The SURVEYFREQ Procedure

Risks and Risk Difference
The RISK
option provides estimates of risks (binomial proportions) and risk differences for 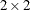 tables, together with their standard errors and confidence limits. Risk statistics include the row 1 risk, row 2 risk, overall
risk, and risk difference. If you specify the RISK option, PROC SURVEYFREQ provides both column 1 and column 2 risks. You
can request only column 1 (or only column 2) risks by specifying the RISK1
(or RISK2
) option.
tables, together with their standard errors and confidence limits. Risk statistics include the row 1 risk, row 2 risk, overall
risk, and risk difference. If you specify the RISK option, PROC SURVEYFREQ provides both column 1 and column 2 risks. You
can request only column 1 (or only column 2) risks by specifying the RISK1
(or RISK2
) option.
The column 1 risk for row 1 is the row 1 proportion for table cell (1,1). The column 1 risk estimate is computed as the ratio of the estimated total for table cell (1,1) to the estimated total for row 1,
![\[ \widehat{P}_{11}^{~ (1)} = \widehat{N}_{11} ~ / ~ \widehat{N}_{1 \cdot } \]](images/statug_surveyfreq0129.png)
where the total estimates are computed as described in the section Totals. The column 1 risk for row 2 is the row 2 proportion for table cell (2,1), which is estimated as
![\[ \widehat{P}_{21}^{~ (2)} = \widehat{N}_{21} ~ / ~ \widehat{N}_{2 \cdot } \]](images/statug_surveyfreq0130.png)
The overall column 1 risk is the overall proportion in column 1, and its estimate is computed as
![\[ \widehat{P}_{\cdot 1} = \widehat{N}_{\cdot 1} ~ / ~ \widehat{N} \]](images/statug_surveyfreq0131.png)
The column 2 risk estimates are computed similarly.
The row 1 and row 2 risks are the same as the row proportions for a table, and their variances are computed as described in the section Row and Column Proportions. The overall risk is the overall proportion in the column, and its variance computation is described in the section Proportions. Confidence limits for the column 1 risk for row 1 are computed as
![\[ \widehat{P}_{11}^{~ (1)} \pm \left( t_{\mi{df}, \alpha /2} \times \mr{StdErr}(\widehat{P}_{11}^{~ (1)}) \right) \]](images/statug_surveyfreq0132.png)
where 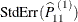 is the standard error of the risk estimate and
is the standard error of the risk estimate and 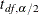 is the
is the 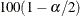 th percentile of the t distribution with df degrees of freedom. (For more information, see the section Degrees of Freedom.) The value of the confidence coefficient
th percentile of the t distribution with df degrees of freedom. (For more information, see the section Degrees of Freedom.) The value of the confidence coefficient  is determined by the ALPHA=
option; by default, ALPHA=0.05, which produces 95% confidence limits. Confidence limits for the other risks are computed
similarly.
is determined by the ALPHA=
option; by default, ALPHA=0.05, which produces 95% confidence limits. Confidence limits for the other risks are computed
similarly.
The risk difference is defined as the row 1 risk minus the row 2 risk. The estimate of the column 1 risk difference 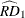 is computed as
is computed as
![\begin{eqnarray*} \widehat{\mathit{RD}}_1 & = & \widehat{P}_{11}^{~ (1)} - \widehat{P}_{21}^{~ (2)} \\[0.1in]& = & \left( \widehat{N}_{11} ~ / ~ \widehat{N}_{1 \cdot } \right) ~ - ~ \left( \widehat{N}_{21} ~ / ~ \widehat{N}_{2 \cdot } \right) \end{eqnarray*}](images/statug_surveyfreq0135.png)
The column 2 risk difference is computed similarly.
PROC SURVEYFREQ estimates the variance of the risk difference by using the variance estimation method that you request. If you request BRR variance estimation (VARMETHOD=BRR ), the procedure estimates the variance as described in the section Balanced Repeated Replication (BRR). If you request jackknife variance estimation (VARMETHOD=JACKKNIFE ), the procedure estimates the variance as described in the section The Jackknife Method.
If you do not specify the VARMETHOD=
option or a REPWEIGHTS
statement, the default variance estimation method is Taylor series (VARMETHOD=TAYLOR
). By using Taylor series linearization, the variance estimate for the column 1 risk difference 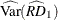 can be expressed as
can be expressed as
![\[ \widehat{\mr{Var}}(\widehat{\mathit{RD}}_1) = \widehat{\mb{D}} ~ \widehat{\mb{V}}(\widehat{\mb{X}}) ~ \widehat{\mb{D}}’ \]](images/statug_surveyfreq0137.png)
where 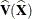 is the covariance matrix of
is the covariance matrix of 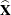 ,
,
![\[ \widehat{\mb{X}} = \left( ~ \widehat{N}_{11}, ~ ~ \widehat{N}_{1 \cdot }, ~ ~ \widehat{N}_{21}, ~ ~ \widehat{N}_{2 \cdot } ~ \right) \]](images/statug_surveyfreq0140.png)
and 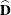 is an array that contains the partial derivatives of the risk difference with respect to the elements of ,
is an array that contains the partial derivatives of the risk difference with respect to the elements of ,
![\[ \widehat{\mb{D}} = \left( ~ 1/\widehat{N}_{1 \cdot }, ~ ~ ~ -\widehat{N}_{11} / \widehat{N}_{1 \cdot }^{~ 2}, ~ ~ ~ -1/\widehat{N}_{2 \cdot }, ~ ~ ~ -\widehat{N}_{21} / \widehat{N}_{2 \cdot }^{~ 2} ~ \right) \]](images/statug_surveyfreq0142.png)
For more information, see Wolter (1985, pp. 239–242). The variance estimate for the column 2 risk difference is computed similarly.
The standard error of the column 1 risk difference is
![\[ \mr{StdErr}(\widehat{\mathit{RD}}_1) = \sqrt { \widehat{\mr{Var}}(\widehat{\mathit{RD}}_1) } \]](images/statug_surveyfreq0143.png)
Confidence limits for the column 1 risk difference are computed as
![\[ \widehat{\mathit{RD}}_1 \pm \left( t_{\mi{df}, \alpha /2} \times \mr{StdErr}(\widehat{\mathit{RD}}_1) \right) \]](images/statug_surveyfreq0144.png)
where is the th percentile of the t distribution with df degrees of freedom. (For more information, see the section Degrees of Freedom.) The value of the confidence coefficient is determined by the ALPHA=
option; by default, ALPHA=0.05, which produces 95% confidence limits. Confidence limits for the column 2 risk difference
are computed in the same way.