The TCOUNTREG Procedure (Experimental)
- Overview
- Getting Started
-
Syntax

-
Details
Specification of Regressors Missing Values Poisson Regression Negative Binomial Regression Zero-Inflated Count Regression Overview Zero-Inflated Poisson Regression Zero-Inflated Negative Binomial Regression Variable Selection Panel Data Analysis Computational Resources Nonlinear Optimization Options Covariance Matrix Types Displayed Output OUTPUT OUT= Data Set OUTEST= Data Set ODS Table Names
-
Examples
- References
| Variable Selection |
Variable Selection Using an Information Criterion
This type of variable selection uses either Akaike’s information criterion (AIC) or the Schwartz Bayesian criterion (SBC) and either a forward selection method or a backward elimination method.
Forward selection starts from a small subset of variables. In each step, the variable that gives the largest decrease in the value of the information criterion specified in the CRITER= option (AIC or SBC) is added. The process stops when the next candidate to be added does not reduce the value of the information criterion by more than the amount specified in the LSTOP= option in the MODEL statement.
Backward elimination starts from a larger subset of variables. In each step, one variable is dropped based on the information criterion chosen.
Variable Selection Using Penalized Likelihood
Variable selection in the linear regression context can be achieved by adding some form of penalty on the regression coefficients. One particular such form is 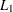 norm penalty, which leads to LASSO:
norm penalty, which leads to LASSO:
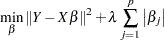 |
This penalty method is becoming more popular in linear regression, because of the computational development in the recent years. However, how to generalize the penalty method for variable selection to the more general statistical models is not trivial. Some work has been done for the generalized linear models, in the sense that the likelihood depends on the data through a linear combination of the parameters and the data:
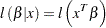 |
In the more general form, the likelihood as a function of the parameters can be denoted by 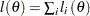 , where
, where 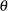 is a vector that can include any parameters and
is a vector that can include any parameters and 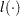 is the likelihood for each observation. For example, in the Poisson model,
is the likelihood for each observation. For example, in the Poisson model, 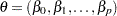 , and in the negative binomial model
, and in the negative binomial model 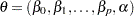 . The following discussion introduces the penalty method using the Poisson model as an example, but it applies similarly to the negative binomial model. The penalized likelihood function takes the form
. The following discussion introduces the penalty method using the Poisson model as an example, but it applies similarly to the negative binomial model. The penalized likelihood function takes the form
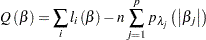 |
(30.1) |
Some desired properties for the penalty functions are unbiasedness, sparsity, and continuity. Unbiasedness means that the coefficients should be unbiased for significant variables. Sparsity means that the coefficients can be exactly zero when the penalty is large enough. Continuity means that the solution of the penalized problem is continuous in the data, which means that a small perturbation of the data does not change the estimation significantly.
The  norm penalty function used in the calculation is specified as:
norm penalty function used in the calculation is specified as:
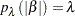 |
The main challenge for this penalized likelihood method is on the computation side. The penalty function is nondifferentiable at zero, which poses a computational problem for the optimization. To get around this nondifferentiability problem, Fan and Li (2001) suggest a local quadratic approximation for the penalty function. However, it is later found that the numerical performance is not satisfactory in a few aspects. Zou and Li (2008) proposed local linear approximation (LLA) to solve the problem (30.1) numerically. The algorithm replaces the penalty function with a linear approximation around a fixed point 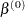 :
:
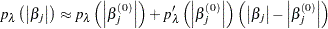 |
Then the problem can be solved iteratively. Start from 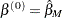 , which denotes the usual MLE estimate. For iteration
, which denotes the usual MLE estimate. For iteration 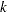 ,
,
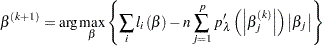 |
The algorithm stops when 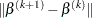 is small. To save computing time, you can also choose a maximum number of iterations. This number can be specified by the LLASTEPS= option.
is small. To save computing time, you can also choose a maximum number of iterations. This number can be specified by the LLASTEPS= option.
The objective function is nondifferentiable. The optimization problem can be solved using an optimization methods with contraints, by a variable transformation
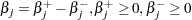 |
(30.2) |
For each fixed tuning parameter 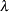 , you can solve the preceding optimization problem to obtain an estimate for
, you can solve the preceding optimization problem to obtain an estimate for 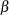 . Due to the property of the
. Due to the property of the  norm penalty, some of the coefficients in can be exactly zero. The remaining question is to choose the best tuning parameter . You can use either of the approaches described in the following subsections.
norm penalty, some of the coefficients in can be exactly zero. The remaining question is to choose the best tuning parameter . You can use either of the approaches described in the following subsections.
The GCV Approach
In this approach, the generalized cross-validation criteria (GCV) is computed for each value of on a predetermined grid 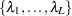 ; the value of that achieves the minimum of the GCV is the optimal tuning parameter. The maximum value
; the value of that achieves the minimum of the GCV is the optimal tuning parameter. The maximum value 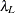 can be determined by lemma 1 in Park and Hastie (2007) as follows. Suppose
can be determined by lemma 1 in Park and Hastie (2007) as follows. Suppose 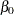 is free of penalty in the objective function. Let
is free of penalty in the objective function. Let 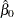 be the MLE of by forcing the rest of the parameters to be zero. Then the maximum value of is
be the MLE of by forcing the rest of the parameters to be zero. Then the maximum value of is
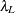 |
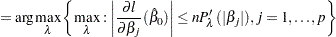 |
|||
 |
 |
You can compute the GCV by using the LASSO framework. In the last step of Newton-Raphson approximation, you have
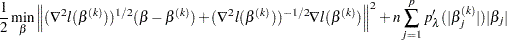 |
The solution 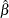 satisfies
satisfies
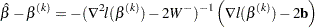 |
where
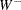 |
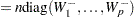 |
|||
 |
 |
|||
 |
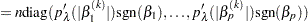 |
Note that the intercept term has no penalty on its absolute value, and therefore the 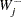 term that corresponds to the intercept is 0. More generally, you can make any parameter (such as the
term that corresponds to the intercept is 0. More generally, you can make any parameter (such as the  in the negative binomial model) in the likelihood function free of penalty, and you treat them the same as the intercept.
in the negative binomial model) in the likelihood function free of penalty, and you treat them the same as the intercept.
The effective number of parameters is
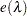 |
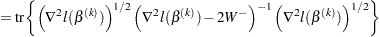 |
|||
|
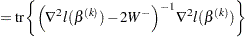 |
and the generalized cross-validation error is
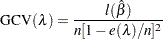 |
The GCV1 Approach
Another form of GCV uses the number of nonzero coefficients as the degrees-of-freedom:
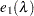 |
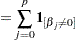 |
|||
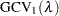 |
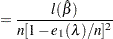 |
The standard errors follow the sandwich formula
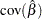 |
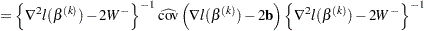 |
|||
|
 |
It is common practice to report only the standard errors of the nonzero parameters.
Note: This procedure is experimental.