The HPCDM Procedure(Experimental)

Simulation Procedure
PROC HPCDM selects a simulation procedure based on whether you specify external counts or you request that PROC HPCDM simulate the counts, and whether the severity or frequency models contain regression effects. The following sections describe the process for the different scenarios.
Simulation with No Regressors and No External Counts
If you specify severity and frequency models that have no regression effects in them, and if you do not specify externally simulated counts in the EXTERNALCOUNTS statement, then PROC HPCDM uses the following simulation procedure.
The process is described for one severity distribution, dist. If you specify multiple severity distributions in the SEVERITYMODEL statement, then the process is repeated for each specified distribution.
The following steps are repeated M times to generate a compound distribution sample of size M, where M is the value that you specify in the NREPLICATES= option or the default value of that option:
-
Use the frequency model that you specify in the COUNTSTORE= option to draw a value N from the count distribution. N is the number of loss events that are expected to occur in the time period that is being simulated.
-
Draw N values,
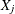 (
(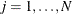 ), from the severity distribution dist with parameters that you specify in the SEVERITYEST= data set.
), from the severity distribution dist with parameters that you specify in the SEVERITYEST= data set.
-
Add the N severity values that are drawn in step 2 to compute one point S from the compound distribution as
![\[ S = \sum _{j=1}^{N} X_ j \]](images/etshpug_hpcdm0001.png)
Note that although it is more common to fit the frequency model with regressors, PROC COUNTREG enables you to fit a frequency model without regressors. If you do not specify any regressors in the MODEL statement of the COUNTREG procedure, then it fits a model that contains only an intercept.
Simulation with Regressors and No External Counts
If the severity or frequency models have regression effects and if you do not specify externally simulated counts in the EXTERNALCOUNTS statement, then you must specify a DATA= data set to provide values of the regression variables, which together represent a scenario for which you want to simulate the CDM. In this case, PROC HPCDM uses the following simulation procedure.
The process is described for one severity distribution. If you specify multiple severity distributions in the SEVERITYMODEL statement, then the process is repeated for each specified distribution.
Note that you are doing scenario analysis when regression effects are present. Let K denote the number of observations that form the scenario. This is the number of observations either in the current BY group
or in the entire DATA= data set if you do not specify the BY statement. If 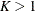 , then you are modeling the scenario for a group of entities. If K = 1, then you are modeling the scenario for one entity.
, then you are modeling the scenario for a group of entities. If K = 1, then you are modeling the scenario for one entity.
The following steps are repeated M times to generate a compound distribution sample of size M, where M is the value that you specify in the NREPLICATES= option or the default value of that option:
-
For each observation k (
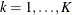 ), a count
), a count 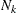 is drawn from the frequency model that you specify in the COUNTSTORE= option. The parameters of this model are determined
by the frequency regressors in observation k. represents the number of loss events that are expected to be generated by entity k in the time period that is being simulated.
is drawn from the frequency model that you specify in the COUNTSTORE= option. The parameters of this model are determined
by the frequency regressors in observation k. represents the number of loss events that are expected to be generated by entity k in the time period that is being simulated.
-
Counts from all observations are added to compute
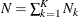 . N is the total number of loss events that are expected to occur in the time period that is being simulated.
. N is the total number of loss events that are expected to occur in the time period that is being simulated.
-
N number of random draws are made from the severity distribution, and they are added to generate one point of the compound distribution sample. Each of the N draws uses one of the K observations. If you specify a scale regression model for the severity distribution, then the scale parameter of the severity distribution is determined by the values of the severity regressors in the observation that is chosen for that draw.
If you specify the BY statement, then a separate sample of size M is created for each BY group in the DATA= data set.
Illustration of Aggregate Loss Simulation Process
As an illustration of the simulation process, consider a very simple example of analyzing the distribution of an aggregate
loss that is incurred by a set of policyholders of an automobile insurance company in a period of one year. It is postulated
that the frequency and severity distributions depend on three variables: Age, Gender (1: female, 2: male), and CarType (1: sedan, 2: sport utility vehicle). So these variables are used as regressors while you fit the count model and severity
scale regression model by using the COUNTREG and SEVERITY procedures, respectively. Now, consider that you want to use the
fitted frequency and severity models to estimate the distribution of the aggregate loss that is incurred by a set of five
policyholders together. Let the characteristics of the five policyholders be encoded in a SAS data set named Work.Scenario that has the following contents:
Obs age gender carType 1 30 2 1 2 25 1 2 3 45 2 2 4 33 1 1 5 50 1 1
The column Obs contains the observation number. It is shown only for the purpose of illustration. It need not be present in the data set.
