The NLMIXED Procedure
-
Overview

-
Getting Started
-
Syntax
-
DetailsModeling Assumptions and NotationIntegral ApproximationsBuilt-in Log-Likelihood FunctionsHierarchical Model SpecificationOptimization AlgorithmsFinite-Difference Approximations of DerivativesHessian ScalingActive Set MethodsLine-Search MethodsRestricting the Step LengthComputational ProblemsCovariance MatrixPredictionComputational ResourcesDisplayed OutputODS Table Names
-
Examples
- References
The PROC NLMIXED statement invokes the NLMIXED procedure. Table 70.1 summarizes the options available in the PROC NLMIXED statement.
Table 70.1: PROC NLMIXED Statement Options
|
Option |
Description |
|---|---|
|
Basic Options |
|
|
Specifies the input data set |
|
|
Specifies the integration method |
|
|
Requests that the unique SUBJECT= variable values not be used |
|
|
Displayed Output Specifications |
|
|
Specifies |
|
|
Requests the correlation matrix |
|
|
Requests the covariance matrix |
|
|
Specifies the degrees of freedom for p-values and confidence limits |
|
|
Requests the correlation matrix of additional estimates |
|
|
Requests the covariance matrix of additional estimates |
|
|
Requests derivatives of additional estimates |
|
|
Requests the empirical ("sandwich") estimator of covariance matrix |
|
|
Requests the Hessian matrix |
|
|
Requests iteration details |
|
|
Specifies the gradient at starting values |
|
|
Debugging Output |
|
|
Displays the model execution messages |
|
|
Displays compiled model program |
|
|
Produces a model dependency listing |
|
|
Displays the model derivatives |
|
|
Displays the model program and variables |
|
|
Displays detailed model execution messages |
|
|
Displays the model cross references |
|
|
Quadrature Options |
|
|
Requests no adaptive scaling |
|
|
Requests no adaptive centering |
|
|
Displays output data set |
|
|
Specifies the search factor |
|
|
Specifies the maximum points |
|
|
Specifies the number of points |
|
|
Specifies the scale factor |
|
|
Specifies the tolerance |
|
|
Empirical Bayes Options |
|
|
Requests comprehensive optimization |
|
|
Specifies the step-shortening fraction |
|
|
Specifies the step-shortening tolerance |
|
|
Specifies the number of Newton steps |
|
|
Specifies the number of substeps |
|
|
Specifies the convergence tolerance |
|
|
Requests zero as the starting values |
|
|
Displays an output data set that contains empirical Bayes estimates of random effects and their approximate standard errors |
|
|
Optimization Specifications |
|
|
Specifies the type of Hessian scaling |
|
|
Specifies the start for approximated Hessian |
|
|
Specifies the line-search method |
|
|
Specifies the line-search precision |
|
|
Checks optimality in a neighborhood |
|
|
Specifies the iteration number for update restart |
|
|
Specifies the minimization technique |
|
|
Specifies the update technique |
|
|
Derivatives Specifications |
|
|
Uses only the diagonal of Hessian |
|
|
Specifies the finite-difference second derivatives |
|
|
Specifies the finite-difference derivatives |
|
|
Constraint Specifications |
|
|
Specifies the Lagrange multiplier tolerance for deactivating |
|
|
Specifies the range for active constraints |
|
|
Specifies the tolerance for dependent constraints |
|
|
Termination Criteria Specifications |
|
|
Specifies the absolute function convergence criterion |
|
|
Specifies the absolute function difference convergence criterion |
|
|
Specifies the absolute gradient convergence criterion |
|
|
Specifies the absolute parameter convergence criterion |
|
|
Specifies the relative function convergence criterion |
|
|
Specifies another relative function convergence criterion |
|
|
Specifies the number accurate digits in objective function |
|
|
Specifies the FSIZE parameter of the relative function and relative gradient termination criteria |
|
|
Specifies the relative gradient convergence criterion |
|
|
Specifies the maximum number of function calls |
|
|
Specifies the maximum number of iterations |
|
|
Specifies the upper limit seconds of CPU time |
|
|
Specifies the minimum number of iterations |
|
|
Specifies the relative parameter convergence criterion |
|
|
Used in XCONV criterion |
|
|
Step Length Specifications |
|
|
Specifies the damped steps in line search |
|
|
Specifies the initial trust-region radius |
|
|
Specifies the maximum trust-region radius |
|
|
Singularity Tolerances |
|
|
Specifies the tolerance for Cholesky roots |
|
|
Specifies the tolerance for Hessian |
|
|
Specifies the tolerance for sweep |
|
|
Specifies the tolerance for variances |
|
|
Covariance Matrix Tolerances |
|
|
Specifies the absolute singularity for inertia |
|
|
Specifies the multiplication factor for COV matrix |
|
|
Specifies the tolerance for singular COV matrix |
|
|
Specifies the threshold for Moore-Penrose inverse |
|
|
Specifies the relative M singularity for inertia |
|
|
Specifies the relative V singularity for inertia |
|
These options are described in alphabetical order. For a description of the mathematical notation used in the following sections, see the section Modeling Assumptions and Notation.
