| Input Data Sets |
DATA= Data Set
The DATA= data set provides the process measurement data for a Phase II analysis. When you specify a DATA= data set, you must also specify a LOADINGS= data set which contains the loadings for the principal components model that describes the in-control variation of the process. These loadings are used to score the new data in the DATA= data set. Each process variable in the LOADINGS= data set must be present in the DATA= data set.
Note: In this experimental version of PROC MVPMONITOR, it is not possible to produce an SPE chart for multiple observations per time point using a DATA= data set.
HISTORY= Data Set
The HISTORY= data set provides the input data set for a Phase I analysis, which contains process variable values in addition to principal component scores, multivariate summary statistics and other values computed by PROC MVPMODEL. You can produce a HISTORY= data set with PROC MVPMODEL by using the OUT= option. It is necessary to sort the HISTORY= data set again before using PROC MVPMONITOR. The re-sorted data set contains the 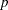 process measurement variables analyzed with PROC MVPMODEL, plus those listed in Table 11.1.
process measurement variables analyzed with PROC MVPMODEL, plus those listed in Table 11.1.
Variable |
Description |
|---|---|
Prin1–Prin |
Principal component scores |
R_ |
Residuals |
_NOBS_ |
Number of observations used in the analysis |
_SPE_ |
Squared prediction error (SPE) |
_SPEMEAN_ |
Mean SPE for a given time value |
_SPEVARI_ |
Variance of SPE for a given time value |
_TSQUARE_ |
|
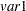 –R_
–R_
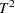 statistic computed from principal component scores
statistic computed from principal component scores A HISTORY= data set must include variables that contain principal component scores. The score variables names must consist of a common prefix followed by the numbers 1, 2, ..., j, where j is the number of principal components. By default, the common prefix is Prin. You can use the PREFIX= option to specify another prefix for score variables.
If the number of principal components is less than the total number of process variables, the HISTORY= data set should also contain residual variables. Residual variable names must consist of a common prefix with process variable names appended. The default residual variable prefix is R_. For example, if the process variables are A, B, and C, the default residual variable names are R_A, R_B, and R_C. You can use the RPREFIX= option to specify another residual variable prefix.
LOADINGS= Data Set
The LOADINGS= data set contains the eigenvalues of the correlation or covariance matrix used to construct the principal components model and the loadings for the model. You can produce a LOADINGS= data set with PROC MVPMODEL by using the OUTLOADINGS= option. Table 11.2 lists the variables that are required in a LOADINGS= data set.
Variable |
Description |
|---|---|
_NOBS_ |
Number of observations used in the analysis |
_PC_ |
Principal component number; 0 for the observation that contains eigenvalues |
process variables |
Principal component loadings for process variables |
The LOADINGS= data set contains 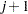 observations, where
observations, where  is the number of principal components in the model.
is the number of principal components in the model.
Note: This procedure is experimental.