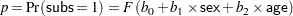Example 74.3 Logistic Regression
In this example, a series of people are asked whether or not they would subscribe to a new newspaper. For each person, the variables sex (Female, Male), age, and subs (1=yes,0=no) are recorded. The PROBIT procedure is used to fit a logistic regression model to the probability of a positive response (subscribing) as a function of the variables sex and age. Specifically, the probability of subscribing is modeled as
where  is the cumulative logistic distribution function.
is the cumulative logistic distribution function.
By default, the PROBIT procedure models the probability of the lower response level for binary data. One way to model 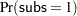 is to format the response variable so that the formatted value corresponding to
is to format the response variable so that the formatted value corresponding to 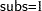 is the lower level. The following statements format the values of subs as 1 = ’accept’ and 0 = ’reject’, so that PROBIT models
is the lower level. The following statements format the values of subs as 1 = ’accept’ and 0 = ’reject’, so that PROBIT models 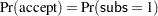 . They produce Output 74.3.1.
. They produce Output 74.3.1.
data news;
input sex $ age subs @@;
datalines;
Female 35 0 Male 44 0
Male 45 1 Female 47 1
Female 51 0 Female 47 0
Male 54 1 Male 47 1
Female 35 0 Female 34 0
Female 48 0 Female 56 1
Male 46 1 Female 59 1
Female 46 1 Male 59 1
Male 38 1 Female 39 0
Male 49 1 Male 42 1
Male 50 1 Female 45 0
Female 47 0 Female 30 1
Female 39 0 Female 51 0
Female 45 0 Female 43 1
Male 39 1 Male 31 0
Female 39 0 Male 34 0
Female 52 1 Female 46 0
Male 58 1 Female 50 1
Female 32 0 Female 52 1
Female 35 0 Female 51 0
;
proc format;
value subscrib 1 = 'accept' 0 = 'reject';
run;
proc probit data=news;
class subs sex;
model subs=sex age / d=logistic itprint;
format subs subscrib.;
run;
Output 74.3.1
Logistic Regression of Subscription Status
The Probit Procedure
| 0 |
-27.725887 |
0 |
0 |
0 |
| 0 |
-20.142659 |
-3.634567629 |
-1.648455751 |
0.1051634384 |
| 0 |
-19.52245 |
-5.254865196 |
-2.234724956 |
0.1506493473 |
| 0 |
-19.490439 |
-5.728485385 |
-2.409827238 |
0.1639621828 |
| 0 |
-19.490303 |
-5.76187293 |
-2.422349862 |
0.1649007124 |
| 0 |
-19.490303 |
-5.7620267 |
-2.422407743 |
0.1649050312 |
| 0 |
-19.490303 |
-5.7620267 |
-2.422407743 |
0.1649050312 |
| WORK.NEWS |
| subs |
| 40 |
| Logistic |
| -19.49030281 |
| 2 |
accept reject |
| 2 |
Female Male |
| -5.95557E-12 |
8.768324E-10 |
-1.6367E-8 |
| 6.4597397447 |
4.6042218284 |
292.04051848 |
| 4.6042218284 |
4.6042218284 |
216.20829515 |
| 292.04051848 |
216.20829515 |
13487.329973 |
| |
1 |
-5.7620 |
2.7635 |
-11.1783 |
-0.3458 |
4.35 |
0.0371 |
| Female |
1 |
-2.4224 |
0.9559 |
-4.2959 |
-0.5489 |
6.42 |
0.0113 |
| Male |
0 |
0.0000 |
. |
. |
. |
. |
. |
| |
1 |
0.1649 |
0.0652 |
0.0371 |
0.2927 |
6.40 |
0.0114 |
Output 74.3.1 shows that there appears to be an effect due to both the variables sex and age. The positive coefficient for age indicates that older people are more likely to subscribe than younger people. The negative coefficient for sex indicates that females are less likely to subscribe than males.
Copyright © SAS Institute Inc. All rights reserved.