The HPCDM Procedure(Experimental)

Descriptive Statistics
This section provides computational details for the descriptive statistics that are computed for each aggregate loss sample. You can also save these statistics in an OUTSUM= data set by specifying appropriate keywords in the OUTSUM statement.
This section gives specific details about the moment statistics. For more information about the methods of computing percentile statistics, see the description of the PCTLDEF= option in the UNIVARIATE procedure in the Base SAS Procedures Guide: Statistical Procedures.
Standard algorithms (Fisher 1973) are used to compute the moment statistics. The computational methods that the HPCDM procedure uses are consistent with those that other SAS procedures use for calculating descriptive statistics.
Mean
The sample mean is calculated as
![\[ \bar{y} = \frac{\sum ^ n_{i=1} y_ i}{n} \]](images/etshpug_hpcdm0081.png)
where n is the size of the generated aggregate loss sample and 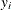 is the ith value of the aggregate loss.
is the ith value of the aggregate loss.
Standard Deviation
The standard deviation is calculated as
![\[ s = \sqrt { \frac{1}{d} \sum ^ n_{i=1} (y_ i-\bar{y})^2 } \]](images/etshpug_hpcdm0083.png)
where n is the size of the generated aggregate loss sample, is the ith value of the aggregate loss, 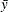 is the sample mean, and d is the divisor controlled by the VARDEF=
option in the PROC HPCDM statement:
is the sample mean, and d is the divisor controlled by the VARDEF=
option in the PROC HPCDM statement:
![\[ d = \left\{ \begin{array}{cl} n-1 & \mbox{if VARDEF=DF (default)} \\ n & \mbox{if VARDEF=N} \end{array} \right. \]](images/etshpug_hpcdm0085.png)
Skewness
The sample skewness, which measures the tendency of the deviations to be larger in one direction than in the other, is calculated as
![\[ \frac{1}{d_ s} \sum _{i=1}^ n \left( \frac{y_ i-\bar{y}}{s} \right)^3 \]](images/etshpug_hpcdm0086.png)
where n is the size of the generated aggregate loss sample, is the ith value of the aggregate loss, is the sample mean, s is the sample standard deviation, and 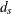 is the divisor controlled by the VARDEF=
option in the PROC HPCDM statement:
is the divisor controlled by the VARDEF=
option in the PROC HPCDM statement:
![\[ d_ s = \left\{ \begin{array}{cl} \frac{(n-1)(n-2)}{n} & \mbox{if VARDEF=DF (default)} \\ n & \mbox{if VARDEF=N} \end{array} \right. \]](images/etshpug_hpcdm0088.png)
If VARDEF=DF, then n must be greater than 2.
The sample skewness can be positive or negative; it measures the asymmetry of the data distribution and estimates the theoretical
skewness 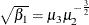 , where
, where 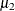 and
and 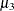 are the second and third central moments. Observations that are normally distributed should have a skewness near zero.
are the second and third central moments. Observations that are normally distributed should have a skewness near zero.
Kurtosis
The sample kurtosis, which measures the heaviness of tails, is calculated as in Table 4.2 depending on the value that you specify in the VARDEF= option.
Table 4.2: Formulas for Kurtosis
|
VARDEF Value |
Formula |
|---|---|
|
DF (default) |
|
|
N |
|
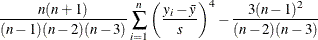
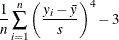
In these formulas, n is the size of the generated aggregate loss sample, is the ith value of the aggregate loss, is the sample mean, and s is the sample standard deviation. If VARDEF=DF, then n must be greater than 3.
The sample kurtosis measures the heaviness of the tails of the data distribution. It estimates the adjusted theoretical kurtosis
denoted as 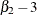 , where
, where 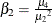 and
and 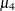 is the fourth central moment. Observations that are normally distributed should have a kurtosis near zero.
is the fourth central moment. Observations that are normally distributed should have a kurtosis near zero.