-
ABSCONV=r
ABSTOL=r -
specifies an absolute function convergence criterion. For minimization, termination requires
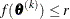 . The default value of r is the negative square root of the largest double-precision value, which serves only as a protection against overflows.
. The default value of r is the negative square root of the largest double-precision value, which serves only as a protection against overflows.
-
ABSFCONV=r<[n]>
ABSFTOL=r<[n]> -
specifies an absolute function difference convergence criterion. For all techniques except NMSIMP, termination requires a small change of the function value in successive iterations:
![\[ |f(\btheta ^{(k-1)}) - f(\btheta ^{(k)})| \leq r \]](images/statug_nlmixed0026.png)
The same formula is used for the NMSIMP technique, but
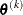 is defined as the vertex with the lowest function value, and
is defined as the vertex with the lowest function value, and 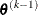 is defined as the vertex with the highest function value in the simplex. The default value is r = 0. The optional integer value n specifies the number of successive iterations for which the criterion must be satisfied before the process can be terminated.
is defined as the vertex with the highest function value in the simplex. The default value is r = 0. The optional integer value n specifies the number of successive iterations for which the criterion must be satisfied before the process can be terminated.
-
ABSGCONV=r<[n]>
ABSGTOL=r<[n]> -
specifies an absolute gradient convergence criterion. Termination requires the maximum absolute gradient element to be small:
![\[ \max _ j |g_ j(\btheta ^{(k)})| \leq r \]](images/statug_nlmixed0029.png)
This criterion is not used by the NMSIMP technique. The default value is r = 1E–5. The optional integer value n specifies the number of successive iterations for which the criterion must be satisfied before the process can be terminated. If you specify more than one RANDOM statement, the default value is r = 1E–3.
-
ABSXCONV=r<[n]>
ABSXTOL=r<[n]> -
specifies an absolute parameter convergence criterion. For all techniques except NMSIMP, termination requires a small Euclidean distance between successive parameter vectors,
![\[ \parallel \btheta ^{(k)} - \btheta ^{(k-1)} \parallel _2 \leq r \]](images/statug_nlmixed0030.png)
For the NMSIMP technique, termination requires either a small length
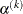 of the vertices of a restart simplex,
of the vertices of a restart simplex,
![\[ \alpha ^{(k)} \leq r \]](images/statug_nlmixed0032.png)
or a small simplex size,
![\[ \delta ^{(k)} \leq r \]](images/statug_nlmixed0033.png)
where the simplex size
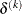 is defined as the L1 distance from the simplex vertex
is defined as the L1 distance from the simplex vertex 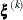 with the smallest function value to the other n simplex points
with the smallest function value to the other n simplex points 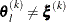 :
:
![\[ \delta ^{(k)} = \sum _{\btheta _ l \neq y} \parallel \btheta _ l^{(k)} - \bxi ^{(k)}\parallel _1 \]](images/statug_nlmixed0037.png)
The default is r = 1E–8 for the NMSIMP technique and r = 0 otherwise. The optional integer value n specifies the number of successive iterations for which the criterion must be satisfied before the process can terminate.
-
ALPHA=

-
specifies the alpha level to be used in computing confidence limits. The default value is 0.05.
-
ASINGULAR=r
ASING=r -
specifies an absolute singularity criterion for the computation of the inertia (number of positive, negative, and zero eigenvalues) of the Hessian and its projected forms. The default value is the square root of the smallest positive double-precision value.
- CFACTOR=f
-
specifies a multiplication factor f for the estimated covariance matrix of the parameter estimates.
- COV
-
requests the approximate covariance matrix for the parameter estimates.
- CORR
-
requests the approximate correlation matrix for the parameter estimates.
-
COVSING=r
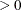
-
specifies a nonnegative threshold that determines whether the eigenvalues of a singular Hessian matrix are considered to be zero.
-
DAMPSTEP<=r>
DS<=r> -
specifies that the initial step-size value
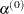 for each line search (used by the QUANEW, CONGRA, or NEWRAP technique) cannot be larger than r times the step-size value used in the former iteration. If you specify the DAMPSTEP option without factor r, the default value is r = 2. The DAMPSTEP=r option can prevent the line-search algorithm from repeatedly stepping into regions where some objective functions are difficult
to compute or where they could lead to floating-point overflows during the computation of objective functions and their derivatives.
The DAMPSTEP=r option can save time-costly function calls that result in very small step sizes . For more details on setting the start values of each line search, see the section Restricting the Step Length.
for each line search (used by the QUANEW, CONGRA, or NEWRAP technique) cannot be larger than r times the step-size value used in the former iteration. If you specify the DAMPSTEP option without factor r, the default value is r = 2. The DAMPSTEP=r option can prevent the line-search algorithm from repeatedly stepping into regions where some objective functions are difficult
to compute or where they could lead to floating-point overflows during the computation of objective functions and their derivatives.
The DAMPSTEP=r option can save time-costly function calls that result in very small step sizes . For more details on setting the start values of each line search, see the section Restricting the Step Length.
- DATA=SAS-data-set
-
specifies the input data set. Observations in this data set are used to compute the log likelihood function that you specify with PROC NLMIXED statements.
