGHT statement identifies a variable to supply weights for each observation in the dataset. By default, the weights are normalized so that they add up to the sample size. If the NONORMALIZE option is used, the actual weights are used without normalization.
SASEFAME Engine
The SASEFAME interface engine provides a seamless interface between Fame and SAS data to enable SAS users to access and process time series, case series, and formulas that reside in a Fame database. The following enhancements have been made to the SASEFAME access engine for Fame databases:
The INSET= option enables you to pass Fame commands through an input SAS data set and select your Fame input variables by using the KEEPLIST= clause or the WHERE= clause as selection input for BY variables.
The DBVERSION= option displays the version number of the Fame Work data base in the SAS log. SASEFAME uses Fame 10, which does not allow version 2 databases. Use the Fame compress utility with the -m option to convert your version 2 databases to version 3 or 4. The default is version 4.
The TUNEFAME= option tunes the Fame database engine’s use of memory to reduce I/O times in favor of a bigger virtual memory for caching database objects. The default is 100 MB.
The TUNECHLI= option tunes the C host language interface (CHLI) database engine’s use of memory to reduce I/O times in favor of a bigger virtual memory for caching database objects. The default is 100 MB.
The WILDCARD= option enables you to select series by using the new Fame 10 wildcarding capabilities which allow a longer 242-character wildcard to match data object series names within the Fame database.
The interface uses the most current version of Fame 10 CHLI. The SAS log reports the version number of the Fame 10 CHLI:
NOTE: The SASEFAME engine is using Version 10.03 of the HLI.
SASEHAVR Engine
The SASEHAVR interface engine is a seamless interface between Haver and SAS data processing that enables SAS users to read economic and financial time series data that reside in a Haver Analytics DLX (Data Link Express) database. The following enhancements have been made to the SASEHAVR access engine for Haver Analytics databases:
The AGGMODE= option enables you to specify a STRICT or RELAXED aggregation method. AGGMODE=RELAXED is the default setting. Aggregation is supported only from a more frequent time interval to a less frequent time interval, such as from weekly to monthly. The SAS log reports the status of AGGMODE.
The SHORT= option enables you to specify the list of Haver short sources to be included in the output SAS data set. This list is comma-delimited and must be surrounded by quotation marks "".
The DROPSHORT= option enables you to specify the list of Haver short sources to be excluded from the output SAS data set. This list is comma-delimited and must be surrounded by quotation marks "".
The LONG= option enables you to specify the list of Haver long sources to be included in the output SAS data set. This list is comma-delimited and must be surrounded by quotation marks "".
The DROPLONG= option enables you to specify the list of Haver long sources to be excluded from the output SAS data set. This list is comma-delimited and must be surrounded by quotation marks "".
The GEOG1= option enables you to specify the list of Haver geography1 codes to be included in the output SAS data set. This list is comma-delimited and must be surrounded by quotation marks "".
The DROPGEOG1= option enables you to specify the list of Haver geography1 codes to be excluded from the output SAS data set. This list is comma-delimited and must be surrounded by quotation marks "".
The GEOG2= option enables you to specify the list of Haver geography2 codes to be included in the output SAS data set. This list is comma-delimited and must be surrounded by quotation marks "".
The DROPGEOG2= option enables you to specify the list of Haver geography2 codes to be excluded from the output SAS data set. This list is comma-delimited and must be surrounded by quotation marks "".
The OUTSELECT=ON option specifies that the output data set show values of selection keys such as geography codes, groups, sources, and short and long sources for each selected variable name (time series) in the database. The SAS log reports the status of OUTSELECT.
The OUTSELECT=OFF option specifies that the output data set show the observations in range for all selected time series. This is the default for this option.
The interface is now using the most current version of DLXAPI32. The SAS log reports the version number of the Haver DLX api.
New SEVERITY Procedure
(Experimental)The new SEVERITY procedure fits models for statistical distributions of the severity (magnitude) of events. A couple of examples of the events typically modeled using the procedure are insurance loss payments and intermittent sales of products.
