| Robust Regression Examples |
Combining Robust Residual and Robust Distance
This section is based entirely on
Rousseeuw and Van Zomeren (1990).
Observations ![]() , which are far away from most of
the other observations, are called leverage points.
One classical method inspects the Mahalanobis
distances
, which are far away from most of
the other observations, are called leverage points.
One classical method inspects the Mahalanobis
distances ![]() to find outliers
to find outliers ![]() :
:
Note that the MVE subroutine prints the classical Mahalanobis
distances ![]() together with the robust distances
together with the robust distances ![]() .
In classical linear regression, the diagonal
elements
.
In classical linear regression, the diagonal
elements ![]() of the hat matrix
of the hat matrix
The definition of a leverage point is, therefore,
based entirely on the outlyingness of ![]() and is not related to the response value
and is not related to the response value ![]() .
By including the
.
By including the ![]() value in the definition,
Rousseeuw and Van Zomeren (1990) distinguish between
the following:
value in the definition,
Rousseeuw and Van Zomeren (1990) distinguish between
the following:
- Good leverage points are points
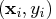 that
are close to the regression plane; that is, good leverage
points improve the precision of the regression coefficients.
that
are close to the regression plane; that is, good leverage
points improve the precision of the regression coefficients.
- Bad leverage points are points that
are far from the regression plane; that is, bad leverage
points reduce the precision of the regression coefficients.
Rousseeuw and Van Zomeren (1990) propose to plot the
standardized residuals of robust regression (LMS or LTS)
versus the robust distances ![]() obtained from MVE.
Two horizontal lines corresponding to residual
values of
obtained from MVE.
Two horizontal lines corresponding to residual
values of ![]() and -2.5 are useful to distinguish
between small and large residuals, and one vertical
line corresponding to the
and -2.5 are useful to distinguish
between small and large residuals, and one vertical
line corresponding to the ![]() is
used to distinguish between small and large distances.
is
used to distinguish between small and large distances.
Example 9.6: Hawkins-Bradu-Kass Data
Example 9.7: Stackloss Data
Copyright © 2009 by SAS Institute Inc., Cary, NC, USA. All rights reserved.