NOTE: In SAS/STAT 12.3 and previous releases, if you are using a RANDOM statement, the input data set must be clustered according to the SUBJECT= variable. One easy way to accomplish this is to sort your data by the SUBJECT= variable before calling the NLMIXED procedure. PROC NLMIXED does not sort the input data set for you.
- DF=d
-
specifies the degrees of freedom to be used in computing p values and confidence limits. PROC NLMIXED calculates the default degrees of freedom as follows:
-
When there is no RANDOM statement in the model, the default value is the number of observations.
-
When only one RANDOM statement is specified, the default value is the number of subjects minus the number of random effects for random-effects models.
-
When multiple RANDOM statements are specified, the default degrees of freedom is the number of subjects in the lowest nested level minus the total number of random effects. For example, if the highest level of hierarchy is specified by SUBJECT=S1 and the next level of hierarchy (nested within S1) is specified by SUBJECT=S2(S1), then the degrees of freedom is computed as the total number of subjects from S2(S1) minus the total number of random-effects variables in the model.
If the degrees of freedom computation leads to a nonpositive value, then the default value is the total number of observations.
-
- DIAHES
- EBOPT
-
requests that a more comprehensive optimization be carried out if the default empirical Bayes optimization fails to converge. If you specify more than one RANDOM statement, this option is ignored.
-
EBSSFRAC=r
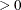
-
specifies the step-shortening fraction to be used while computing empirical Bayes estimates of the random effects. The default value is 0.8. If you specify more than one RANDOM statement, this option is ignored.
-
EBSSTOL=r
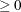
-
specifies the objective function tolerance for determining the cessation of step-shortening while computing empirical Bayes estimates of the random effects. The default value is r = 1E–8. If you specify more than one RANDOM statement, this option is ignored.
-
EBSTEPS=n
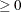
-
specifies the maximum number of Newton steps for computing empirical Bayes estimates of random effects. The default value is n = 50. If you specify more than one RANDOM statement, this option is ignored.
-
EBSUBSTEPS=n
-
specifies the maximum number of step-shortenings for computing empirical Bayes estimates of random effects. The default value is n = 20. If you specify more than one RANDOM statement, this option is ignored.
-
EBTOL=r
-
specifies the convergence tolerance for empirical Bayes estimation. The default value is
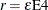 , where
, where  is the machine precision. This default value equals approximately 1E–12 on most machines. If you specify more than one RANDOM
statement, this option is ignored.
is the machine precision. This default value equals approximately 1E–12 on most machines. If you specify more than one RANDOM
statement, this option is ignored.
- EBZSTART
-
requests that a zero be used as starting values during empirical Bayes estimation. By default, the starting values are set equal to the estimates from the previous iteration (or zero for the first iteration).
- ECOV
-
requests the approximate covariance matrix for all expressions specified in ESTIMATE statements.
- ECORR
-
requests the approximate correlation matrix for all expressions specified in ESTIMATE statements.
- EDER
-
requests the derivatives of all expressions specified in ESTIMATE statements with respect to each of the model parameters.
- EMPIRICAL
-
requests that the covariance matrix of the parameter estimates be computed as a likelihood-based empirical ("sandwich") estimator (White, 1982). If
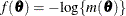 is the objective function for the optimization and
is the objective function for the optimization and 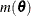 denotes the marginal log likelihood (see the section Modeling Assumptions and Notation for notation and further definitions) the empirical estimator is computed as
denotes the marginal log likelihood (see the section Modeling Assumptions and Notation for notation and further definitions) the empirical estimator is computed as
![\[ \mb{H}(\hat{\btheta })^{-1} \left( \sum _{i=1}^{s} \mb{g}_ i(\hat{\btheta }) \mb{g}_ i(\hat{\btheta })’ \right) \mb{H}(\hat{\btheta })^{-1} \]](images/statug_nlmixed0047.png)
where
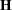 is the second derivative matrix of f and
is the second derivative matrix of f and 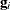 is the first derivative of the contribution to f by the ith subject. If you choose the EMPIRICAL option, this estimator of the covariance matrix of the parameter estimates replaces
the model-based estimator
is the first derivative of the contribution to f by the ith subject. If you choose the EMPIRICAL option, this estimator of the covariance matrix of the parameter estimates replaces
the model-based estimator 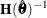 in subsequent calculations. You can output the subject-specific gradients to a SAS data set with the SUBGRADIENT
option in the PROC NLMIXED
statement.
in subsequent calculations. You can output the subject-specific gradients to a SAS data set with the SUBGRADIENT
option in the PROC NLMIXED
statement.
The EMPIRICAL option requires the presence of a RANDOM statement and is available for METHOD= GAUSS and METHOD= ISAMP only.
If you specify more than one RANDOM statement, this option is ignored.
-
FCONV=r<[n]>
FTOL=r<[n]> -
specifies a relative function convergence criterion. For all techniques except NMSIMP, termination requires a small relative change of the function value in successive iterations,
![\[ { \frac{|f(\btheta ^{(k)}) - f(\btheta ^{(k-1)})|}{\max (|f(\btheta ^{(k-1)})|,\mbox{FSIZE}) } } \leq r \]](images/statug_nlmixed0051.png)
where FSIZE is defined by the FSIZE= option. The same formula is used for the NMSIMP technique, but
is defined as the vertex with the lowest function value, and is defined as the vertex with the highest function value in the simplex. The default is 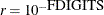 , where FDIGITS is the value of the FDIGITS=
option. The optional integer value n specifies the number of successive iterations for which the criterion must be satisfied before the process can terminate.
