The HPNLMOD Procedure

PROC HPNLMOD <options> ;
The PROC HPNLMOD statement invokes the procedure. Table 10.1 summarizes important options in the PROC HPNLMOD statement by function. These and other options in the PROC HPNLMOD statement are then described fully in alphabetical order.
Table 10.1: PROC HPNLMOD Statement Options
|
Option |
Description |
|---|---|
|
Basic Options |
|
|
Specifies the input data set |
|
|
Specifies the output data set |
|
|
Output Options |
|
|
Specifies the correlation matrix |
|
|
Specifies the covariance matrix |
|
|
Specifies the correlation matrix of additional estimates |
|
|
Specifies the covariance matrix of additional estimates |
|
|
Specifies the default degrees of freedom |
|
|
Suppresses ODS output |
|
|
Suppresses output about iterations within the optimization process |
|
|
Optimization Options |
|
|
Tunes an absolute function convergence criterion |
|
|
Tunes an absolute difference function convergence criterion |
|
|
Tunes the absolute gradient convergence criterion |
|
|
Tunes the relative function convergence criterion |
|
|
Tunes the relative gradient convergence criterion |
|
|
Chooses the maximum number of iterations in any optimization |
|
|
Specifies the maximum number of function evaluations in any optimization |
|
|
Specifies the upper limit seconds of CPU time for any optimization |
|
|
Specifies the minimum number of iterations in any optimization |
|
|
Selects the optimization technique |
|
|
Tolerance Options |
|
|
Tunes the general singularity criterion |
|
|
User-Defined Format Options |
|
|
Specifies a file reference for a format stream |
|
|
Specifies a file name for a format stream |
|
You can specify the following options in the PROC HPNLMOD statement.
-
ABSCONV=r
ABSTOL=r -
specifies an absolute function convergence criterion. For minimization, termination requires
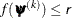 , where
, where 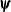 is the vector of parameters in the optimization and
is the vector of parameters in the optimization and 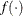 is the objective function. The default value of
is the objective function. The default value of  is the negative square root of the largest double-precision value, which serves only as a protection against overflow.
is the negative square root of the largest double-precision value, which serves only as a protection against overflow.
-
ABSFCONV=r <n>
ABSFTOL=r<n> -
specifies an absolute difference function convergence criterion. For all techniques except the Nelder-Mead simplex (NMSIMP) technique, termination requires a small change of the function value in successive iterations:
![\[ |f(\bpsi ^{(k-1)}) - f(\bpsi ^{(k)})| \leq r \]](images/stathpug_hpnlin0012.png)
Here,
denotes the vector of parameters that participate in the optimization, and is the objective function. The same formula is used for the NMSIMP technique, but 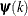 is defined as the vertex that has the lowest function value, and
is defined as the vertex that has the lowest function value, and 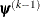 is defined as the vertex that has the highest function value in the simplex. The default value is
is defined as the vertex that has the highest function value in the simplex. The default value is 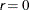 . The optional integer value
. The optional integer value  specifies the number of successive iterations for which the criterion must be satisfied before the process can be terminated.
specifies the number of successive iterations for which the criterion must be satisfied before the process can be terminated.
-
ABSGCONV=r <n>
ABSGTOL=r<n> -
specifies an absolute gradient convergence criterion. Termination requires the maximum absolute gradient element to be small:
![\[ \max _ j |g_ j(\bpsi ^{(k)})| \leq r \]](images/stathpug_hpnlin0017.png)
Here,
denotes the vector of parameters that participate in the optimization, and 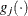 is the gradient of the objective function with respect to the
is the gradient of the objective function with respect to the 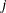 th parameter. This criterion is not used by the NMSIMP technique. The default value is
th parameter. This criterion is not used by the NMSIMP technique. The default value is 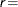 1E
1E 5. The optional integer value specifies the number of successive iterations for which the criterion must be satisfied before the process can be terminated.
5. The optional integer value specifies the number of successive iterations for which the criterion must be satisfied before the process can be terminated.
-
ALPHA=

-
specifies the level of significance
that is used in the construction of 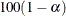 % confidence intervals. The value must be strictly between 0 and 1; the default value of
% confidence intervals. The value must be strictly between 0 and 1; the default value of 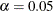 results in 95% intervals. This value is used as the default confidence level for limits that are computed in the “Parameter Estimates” table and is used in the LOWER and UPPER options in the PREDICT statement.
results in 95% intervals. This value is used as the default confidence level for limits that are computed in the “Parameter Estimates” table and is used in the LOWER and UPPER options in the PREDICT statement.
- CORR
-
requests the approximate correlation matrix for the parameter estimates.
- COV
-
requests the approximate covariance matrix for the parameter estimates.
- DATA=SAS-data-set
-
names the SAS data set to be used by PROC HPNLMOD. The default is the most recently created data set.
If PROC HPNLMOD executes in distributed mode, the input data are distributed to memory on the appliance nodes and analyzed in parallel, unless the data are already distributed in the appliance database. In the latter case, PROC HPNLMOD reads the data alongside the distributed database. For more information about the various execution modes, see the section Processing Modes; for more information about the alongside-the-database model, see the section Alongside-the-Database Execution.
- DF=n
-
specifies the default number of degrees of freedom to use in the calculation of
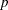 -values and confidence limits for additional parameter estimates.
-values and confidence limits for additional parameter estimates.
- ECORR
-
requests the approximate correlation matrix for all expressions that are specified in ESTIMATE statements.
- ECOV
-
requests the approximate covariance matrix for all expressions that are specified in ESTIMATE statements.
