G3GRID Procedure

Interpolation Methods
Bivariate Interpolation
Unless you specify the
SPLINE option, the G3GRID procedure is an interpolation procedure.
It calculates the z values
for x, y points that are missing from the input data set. The surface that
is formed by the interpolated data passes precisely through the data
points in the input data set.
This method of interpolation
works best for fairly smooth functions, with values given at uniformly
distributed points in the plane. If the data points in the input data
set are erratic, the default interpolated surface can be erratic.
This default method
is a modification of that described by Akima (1978). This method consists
of the following actions:
The estimates of the
first, and second derivatives are computed using the n nearest neighbors of the point, where n is the number specified in the GRID statement's
NEAR= option. A Delauney triangulation (Ripley 1981, p. 38), is used
for the default method. The coordinates of the triangles are available
in an output data set, if requested by the OUTTRI= option, in the
PROC G3GRID statement. This is the default interpolation method.
Spline Interpolation
If you specify the SPLINE
option, a method is used that produces either an interpolation. or
smoothing that is optimally smooth. See (Harder and Desmarais 1972,
Meinguet 1979, Green and Silverman 1994). The surface that is generated
can be thought of as one that would be formed if a stiff, thin metal
plate were forced through, or near the given data points. For large
data sets, this method is substantially more expensive than the default
method.
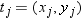
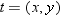



The coefficients c1, c2,..., cn, andd1, d2, d3 of this polynomial
are determined by the following equations:
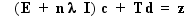

Spline Smoothing
Using the SMOOTH= option
in the GRID statement with the SPLINE option, enables you to produce
a smoothing spline. See Eubank (1988) for a general discussion of
spline smoothing. The value or values specified in the SMOOTH= option
are substituted for λ in the equation that is described in Spline Interpolation. A smoothing
spline trades closeness to the original data points for smoothness.
To find a value that produces the best balance between smoothness,
and fit to the original data, several values for the SMOOTH= option
can be run.