, where FDIGITS is the value of the FDIGITS=
option. The optional integer value n specifies the number of successive iterations for which the criterion must be satisfied before the process can terminate.
-
FCONV2=r<[n]>
FTOL2=r<[n]> -
specifies another function convergence criterion. For all techniques except NMSIMP, termination requires a small predicted reduction
![\[ df^{(k)} \approx f(\btheta ^{(k)}) - f(\btheta ^{(k)} + \mb{s}^{(k)}) \]](images/statug_nlmixed0053.png)
of the objective function. The predicted reduction
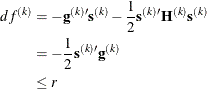
is computed by approximating the objective function f by the first two terms of the Taylor series and substituting the Newton step:
![\[ \mb{s}^{(k)} = - [\mb{H}^{(k)}]^{-1} \mb{g}^{(k)} \]](images/statug_nlmixed0055.png)
For the NMSIMP technique, termination requires a small standard deviation of the function values of the
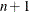 simplex vertices
simplex vertices 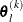 ,
, 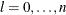 ,
,
![\[ \sqrt { \frac{1}{n+1} \sum _ l \left[ f(\btheta _ l^{(k)}) - \overline{f}(\btheta ^{(k)}) \right]^2 } \leq r \]](images/statug_nlmixed0059.png)
where
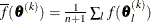 . If there are
. If there are 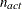 boundary constraints active at , the mean and standard deviation are computed only for the
boundary constraints active at , the mean and standard deviation are computed only for the 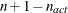 unconstrained vertices. The default value is r = 1E–6 for the NMSIMP technique and r = 0 otherwise. The optional integer value n specifies the number of successive iterations for which the criterion must be satisfied before the process can terminate.
unconstrained vertices. The default value is r = 1E–6 for the NMSIMP technique and r = 0 otherwise. The optional integer value n specifies the number of successive iterations for which the criterion must be satisfied before the process can terminate.
- FD <= FORWARD | CENTRAL | r>
-
specifies that all derivatives be computed using finite difference approximations. The following specifications are permitted:
- FD
-
is equivalent to FD=100.
- FD=CENTRAL
-
uses central differences.
- FD=FORWARD
-
uses forward differences.
- FD=r
-
uses central differences for the initial and final evaluations of the gradient and for the Hessian. During iteration, start with forward differences and switch to a corresponding central-difference formula during the iteration process when one of the following two criteria is satisfied:
Note that the FD and FDHESSIAN options cannot apply at the same time. The FDHESSIAN option is ignored when only first-order derivatives are used. See the section Finite-Difference Approximations of Derivatives for more information.
-
FDHESSIAN<=FORWARD | CENTRAL>
FDHES<=FORWARD | CENTRAL>
FDH<=FORWARD | CENTRAL> -
specifies that second-order derivatives be computed using finite difference approximations based on evaluations of the gradients.
- FDHESSIAN=FORWARD
-
uses forward differences.
- FDHESSIAN=CENTRAL
-
uses central differences.
- FDHESSIAN
-
uses forward differences for the Hessian except for the initial and final output.
Note that the FD and FDHESSIAN options cannot apply at the same time. See the section Finite-Difference Approximations of Derivatives for more information.
- FDIGITS=r
-
specifies the number of accurate digits in evaluations of the objective function. Fractional values such as FDIGITS=4.7 are allowed. The default value is
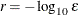 , where is the machine precision. The value of r is used to compute the interval size h for the computation of finite-difference approximations of the derivatives of the objective function and for the default
value of the FCONV=
option. If you specify more than one RANDOM statement, the default value is
, where is the machine precision. The value of r is used to compute the interval size h for the computation of finite-difference approximations of the derivatives of the objective function and for the default
value of the FCONV=
option. If you specify more than one RANDOM statement, the default value is 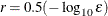 .
.
- FLOW
-
displays a message for each statement in the model program as it is executed. This debugging option is very rarely needed and produces voluminous output.
- FSIZE=r
-
specifies the FSIZE parameter of the relative function and relative gradient termination criteria. The default value is r = 0. For more information, see the FCONV= and GCONV= options.
-
G4=n
-
specifies a dimension to determine the type of generalized inverse to use when the approximate covariance matrix of the parameter estimates is singular. The default value of n is 60. See the section Covariance Matrix for more information.