-
FCONV=r<n>
FTOL=r<n> -
specifies a relative function convergence criterion. For all techniques except NMSIMP, termination requires a small relative change of the function value in successive iterations:
![\[ \frac{|f(\bpsi ^{(k)}) - f(\bpsi ^{(k-1)})|}{|f(\bpsi ^{(k-1)})|} \leq r \]](images/stathpug_hpnlin0026.png)
Here,
denotes the vector of parameters that participate in the optimization, and is the objective function. The same formula is used for the NMSIMP technique, but 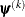 is defined as the vertex that has the lowest function value, and is defined as the vertex that has the highest function value in the simplex. The default is
is defined as the vertex that has the lowest function value, and is defined as the vertex that has the highest function value in the simplex. The default is 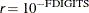 , where FDIGITS is by default
, where FDIGITS is by default 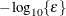 and
and  is the machine precision. The optional integer value specifies the number of successive iterations for which the criterion must be satisfied before the process can terminate.
is the machine precision. The optional integer value specifies the number of successive iterations for which the criterion must be satisfied before the process can terminate.
- FMTLIBXML=file-ref
-
specifies the file reference for the XML stream that contains the user-defined format definitions. User-defined formats are handled differently in a distributed computing environment than they are handled in other SAS products. For information about how to generate a XML stream for your formats, see the section Working with Formats.
-
GCONV=r<n>
GTOL=r<n> -
specifies a relative gradient convergence criterion. For all techniques except the conjugate gradient (CONGRA) and NMSIMP techniques, termination requires that the normalized predicted function reduction be small:
![\[ \frac{\mb {g}(\bpsi ^{(k)})^\prime [\bH ^{(k)}]^{-1} \mb {g}(\bpsi ^{(k)})}{|f(\bpsi ^{(k)})| } \leq r \]](images/stathpug_hpnlin0031.png)
Here,
denotes the vector of parameters that participate in the optimization, is the objective function, and 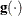 is the gradient. For the CONGRA technique (where a reliable Hessian estimate
is the gradient. For the CONGRA technique (where a reliable Hessian estimate 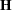 is not available), the following criterion is used:
is not available), the following criterion is used:
![\[ \frac{\parallel \mb {g}(\bpsi ^{(k)}) \parallel _2^2 \quad \parallel \mb {s}(\bpsi ^{(k)}) \parallel _2}{\parallel \mb {g}(\bpsi ^{(k)}) - \mb {g}(\bpsi ^{(k-1)}) \parallel _2 |f(\bpsi ^{(k)})| } \leq r \]](images/stathpug_hpnlin0034.png)
This criterion is not used by the NMSIMP technique. The default value is
1E8. The optional integer value specifies the number of successive iterations for which the criterion must be satisfied before the process can terminate.
-
MAXFUNC=n
MAXFU=n -
specifies the maximum number of function calls in the optimization process. The default values are as follows, depending on the optimization technique (which you specify in the TECHNIQUE= option):
-
TRUREG, NRRIDG, NEWRAP:
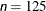
-
QUANEW, DBLDOG:
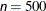
-
CONGRA:
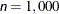
-
NMSIMP:
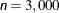
Optimization can terminate only after completing a full iteration. Therefore, the number of function calls that are actually performed can exceed n.
-
-
MAXITER=n
MAXIT=n -
specifies the maximum number of iterations in the optimization process. The default values are as follows, depending on the optimization technique (which you specify in the TECHNIQUE= option):
-
TRUREG, NRRIDG, NEWRAP:
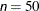
-
QUANEW, DBLDOG:
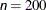
-
CONGRA:
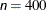
-
NMSIMP:
These default values also apply when
is specified as a missing value.
-
- MAXTIME=r
-
specifies an upper limit of
seconds of CPU time for the optimization process. The default value is the largest floating-point double representation of
your computer. This time that is specified by r is checked only once at the end of each iteration. Therefore, the actual running time can be longer than r.
-
MINITER=n
MINIT=n -
specifies the minimum number of iterations. The default value is 0. If you request more iterations than are actually needed for convergence to a stationary point, the optimization algorithms can behave strangely. For example, the effect of rounding errors can prevent the algorithm from continuing for the required number of iterations.
- NOITPRINT
- NOPRINT
- OUT=SAS-data-set
-
names the SAS data set to be created when one or more PREDICT statements are specified. A single OUT= data set is created to contain all predicted values when more than one PREDICT statement is specified. An error message is produced if a PREDICT statement is specified and an OUT= data set is not specified. For more information about output data sets in SAS high-performance analytical procedures, see the section Output Data Sets.
- SINGULAR=number
-
tunes the general singularity criterion that is applied in sweeps and inversions. The default is
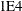 times the machine epsilon; this product is approximately 1E12 on most computers.
times the machine epsilon; this product is approximately 1E12 on most computers.
-
TECHNIQUE=keyword
TECH=keyword -
specifies the optimization technique for obtaining maximum likelihood estimates. You can choose from the following techniques by specifying the appropriate keyword:
- CONGRA
-
performs a conjugate-gradient optimization.
- DBLDOG
-
performs a version of double-dogleg optimization.
- LEVMAR
-
performs a Levenberg-Marquardt optimization.
- NEWRAP
-
performs a Newton-Raphson optimization that combines a line-search algorithm with ridging.
- NMSIMP
-
performs a Nelder-Mead simplex optimization.
- NONE
-
performs no optimization.
- NRRIDG
-
performs a Newton-Raphson optimization with ridging.
- QUANEW
-
performs a quasi-Newton optimization.
- TRUREG
-
performs a trust-region optimization.
The default value is TECHNIQUE=LEVMAR for least squares regression models and TECHNIQUE=NRRIDG for models where the distribution is specified.
- XMLFORMAT=filename
-
specifies the file name for the XML stream that contains the user-defined format definitions. User-defined formats are handled differently in a distributed computing environment than they are handled in other SAS products. For information about how to generate a XML stream for your formats, see the section Working with Formats.