The following PROC HPCDM step simulates the scenario in the Work.Scenario data set:
proc hpcdm data=scenario
severityest=<severity parameter estimates data set>
countstore=<count model store> nreplicates=<sample size>;
severitymodel <severity distribution name(s)>;
run;
The following process generates a sample from the aggregate loss distribution for the scenario in the Work.Scenario data set:
-
Use the values
Age=30,Gender=2, andCarType=1 in the first observation to draw a count from the count distribution. Let that count be 2. Repeat the process for the remaining four observations. Let the counts be as shown in theCountcolumn in the following table:Obs age gender carType count 1 30 2 1 2 2 25 1 2 1 3 45 2 2 2 4 33 1 1 3 5 50 1 1 0
Note that the
Countcolumn is shown for illustration only; it is not added as a variable to the DATA= data set. -
The simulated counts from all the observations are added to get a value of N = 8. This means that for this particular sample point, you expect a total of eight loss events in a year from these five policyholders.
-
For the first observation, the scale parameter of the severity distribution is computed by using the values
Age=30,Gender=2, andCarType=1. That value of the scale parameter is used together with estimates of the other parameters from the SEVERITYEST= data set to make two draws from the severity distribution. Each of the draws simulates the magnitude of the loss that is expected from the first policyholder. The process is repeated for the remaining four policyholders. The fifth policyholder does not generate any loss event for this particular sample point, so no severity draws are made by using the fifth observation. Let the severity draws, rounded to integers for convenience, be as shown in the_SEV_column in the following table:Obs age gender carType count _sev_ 1 30 2 1 2 350 2100 2 25 1 2 1 4500 3 45 2 2 2 700 4300 4 33 1 1 3 600 1500 950 5 50 1 1 0
Note that the
_SEV_column is shown for illustration only; it is not added as a variable to the DATA= data set.PROC HPCDM adds the severity values of the eight draws to compute an aggregate loss value of 15,000. After recording this amount in the sample, the process returns to step 1 to compute the next point in the aggregate loss sample. For example, in the second iteration, the count distribution of each policyholder might generate one loss event for a total of five loss events, and the five severity draws from the severity distributions that govern each of the policyholders might add up to 5,000. Then, the value of 5,000 is recorded as the second point in the aggregate loss sample. The process continues until M aggregate loss sample points are simulated, where the M is the value that you specify in the NREPLICATES= option.
Simulation with External Counts
If you specify externally simulated counts by using the EXTERNALCOUNTS statement, then each replication in the input data set represents the loss events generated by an entity. An entity can be an individual or organization for which you want to estimate the compound distribution. If an entity has any characteristics that are used as external factors (regressors) in developing the severity scale regression model, then you must specify the values of those factors in the DATA= data set. If you specify the ID= variable, then multiple observations for the same replication ID represent different entities in a group for which you are simulating the CDM.
PROC HPCDM uses the following simulation procedure in the presence of externally simulated counts.
The process is described for one severity distribution. If you specify multiple severity distributions in the SEVERITYMODEL statement, then the process is repeated for each specified distribution.
Let there be M distinct replications in the current BY group of the DATA= data set or in the entire DATA= data set if you do not specify the BY statement. A replication is identified by either the observation number or the value of the ID= variable that you specify in the EXTERNALCOUNTS statement.
For each of the M values of the replication identifier, the following steps are executed R times, where R is the value of the NREPLICATES= option or the default value of that option:
-
Compute the total number of losses, N. If there are K (
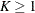 ) observations for the current value of the replication identifier, then
) observations for the current value of the replication identifier, then 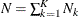 , where is the value of the COUNT= variable for observation k.
, where is the value of the COUNT= variable for observation k.
-
N number of random draws are made from the severity distribution, and they are added to generate one point of the compound distribution sample.
This process generates a compound distribution sample of size 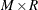 . If you specify the BY statement, then a separate sample of size is created for each BY group in the DATA= data set.
. If you specify the BY statement, then a separate sample of size is created for each BY group in the DATA= data set.
Illustration of the Simulation Process with External Counts
In order to illustrate the simulation process, consider the following simple example. In this example, your severity model
does not contain any regressors. An example that uses a severity scale regression model is illustrated later. Assume that
you have made 10 random draws from an external count model and recorded them in the ExtCount variable of a SAS data set named Work.Counts1 as follows:
Obs extCount 1 3 2 2 3 0 4 1 5 3 6 4 7 1 8 2 9 0 10 5
Because the data set does not contain an ID= variable, the observation number that is shown in the Obs column acts as the replicate identifier. The following PROC HPCDM step simulates an aggregate loss sample by using the Work.Counts1 data set:
proc hpcdm data=work.counts1 nreplicates=5
severityest=<severity parameter estimates data set>;
severitymodel <severity distribution name(s)>;
externalcounts count=extCount;
run;
The simulation process works as follows:
-
For the first replication, which is associated with the first observation, three severity values are drawn from the severity distribution by using the parameter estimates that you specify in the SEVERITYEST= data set. If the severity values are 150, 500, and 320, then their sum of 970 is recorded as the first point of the aggregate loss sample. Because the value of the NREPLICATES= option is 5, this process of drawing three severity values and adding them to form a point of the aggregate loss sample is repeated four more times to generate a total of five sample points that correspond to the first observation.
-
For the second replication, two severity values are drawn from the severity distribution. If the severity values are 450 and 100, then their sum of 550 is recorded as a point of the aggregate loss sample. This process of drawing two severity values and adding them to form a point of the aggregate loss sample is repeated four more times to generate a total of five sample points that correspond to the second observation.