-
GCONV=r<[n]>
GTOL=r<[n]> -
specifies a relative gradient convergence criterion. For all techniques except CONGRA and NMSIMP, termination requires that the normalized predicted function reduction is small,
![\[ \frac{ \mb{g}(\btheta ^{(k)})^\prime [\mb{H}^{(k)}]^{-1} \mb{g}(\btheta ^{(k)}) }{ {\max (|f(\btheta ^{(k)})|,\mbox{FSIZE}) } } \leq r \]](images/statug_nlmixed0066.png)
where FSIZE is defined by the FSIZE= option. For the CONGRA technique (where a reliable Hessian estimate H is not available), the following criterion is used:
![\[ \frac{ \parallel \mb{g}(\btheta ^{(k)}) \parallel _2^2 \quad \parallel \mb{s}(\btheta ^{(k)}) \parallel _2 }{\parallel \mb{g}(\btheta ^{(k)}) - \mb{g}(\btheta ^{(k-1)}) \parallel _2 \max (|f(\btheta ^{(k)})|,\mbox{FSIZE}) } \leq r \]](images/statug_nlmixed0067.png)
This criterion is not used by the NMSIMP technique.
The default value is r = 1E–8. The optional integer value n specifies the number of successive iterations for which the criterion must be satisfied before the process can terminate. If you specify more than one RANDOM statement, the default value is r = 1E–6.
-
HESCAL= 0 | 1 | 2 | 3
HS=0 | 1 | 2 | 3 -
specifies the scaling version of the Hessian matrix used in NRRIDG, TRUREG, NEWRAP, or DBLDOG optimization.
If HS is not equal to 0, the first iteration and each restart iteration sets the diagonal scaling matrix
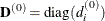 :
:
![\[ d_ i^{(0)} = \sqrt {\max (|H^{(0)}_{i,i}|,\epsilon )} \]](images/statug_nlmixed0069.png)
where
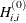 are the diagonal elements of the Hessian. In every other iteration, the diagonal scaling matrix is updated depending on the HS option:
are the diagonal elements of the Hessian. In every other iteration, the diagonal scaling matrix is updated depending on the HS option:
In each scaling update,
is the relative machine precision. The default value is HS=0. Scaling of the Hessian can be time-consuming in the case where
general linear constraints are active.
- HESS
-
requests the display of the final Hessian matrix after optimization. If you also specify the START option, then the Hessian at the starting values is also printed.
-
INHESSIAN<=r>
INHESS<=r> -
specifies how the initial estimate of the approximate Hessian is defined for the quasi-Newton techniques QUANEW and DBLDOG. There are two alternatives:
-
If you do not use the r specification, the initial estimate of the approximate Hessian is set to the Hessian at
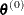 .
.
-
If you do use the r specification, the initial estimate of the approximate Hessian is set to the multiple of the identity matrix,
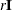 .
.
By default, if you do not specify the option INHESSIAN=r, the initial estimate of the approximate Hessian is set to the multiple of the identity matrix
, where the scalar r is computed from the magnitude of the initial gradient.
-
- INSTEP=r
-
reduces the length of the first trial step during the line search of the first iterations. For highly nonlinear objective functions, such as the EXP function, the default initial radius of the trust-region algorithm TRUREG or DBLDOG or the default step length of the line-search algorithms can result in arithmetic overflows. If this occurs, you should specify decreasing values of
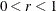 such as INSTEP=1E–1, INSTEP=1E–2, INSTEP=1E–4, and so on, until the iteration starts successfully.
such as INSTEP=1E–1, INSTEP=1E–2, INSTEP=1E–4, and so on, until the iteration starts successfully.
-
For trust-region algorithms (TRUREG, DBLDOG), the INSTEP= option specifies a factor
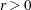 for the initial radius
for the initial radius 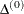 of the trust region. The default initial trust-region radius is the length of the scaled gradient. This step corresponds
to the default radius factor of r = 1.
of the trust region. The default initial trust-region radius is the length of the scaled gradient. This step corresponds
to the default radius factor of r = 1.
-
For line-search algorithms (NEWRAP, CONGRA, QUANEW), the INSTEP= option specifies an upper bound for the initial step length for the line search during the first five iterations. The default initial step length is r = 1.
-
For the Nelder-Mead simplex algorithm, using TECH= NMSIMP, the INSTEP=r option defines the size of the start simplex.
For more details, see the section Computational Problems.
-
- ITDETAILS
-
requests a more complete iteration history, including the current values of the parameter estimates, their gradients, and additional optimization statistics. For further details, see the section Iterations.
-
LCDEACT=r
LCD=r -
specifies a threshold r for the Lagrange multiplier that determines whether an active inequality constraint remains active or can be deactivated. During minimization, an active inequality constraint can be deactivated only if its Lagrange multiplier is less than the threshold value
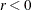 . The default value is
. The default value is
![\[ r = - \min (0.01, \max (0.1 \times \mr{ABSGCONV}, 0.001 \times \mr{gmax}^{(k)})) \]](images/statug_nlmixed0081.png)
where ABSGCONV is the value of the absolute gradient criterion, and
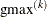 is the maximum absolute element of the (projected) gradient
is the maximum absolute element of the (projected) gradient 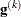 or
or 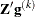 . (See the section Active Set Methods for a definition of
. (See the section Active Set Methods for a definition of 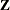 .)
.)
-
LCEPSILON=r
LCEPS=r
LCE=r
-
specifies the range for active and violated boundary constraints. The default value is r = 1E–8. During the optimization process, the introduction of rounding errors can force PROC NLMIXED to increase the value of r by a factor of
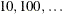 . If this happens, it is indicated by a message displayed in the log.
