The GLM Procedure
-
Overview

-
Getting Started
-
Syntax
-
DetailsStatistical Assumptions for Using PROC GLMSpecification of EffectsUsing PROC GLM InteractivelyParameterization of PROC GLM ModelsHypothesis Testing in PROC GLMEffect Size Measures for F Tests in GLMAbsorptionSpecification of ESTIMATE ExpressionsComparing GroupsMultivariate Analysis of VarianceRepeated Measures Analysis of VarianceRandom-Effects AnalysisMissing ValuesComputational ResourcesComputational MethodOutput Data SetsDisplayed OutputODS Table NamesODS Graphics
-
ExamplesRandomized Complete Blocks with Means Comparisons and ContrastsRegression with Mileage DataUnbalanced ANOVA for Two-Way Design with InteractionAnalysis of CovarianceThree-Way Analysis of Variance with ContrastsMultivariate Analysis of VarianceRepeated Measures Analysis of VarianceMixed Model Analysis of Variance with the RANDOM StatementAnalyzing a Doubly Multivariate Repeated Measures DesignTesting for Equal Group VariancesAnalysis of a Screening Design
- References
Statistical Assumptions for Using PROC GLM
The basic statistical assumption underlying the least squares approach to general linear modeling is that the observed values
of each dependent variable can be written as the sum of two parts: a fixed component 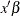 , which is a linear function of the independent coefficients, and a random noise, or error, component
, which is a linear function of the independent coefficients, and a random noise, or error, component  :
:
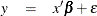
The independent coefficients x are constructed from the model effects as described in the section Parameterization of PROC GLM Models. Further, the errors for different observations are assumed to be uncorrelated with identical variances. Thus, this model can be written
![\[ \begin{array}{lcrclcr} E(Y) & = & \mb{X}\beta , & & \mbox{Var}(Y) & = & \sigma ^2 I \end{array} \]](images/statug_glm0086.png)
where Y is the vector of dependent variable values, 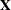 is the matrix of independent coefficients, I is the identity matrix, and
is the matrix of independent coefficients, I is the identity matrix, and 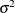 is the common variance for the errors. For multiple dependent variables, the model is similar except that the errors for
different dependent variables within the same observation are not assumed to be uncorrelated. This yields a multivariate linear
model of the form
is the common variance for the errors. For multiple dependent variables, the model is similar except that the errors for
different dependent variables within the same observation are not assumed to be uncorrelated. This yields a multivariate linear
model of the form
![\[ \begin{array}{lcrclcr} E(Y) & = & \mb{X}B, & & \mbox{Var}(\mbox{vec}(Y)) & = & \Sigma \otimes I \end{array} \]](images/statug_glm0089.png)
where Y and B are now matrices, with one column for each dependent variable, 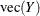 strings Y out by rows, and
strings Y out by rows, and 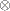 indicates the Kronecker matrix product.
indicates the Kronecker matrix product.
Under the assumptions thus far discussed, the least squares approach provides estimates of the linear parameters that are unbiased and have minimum variance among linear estimators. Under the further assumption that the errors have a normal (or Gaussian) distribution, the least squares estimates are the maximum likelihood estimates and their distribution is known. All of the significance levels ("p values") and confidence limits calculated by the GLM procedure require this assumption of normality in order to be exactly valid, although they are good approximations in many other cases.