The TCOUNTREG Procedure (Experimental)
- Overview
- Getting Started
-
Syntax

-
Details
Specification of Regressors Missing Values Poisson Regression Negative Binomial Regression Zero-Inflated Count Regression Overview Zero-Inflated Poisson Regression Zero-Inflated Negative Binomial Regression Variable Selection Panel Data Analysis Computational Resources Nonlinear Optimization Options Covariance Matrix Types Displayed Output OUTPUT OUT= Data Set OUTEST= Data Set ODS Table Names
-
Examples
- References
| Zero-Inflated Count Regression Overview |
The main motivation for zero-inflated count models is that real-life data frequently display overdispersion and excess zeros. Zero-inflated count models provide a way of modeling the excess zeros in addition to allowing for overdispersion. In particular, for each observation, there are two possible data generation processes. The result of a Bernoulli trial is used to determine which of the two processes is used. For observation 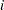 , Process 1 is chosen with probability
, Process 1 is chosen with probability 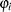 and Process 2 with probability
and Process 2 with probability 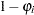 . Process 1 generates only zero counts. Process 2 generates counts from either a Poisson or a negative binomial model. In general,
. Process 1 generates only zero counts. Process 2 generates counts from either a Poisson or a negative binomial model. In general,
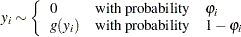 |
Therefore, the probability of 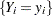 can be described as
can be described as
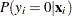 |
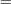 |
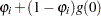 |
|||
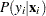 |
|
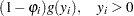 |
where 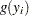 follows either the Poisson or the negative binomial distribution. You can specify the probability
follows either the Poisson or the negative binomial distribution. You can specify the probability 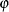 with the PROBZERO= option in the OUTPUT statement.
with the PROBZERO= option in the OUTPUT statement.
When the probability depends on the characteristics of observation , is written as a function of 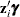 , where
, where 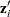 is the
is the 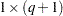 vector of zero-inflation covariates and
vector of zero-inflation covariates and 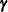 is the
is the 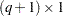 vector of zero-inflation coefficients to be estimated. (The zero-inflation intercept is
vector of zero-inflation coefficients to be estimated. (The zero-inflation intercept is 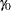 ; the coefficients for the
; the coefficients for the 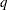 zero-inflation covariates are
zero-inflation covariates are 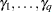 .) The function
.) The function 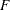 that relates the product (which is a scalar) to the probability is called the zero-inflation link function,
that relates the product (which is a scalar) to the probability is called the zero-inflation link function,
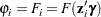 |
In the TCOUNTREG procedure, the zero-inflation covariates are indicated in the ZEROMODEL statement. Furthermore, the zero-inflation link function can be specified as either the logistic function,
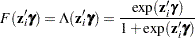 |
or the standard normal cumulative distribution function (also called the probit function),
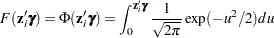 |
The zero-inflation link function is indicated in the LINK option in ZEROMODEL statement. The default ZI link function is the logistic function.
Note: This procedure is experimental.