. If this happens, it is indicated by a message displayed in the log.
-
LCSINGULAR=r
LCSING=r
LCS=r
-
specifies a criterion r, used in the update of the QR decomposition, that determines whether an active constraint is linearly dependent on a set of other active constraints. The default value is r = 1E–8. The larger r becomes, the more the active constraints are recognized as being linearly dependent. If the value of r is larger than 0.1, it is reset to 0.1.
-
LINESEARCH=i
LIS=i -
specifies the line-search method for the CONGRA, QUANEW, and NEWRAP optimization techniques. See Fletcher (1987) for an introduction to line-search techniques. The value of i can be
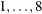 . For CONGRA, QUANEW and NEWRAP, the default value is i = 2.
. For CONGRA, QUANEW and NEWRAP, the default value is i = 2.
- 1
-
specifies a line-search method that needs the same number of function and gradient calls for cubic interpolation and cubic extrapolation; this method is similar to one used by the Harwell subroutine library.
- 2
-
specifies a line-search method that needs more function than gradient calls for quadratic and cubic interpolation and cubic extrapolation; this method is implemented as shown in Fletcher (1987) and can be modified to an exact line search by using the LSPRECISION= option.
- 3
-
specifies a line-search method that needs the same number of function and gradient calls for cubic interpolation and cubic extrapolation; this method is implemented as shown in Fletcher (1987) and can be modified to an exact line search by using the LSPRECISION= option.
- 4
-
specifies a line-search method that needs the same number of function and gradient calls for stepwise extrapolation and cubic interpolation.
- 5
-
specifies a line-search method that is a modified version of LIS=4.
- 6
-
specifies golden section line search (Polak, 1971), which uses only function values for linear approximation.
- 7
-
specifies bisection line search (Polak, 1971), which uses only function values for linear approximation.
- 8
-
specifies the Armijo line-search technique (Polak, 1971), which uses only function values for linear approximation.
- LIST
-
displays the model program and variable lists. The LIST option is a debugging feature and is not normally needed.
- LISTCODE
-
displays the derivative tables and the compiled program code. The LISTCODE option is a debugging feature and is not normally needed.
- LISTDEP
-
produces a report that lists, for each variable in the program, the variables that depend on it and on which it depends. The LISTDEP option is a debugging feature and is not normally needed.
- LISTDER
-
displays a table of derivatives. This table lists each nonzero derivative computed for the problem. The LISTDER option is a debugging feature and is not normally needed.
- LOGNOTE<=n>
-
writes periodic notes to the log that describe the current status of computations. It is designed for use with analyses requiring extensive CPU resources. The optional integer value n specifies the desired level of reporting detail. The default is n = 1. Choosing n = 2 adds information about the objective function values at the end of each iteration. The most detail is obtained with n = 3, which also reports the results of function evaluations within iterations.
-
LSPRECISION=r
LSP=r -
specifies the degree of accuracy that should be obtained by the line-search algorithms LIS=2 and LIS=3. Usually an imprecise line search is inexpensive and successful. For more difficult optimization problems, a more precise and expensive line search might be necessary (Fletcher, 1987). The second line-search method (which is the default for the NEWRAP, QUANEW, and CONGRA techniques) and the third line-search method approach exact line search for small LSPRECISION= values. If you have numerical problems, you should try to decrease the LSPRECISION= value to obtain a more precise line search. The default values are shown in the following table.
TECH=
UPDATE=
LSP default
QUANEW
DBFGS, BFGS
r = 0.4
QUANEW
DDFP, DFP
r = 0.06
CONGRA
all
r = 0.1
NEWRAP
no update
r = 0.9
For more details, see Fletcher (1987).
-
MAXFUNC=i
MAXFU=i -
specifies the maximum number i of function calls in the optimization process. The default values are as follows:
-
TRUREG, NRRIDG, NEWRAP: 125
-
QUANEW, DBLDOG: 500
-
CONGRA: 1000
-
NMSIMP: 3000
Note that the optimization can terminate only after completing a full iteration. Therefore, the number of function calls that is actually performed can exceed the number that is specified by the MAXFUNC= option.
-
-
MAXITER=i
MAXIT=i -
specifies the maximum number i of iterations in the optimization process. The default values are as follows:
-
TRUREG, NRRIDG, NEWRAP: 50
-
QUANEW, DBLDOG: 200
-
CONGRA: 400
-
NMSIMP: 1000
These default values are also valid when i is specified as a missing value.
-
- MAXSTEP=r<[n]>
-
specifies an upper bound for the step length of the line-search algorithms during the first n iterations. By default, r is the largest double-precision value and n is the largest integer available. Setting this option can improve the speed of convergence for the CONGRA, QUANEW, and NEWRAP techniques.
- MAXTIME=r
-
specifies an upper limit of r seconds of CPU time for the optimization process. The time checked only at the end of each iteration. Therefore, the actual run time might be longer than the specified time. By default, CPU time is not limited. The actual running time includes the rest of the time needed to finish the iteration and the time needed to generate the output of the results.