The SEVERITY procedure is experimental for this release. It provides the following features:
The magnitude of events can be modeled as a random variable with a continuous parametric probability distribution. The SEVERITY procedure uses the maximum likelihood method to fit multiple specified distributions and identifies the best model based on a specified model selection criterion.
The SEVERITY procedure is delivered with a set of predefined models for several commonly used distributions. These include the Burr, exponential, gamma, inverse Gaussian, lognormal, Pareto, generalized Pareto, and Weibull distributions.
The SEVERITY procedure is can be extended to fit any continuous parametric distribution. You can specify the distribution’s model by using a set of functions and subroutines that are defined by using the FCMP procedure. The model must include functions to provide the values of the probability density function (PDF) and the cumulative distribution function (CDF) of the distribution. The model can also optionally include functions or subroutines that provide the distribution’s description, the number of parameters, initial values and bounds for the parameters, the scale parameter transform, and the gradient vector and the Hessian matrix of the PDF and the CDF with respect to the parameters.
Exogenous variables can be specified for fitting a model that has a scale parameter. The exogenous variables are modeled such that their linear combination affects the scale parameter via a specified link function. The regression coefficients that are associated with the variables in the linear combination are estimated along with the parameters of the distribution. Currently, only the exponential link function is supported.
Censoring and truncation can be specified for each observed value of the response variable. Global values can also be specified to override the individual values that are associated with each observed value. Currently, only censoring from above (that is, right-censoring) and truncation from below (that is, left-truncation) are allowed.
SIMILARITY Procedure
The SIMILARITY procedure was classified as experimental in SAS/ETS 9.2. PROC SIMILARITY is now production status.
New TIMEID Procedure
(Experimental)The new TIMEID procedure analyzes the sequence of ID values in a SAS data set to identify the time interval between observations and verifies that the observations in the data set represent a properly spaced time series.
The TIMEID procedure provides the following features:
Specified time intervals and alignments can be used to evaluate a data set’s time ID values in terms of the distributions of duplicated values, alignment offsets, and the gaps between adjacent observations.
The time interval’s width, shift, and alignment can be inferred from a time ID variable. When either the interval or its alignment is specified, this information is used to guide the process of inferring the remaining quantity.
When multiple BY groups are present, detailed diagnostics for each BY group are reported in addition to summarized diagnostic information which applies to all BY groups in the data set.
TIMESERIES Procedure
Three features have been added to the TIMESERIES procedure for performing spectral analyses of the input time series and native database accumulation of data for a time series.
Singular Spectrum Analysis
Singular spectrum analysis (SSA) is a technique for decomposing a time series into additive components and categorizing these components based on the magnitudes of their contributions. SSA uses a single parameter, the window length, to quantify patterns in a time series without relying on preconceived notions about the structure of the time series. The window length represents the maximum lag considered in the analysis and corresponds to the dimensionality of the PCA (principle components analysis) on which the SSA is based.
In addition to SSA output options, an SSA statement has been added to explicitly control the window length parameter and the grouping of SSA series components.
Fourier Spectrum Analysis
Functionality similar to that available in PROC SPECTRA for analyzing periodograms of time series data has been incorporated into PROC TIMESERIES. Now ODS graphical representations of periodograms and spectral density estimates can be computed and displayed.
Database Accumulation
For Teradata-based input data sets, aggregation and accumulation can be performed using native facilities in the database server. Most ACCUMULATE= options specified in the ID and VAR statements can be performed by the database server.
UCM Procedure
The ARMA model specification options in the IRREGULAR statement, which were experimental in SAS 9.2, are now production.
X12 Procedure
Many new features have been added to the X12 procedure.