-
The process continues until all the replications, which are observations in this case, are exhausted.
The process results in an aggregate loss sample of size 50, which is equal to the number of replications in the data set (10) multiplied by the value of the NREPLICATES= option (5).
Now, consider an example in which the severity models in the SEVERITYEST= data set are scale regression models. In this case,
the severity distribution that is used for drawing the severity value is decided by the values of regressors in the observation
that is being processed. Consider that you want to simulate the aggregate loss that is incurred by one policyholder and you
have recorded, in the ExtCount variable, the results of 10 random draws from an external count model. The DATA= data set has the following contents:
Obs age gender carType extCount 1 30 2 1 5 2 30 2 1 2 3 30 2 1 0 4 30 2 1 1 5 30 2 1 3 6 30 2 1 4 7 30 2 1 1 8 30 2 1 2 9 30 2 1 0 10 30 2 1 5
The simulation process in this case is the same as the process in the previous case of no regressors, except that the severity
distribution that is used for drawing the severity values has a scale parameter that is determined by the values of the regressors
Age, Gender, and CarType in the observation that is being processed. In this particular example, all observations have the same value for all regressors,
indicating that you are modeling a scenario in which the characteristics of the policyholder do not change during the time
for which you have simulated the number of events. You can also model a scenario in which the characteristics of the policyholder
change by recording those changes in the values of the appropriate regressors.
Extending this example further, consider that you want to analyze the distribution of the aggregate loss that is incurred
by a group of policyholders, as in the example in the section Illustration of Aggregate Loss Simulation Process. Let the Work.Counts2 data set record multiple replications of the number of losses that might be generated by each policyholder. The contents
of the Work.Counts2 data set are as follows:
Obs replicateId age gender carType extCount 1 1 30 2 1 2 2 1 25 1 2 1 3 1 45 2 2 3 4 1 33 1 1 5 5 1 50 1 1 1 6 2 30 2 1 3 7 2 25 1 2 2 8 1 45 2 2 0 9 2 33 1 1 4 10 2 50 1 1 1
The ReplicateId variable records the identifier for the replication. Each replication contains multiple observations, such that each observation
represents one of the policyholders that you are analyzing. For simplicity, only the first two replications are shown here.
The following PROC HPCDM step simulates an aggregate loss sample by using the Work.Counts2 data set:
proc hpcdm data=work.counts2 nreplicates=3
severityest=<severity parameter estimates data set>;
severitymodel <severity distribution name(s)>;
distby replicateId;
externalcounts count=extCount id=replicateId;
output out=aggloss samplevar=totalLoss;
run;
When you specify an ID= variable in the EXTERNALCOUNTS statement, you must specify the same ID= variable in the DISTBY statement in order for the procedure to work correctly in a distributed computing environment. Further, the DATA= set must be sorted in ascending order of the ID= variable values.
The simulation process works as follows:
-
First, the five observations of the first replication (
ReplicateId=1 are analyzed. For the first observation (Obs=1), the scale parameter of the severity distribution is computed by using the valuesAge=30,Gender=2, andCarType=1. That value of the scale parameter is used together with estimates of the other parameters from the SEVERITYEST= data set to make two draws from the severity distribution. Next, the regressor values of the second observation are used to compute the scale parameter of the severity distribution, which is used to make one severity draw. The process continues such that the regressor values in the third, fourth, and fifth observations are used to decide the severity distribution to make three, five, and one draws from, respectively. Let the severity values that are drawn from the observations of this replication be as shown in the_SEV_column in the following table, where the_SEV_column is shown for illustration only; it is not added as a variable to the DATA= data set:Obs replicateId age gender carType extCount _sev_ 1 1 30 2 1 2 700 500 2 1 25 1 2 1 5000 3 1 45 2 2 3 900 1400 300 4 1 33 1 1 5 350 2000 150 800 600 5 1 50 1 1 1 250
The values of all 12 severity draws are added to compute and record the value of 12,950 as the first point of the aggregate loss sample. Because you specify NREPLICATES=3 in the PROC HPCDM step, this process of making 12 severity draws from the respective observations is repeated two more times to generate a total of three sample points for the first replication.
-
The five observations of the second replication (
ReplicateId=2) are analyzed next to draw three, two, four, and one severity values from the severity distributions, with scale parameters that are decided by the regressor values in the sixth, seventh, ninth, and tenth observations, respectively. The 10 severity values are added to form a point of the aggregate loss sample. This process of making 10 severity draws from the respective observations is repeated two more times to generate a total of three sample points for the second replication.
If your Work.Counts2 data set contains 10,000 distinct values of ReplicateId, then 30,000 observations are written to the Work.AggLoss data set that you specify in the OUTPUT statement of the preceding PROC HPCDM step. Because you specify SAMPLEVAR=TotalLoss in the OUTPUT statement, the aggregate loss sample is available in the TotalLoss column of the Work.AggLoss data set.