- METHOD=value
-
specifies the method for approximating the integral of the likelihood over the random effects. Valid values are as follows:
-
MINITER=i
MINIT=i -
specifies the minimum number of iterations. The default value is 0. If you request more iterations than are actually needed for convergence to a stationary point, the optimization algorithms can behave strangely. For example, the effect of rounding errors can prevent the algorithm from continuing for the required number of iterations.
-
MSINGULAR=r
MSING=r
-
specifies a relative singularity criterion for the computation of the inertia (number of positive, negative, and zero eigenvalues) of the Hessian and its projected forms. The default value is 1E–12 if you do not specify the SINGHESS= option; otherwise, the default value is
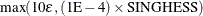 . See the section Covariance Matrix for more information.
. See the section Covariance Matrix for more information.
- NOAD
-
requests that the Gaussian quadrature be nonadaptive; that is, the quadrature points are centered at zero for each of the random effects and the current random-effects variance matrix is used as the scale matrix.
- NOADSCALE
-
requests nonadaptive scaling for adaptive Gaussian quadrature; that is, the quadrature points are centered at the empirical Bayes estimates for the random effects, but the current random-effects variance matrix is used as the scale matrix. By default, the observed Hessian from the current empirical Bayes estimates is used as the scale matrix.
- NOSORTSUB
-
requests that the data be processed sequentially and forms a new subject whenever the value of the SUBJECT= variable changes from the previous observation. This option enables PROC NLMIXED to use the behavior from SAS/STAT 12.3 and previous releases, in which the clusters are constructed by sequential processing. By default, starting with SAS/STAT 13.1, PROC NLMIXED constructs the clusters by using each of the unique SUBJECT= variable values, whether the input data set is sorted or not.
If you specify more than one RANDOM statement, this option is ignored.
-
OPTCHECK<=r
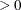 >
>
-
computes the function values
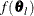 of a grid of points
of a grid of points 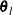 in a ball of radius of r about
in a ball of radius of r about 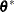 . If you specify the OPTCHECK option without factor r, the default value is r = 0.1 at the starting point and r = 0.01 at the terminating point. If a point
. If you specify the OPTCHECK option without factor r, the default value is r = 0.1 at the starting point and r = 0.01 at the terminating point. If a point 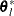 is found with a better function value than
is found with a better function value than 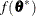 , then optimization is restarted at .
, then optimization is restarted at .
- OUTQ=SAS-data-set
-
specifies an output data set that contains the quadrature points used for numerical integration.
- OUTR=SAS-data-set
-
specifies an output data set that contains empirical Bayes estimates of the random effects of all hierarchies and their approximate standard errors.
-
QFAC=r
-
specifies the additive factor used to adaptively search for the number of quadrature points. For METHOD= GAUSS, the search sequence is 1, 3, 5, 7, 9, 11, 11 + r, 11 + 2r, …, where the default value of r is 10. For METHOD= ISAMP, the search sequence is 10, 10 + r, 10 + 2r, …, where the default value of r is 50.
-
QMAX=r
-
specifies the maximum number of quadrature points permitted before the adaptive search is aborted. The default values are 31 for adaptive Gaussian quadrature, 61 for nonadaptive Gaussian quadrature, 160 for adaptive importance sampling, and 310 for nonadaptive importance sampling.
-
QPOINTS=n
-
specifies the number of quadrature points to be used during evaluation of integrals. For METHOD= GAUSS, n equals the number of points used in each dimension of the random effects, resulting in a total of
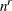 points, where r is the number of dimensions. For METHOD=
ISAMP, n specifies the total number of quadrature points regardless of the dimension of the random effects. By default, the number
of quadrature points is selected adaptively, and this option disables the adaptive search.
points, where r is the number of dimensions. For METHOD=
ISAMP, n specifies the total number of quadrature points regardless of the dimension of the random effects. By default, the number
of quadrature points is selected adaptively, and this option disables the adaptive search.
-
QSCALEFAC=r
-
specifies a multiplier for the scale matrix used during quadrature calculations. The default value is 1.0.
-
QTOL=r
-
specifies the tolerance used to adaptively select the number of quadrature points. When the relative difference between two successive likelihood calculations is less than r, then the search terminates and the lesser number of quadrature points is used during the subsequent optimization process. The default value is 1E–4.
-
RESTART=i
REST=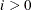
-
specifies that the QUANEW or CONGRA algorithm is restarted with a steepest descent/ascent search direction after, at most, i iterations. Default values are as follows:
-
CONGRA: UPDATE=PB: restart is performed automatically, i is not used.
-
CONGRA: UPDATE
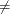 PB:
PB: 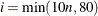 , where n is the number of parameters.
, where n is the number of parameters.
-
QUANEW: i is the largest integer available.
-
- SEED=i
-
specifies the random number seed for METHOD= ISAMP. If you do not specify a seed, or if you specify a value less than or equal to zero, the seed is generated from reading the time of day from the computer clock. The value must be less than
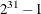 .
.
-
SINGCHOL=r
-
specifies the singularity criterion r for Cholesky roots of the random-effects variance matrix and scale matrix for adaptive Gaussian quadrature. The default value is 1E4 times the machine epsilon; this product is approximately 1E–12 on most computers.