The CHECK statement produces statistics for diagnostic checking of residuals from the estimated regARIMA model. The following new tables are associated with the CHECK statement: "Autocorrelation of regARIMA Model Residuals," "Partial Autocorrelation of regARIMA Model Residuals," "Autocorrelation of Squared regARIMA Model Residuals," "Summary Statistics for the Unstandardized Residuals," "Normality Statistics for regARIMA Model Residuals," and "Table G Rs: 10*LOG(SPECTRUM) of the regARIMA Model Residuals." If ODS GRAPHICS ON is specified, the following new plots are associated with diagnostic checking output: the autocorrelation function (ErrorACF) plot of the residuals, the partial autocorrelation function (ErrorPACF) plot of the residuals, the autocorrelation function (SqErrorACF) plot of the squared residuals, a histogram (ResidualHistogram) of the residuals, and a spectral plot (SpectralPlot) of the residuals.
The MAXLAG option of the IDENTIFY statement specifies the maximum number of lags for the sample ACF and PACF that are associated with model identification.
The following tables are now available through the OUTPUT statement: E1, E2, E3, and E8.
The SIGMALIM option of the X11 statement enables you to specify the upper and lower sigma limits that are used to identify and decrease the weight of extreme irregular values in the internal seasonal adjustment computations.
The TYPE option of the X11 statement controls which factors are removed from the original series to produce the seasonally adjusted series (table D11) and also the final trend cycle (table D12).
The OUTSTAT= option of the X12 statement specifies the optional output data set that contains the summary statistics related to each seasonally adjusted series. The data set is sorted by the BY-group variables, if any, and by series names.
The PERIODOGRAM option of the X12 statement enables you to specify that the PERIODOGRAM rather than the SPECTRUM of the series be plotted in the G tables and plots.
The PLOTS= option of the X12 statement controls the plots that are produced through ODS Graphics.
The SPECTRUMSERIES option of the X12 statement specifies the table name of the series that is used in the spectrum of the original series (table G0). The table names that can be specified are A1, A19, B1, or E1. The default is B1.
The following tables are now available through the TABLES statement: E1, E2, and E3.
The following tables are now available through ODS: "Model Description for ARIMA Model Identification", "Model Description for ARIMA Model Estimation", "Final Seasonal Filter Selection via Global MSR", "Seasonal Filters by Period", and "Final Trend Cycle Statistics". The model description information was previously displayed in notes; an ODS table enables you to export the information to a data set. The seasonal filter and trend filter tables are new.
Auxiliary variables have been added to ACF and PACF data sets that are available through ODS OUTPUT. The following variables have been added: _NAME_, Transform, Adjust, Regressors, Diff, and Sdiff. The purpose of the new variables is to help you identify the source of the data when multiple ACFs and PACFs are calculated.
The following new feature is experimental:
The AUXDATA= option of the X12 specifies an auxiliary input data set that can contain user-defined variables specified in the INPUT statement, the USERVAR= option of the REGRESSION statment, or the USERDEFINED statement. The AUXDATA= option is useful when user-defined regressors are used for multiple time series data sets or multiple BY groups.
SAS/ETS Model Editor Application
(Experimental)A new interactive application, the SAS/ETS Model Editor, enables you to define, fit, and simulate nonlinear statistical models using the MODEL procedure. The SAS/ETS Model Editor enables you to use the powerful features of PROC MODEL through a convenient and interactive graphical user interface.
Date Intervals, Formats, and Functions
The custom time intervals that are available in Base SAS software can be used in SAS/ETS procedures. Custom time intervals enable you to specify beginning and ending dates and seasonality for time intervals according to any definition. Such intervals can be used to define the following:
fiscal intervals such as monthly intervals that begin on a day other than the first day of the month (for example, intervals that begin on the
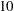 th day of each month)
th day of each month) fiscal intervals such as monthly intervals that begin on different days for different months (for example, March of 2000 can begin on March
, but April of 2000 can begin on April 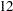 )
) business days, such as banking days that exclude holidays
hourly intervals that omit hours that the business is closed
Copyright © 2010 by SAS Institute Inc.,Cary, NC, USA. All rights reserved.