-
SINGHESS=r
-
specifies the singularity criterion r for the inversion of the Hessian matrix. The default value is 1E–8. See the ASINGULAR, MSINGULAR=, and VSINGULAR= options for more information.
-
SINGSWEEP=r
-
specifies the singularity criterion r for inverting the variance matrix in the first-order method and the empirical Bayes Hessian matrix. The default value is 1E4 times the machine epsilon; this product is approximately 1E–12 on most computers.
-
SINGVAR=r
-
specifies the singularity criterion r below which statistical variances are considered to equal zero. The default value is 1E4 times the machine epsilon; this product is approximately 1E–12 on most computers.
- START
-
requests that the gradient of the log likelihood at the starting values be displayed. If you also specify the HESS option, then the starting Hessian is displayed as well.
-
SUBGRADIENT=SAS-data-set
SUBGRAD=SAS-data-set -
specifies a SAS data set that contains subgradients. In models that use the RANDOM statement, the data set contains the subject-specific gradients of the integrated, marginal log likelihood with respect to all parameters. The sum of the subject-specific gradients equals the gradient that is reported in the "Parameter Estimates" table. The data set contains a variable that identifies the subjects.
In models that do not use the RANDOM statement, the data set contains the observation-wise gradient. The variable identifying the SUBJECT= is then replaced with the
Observation. This observation counter includes observations not used in the analysis and is reset in each BY group.Saving disaggregated gradient information by specifying the SUBGRADIENT= option requires that you also specify METHOD= GAUSS or METHOD= ISAMP.
If you specify more than one RANDOM statement, this option is ignored.
-
TECHNIQUE=value
TECH=value -
specifies the optimization technique. By default, TECH = QUANEW. Valid values are as follows:
-
CONGRA performs a conjugate-gradient optimization, which can be more precisely specified with the UPDATE= option and modified with the LINESEARCH= option. When you specify this option, UPDATE= PB by default.
-
DBLDOG performs a version of double-dogleg optimization, which can be more precisely specified with the UPDATE= option. When you specify this option, UPDATE= DBFGS by default.
-
NONE does not perform any optimization. This option can be used as follows:
-
to perform a grid search without optimization
-
to compute estimates and predictions that cannot be obtained efficiently with any of the optimization techniques
-
-
NEWRAP performs a Newton-Raphson optimization combining a line-search algorithm with ridging. The line-search algorithm LIS= 2 is the default method.
-
QUANEW performs a quasi-Newton optimization, which can be defined more precisely with the UPDATE= option and modified with the LINESEARCH= option. This is the default estimation method.
-
- TRACE
-
displays the result of each operation in each statement in the model program as it is executed. This debugging option is very rarely needed, and it produces voluminous output.
-
UPDATE=method
UPD=method -
specifies the update method for the quasi-Newton, double-dogleg, or conjugate-gradient optimization technique. Not every update method can be used with each optimizer. See the section Optimization Algorithms for more information.
Valid methods are as follows:
-
BFGS performs the original Broyden, Fletcher, Goldfarb, and Shanno (BFGS) update of the inverse Hessian matrix.
-
DBFGS performs the dual BFGS update of the Cholesky factor of the Hessian matrix. This is the default update method.
-
DDFP performs the dual Davidon, Fletcher, and Powell (DFP) update of the Cholesky factor of the Hessian matrix.
-
DFP performs the original DFP update of the inverse Hessian matrix.
-
PB performs the automatic restart update method of Powell (1977) and Beale (1972).
-
FR performs the Fletcher-Reeves update (Fletcher, 1987).
-
PR performs the Polak-Ribiere update (Fletcher, 1987).
-
CD performs a conjugate-descent update of Fletcher (1987).
-
-
VSINGULAR=r
VSING=r
-
specifies a relative singularity criterion for the computation of the inertia (number of positive, negative, and zero eigenvalues) of the Hessian and its projected forms. The default value is r = 1E–8 if the SINGHESS= option is not specified, and it is the value of SINGHESS= option otherwise. See the section Covariance Matrix for more information.
-
XCONV=r<[n]>
XTOL=r<[n]> -
specifies the relative parameter convergence criterion. For all techniques except NMSIMP, termination requires a small relative parameter change in subsequent iterations:
![\[ \frac{ {\max _ j |\theta _ j^{(k)} - \theta _ j^{(k-1)}|} }{\max (|\theta _ j^{(k)}|,|\theta _ j^{(k-1)}|,\mbox{XSIZE})} \leq r \]](images/statug_nlmixed0100.png)
For the NMSIMP technique, the same formula is used, but
is defined as the vertex with the lowest function value and is defined as the vertex with the highest function value in the simplex.
The default value is r = 1E–8 for the NMSIMP technique and r = 0 otherwise. The optional integer value n specifies the number of successive iterations for which the criterion must be satisfied before the process can be terminated.
- XREF
-
displays a cross-reference of the variables in the program showing where each variable is referenced or given a value. The XREF listing does not include derivative variables. This option is a debugging feature and is not normally needed.
-
XSIZE=r
-
specifies the XSIZE parameter of the relative parameter termination criterion. The default value is r = 0. For more details, see the XCONV= option.