The SURVEYFREQ Procedure

Odds Ratio and Relative Risks
The OR
option provides estimates of the odds ratio, the column 1 relative risk, and the column 2 relative risk for 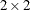 tables, together with their confidence limits.
tables, together with their confidence limits.
Odds Ratio
For a table, the odds of a positive (column 1) response in row 1 is  . Similarly, the odds of a positive response in row 2 is
. Similarly, the odds of a positive response in row 2 is  . The odds ratio is formed as the ratio of the row 1 odds to the row 2 odds. The estimate of the odds ratio is computed as
. The odds ratio is formed as the ratio of the row 1 odds to the row 2 odds. The estimate of the odds ratio is computed as
![\[ \widehat{\mathit{OR}} = \frac{\widehat{N}_{11} ~ / ~ \widehat{N}_{12}}{\widehat{N}_{21} ~ / ~ \widehat{N}_{22}} = \frac{\widehat{N}_{11} ~ \widehat{N}_{22}}{\widehat{N}_{12} ~ \widehat{N}_{21}} \]](images/statug_surveyfreq0147.png)
The value of the odds ratio can be any nonnegative number. When the row and column variables are independent, the true value of the odds ratio is 1. An odds ratio greater than 1 indicates that the odds of a positive response are higher in row 1 than in row 2. An odds ratio less than 1 indicates that the odds of positive response are higher in row 2. The strength of association increases with the deviation from 1. For more information, see Stokes, Davis, and Koch (2000) and Agresti (2007).
PROC SURVEYFREQ constructs confidence limits for the odds ratio by using the log transform. The 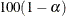 % confidence limits for the odds ratio are computed as
% confidence limits for the odds ratio are computed as
![\[ \left( ~ \widehat{\mathit{OR}} \times \exp ( -t_{\mi{df}, \alpha /2} ~ \sqrt {v} ), ~ \widehat{\mathit{OR}} \times \exp ( t_{\mi{df}, \alpha /2} ~ \sqrt {v} ) ~ \right) \]](images/statug_surveyfreq0148.png)
where
![\[ v = \widehat{\mr{Var}} (\ln \widehat{\mathit{OR}}) = \widehat{\mr{Var}} (\widehat{\mathit{OR}}) ~ / ~ \widehat{\mathit{OR}}^{~ 2} \]](images/statug_surveyfreq0149.png)
is the estimate of the variance of the log odds ratio and 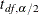 is the
is the 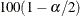 th percentile of the t distribution with df degrees of freedom. (For more information, see the section Degrees of Freedom.) The value of the confidence coefficient
th percentile of the t distribution with df degrees of freedom. (For more information, see the section Degrees of Freedom.) The value of the confidence coefficient  is determined by the ALPHA=
option; by default, ALPHA=0.05, which produces 95% confidence limits.
is determined by the ALPHA=
option; by default, ALPHA=0.05, which produces 95% confidence limits.
If you request BRR variance estimation (VARMETHOD=BRR ), PROC SURVEYFREQ estimates the variance of the odds ratio as described in the section Balanced Repeated Replication (BRR). If you request jackknife variance estimation (VARMETHOD=JACKKNIFE ), the procedure estimates the variance as described in the section The Jackknife Method.
If you do not specify the VARMETHOD= option or a REPWEIGHTS statement, the default variance estimation method is Taylor series (VARMETHOD=TAYLOR ). By using Taylor series linearization, the variance estimate for the odds ratio can be expressed as
![\[ \widehat{\mr{Var}}(\widehat{\mathit{OR}}) = \widehat{\mb{D}} ~ \widehat{\mb{V}}(\widehat{\mb{N}}) ~ \widehat{\mb{D}}’ \]](images/statug_surveyfreq0150.png)
where 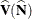 is the covariance matrix of the estimates of the cell totals
is the covariance matrix of the estimates of the cell totals 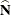 ,
,
![\[ \widehat{\mb{N}} = \left( ~ \widehat{N}_{11}, ~ ~ \widehat{N}_{12}, ~ ~ \widehat{N}_{21}, ~ ~ \widehat{N}_{22} ~ \right) \]](images/statug_surveyfreq0152.png)
and 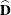 is an array that contains the partial derivatives of the odds ratio with respect to the elements of . The section Covariances of Frequency Estimates describes the computation of . The array is computed as
is an array that contains the partial derivatives of the odds ratio with respect to the elements of . The section Covariances of Frequency Estimates describes the computation of . The array is computed as
![\[ \widehat{\mb{D}} = \left( ~ \widehat{N}_{22} / ( \widehat{N}_{12} \widehat{N}_{21} ), ~ ~ ~ ~ - \widehat{N}_{11} \widehat{N}_{22} / ( \widehat{N}_{21} \widehat{N}_{12}^{~ 2} ), ~ ~ ~ - \widehat{N}_{11} \widehat{N}_{22} / ( \widehat{N}_{12} \widehat{N}_{21}^{~ 2} ), ~ ~ ~ \widehat{N}_{11} / ( \widehat{N}_{12} \widehat{N}_{21} ) ~ \right) \]](images/statug_surveyfreq0153.png)
For more information, see Wolter (1985, pp. 239–242).
Relative Risks
For a table, the column 1 relative risk is the ratio of the column 1 risks for row 1 to row 2. As described in the section Risks and Risk Difference, the column 1 risk for row 1 is the proportion of row 1 observations classified in column 1, and the column 1 risk for row
2 is the proportion of row 2 observations classified in column 1. The estimate of the column 1 relative risk is computed as
![\[ \widehat{\mathit{RR}}_1 = \frac{\widehat{N}_{11} ~ / ~ \widehat{N}_{1 \cdot }}{\widehat{N}_{21} ~ / ~ \widehat{N}_{2 \cdot }} \]](images/statug_surveyfreq0154.png)
Similarly, the estimate of the column 2 relative risk is computed as
![\[ \widehat{\mathit{RR}}_2 = \frac{\widehat{N}_{12} ~ / ~ \widehat{N}_{1 \cdot }}{\widehat{N}_{22} ~ / ~ \widehat{N}_{2 \cdot }} \]](images/statug_surveyfreq0155.png)
A relative risk greater than 1 indicates that the probability of positive response is greater in row 1 than in row 2. Similarly, a relative risk less than 1 indicates that the probability of positive response is less in row 1 than in row 2. The strength of association increases with the deviation from 1. For more information, see Stokes, Davis, and Koch (2000) and Agresti (2007).
PROC SURVEYFREQ constructs confidence limits for the relative risk by using the log transform, which is similar to the odds
ratio computations described previously. The % confidence limits for the column 1 relative risk are computed as
![\[ \left( ~ \widehat{\mathit{RR}}_1 \times \exp ( -t_{\mi{df}, \alpha /2} ~ \sqrt {v} ), ~ \widehat{\mathit{RR}}_1 \times \exp ( t_{\mi{df}, \alpha /2} ~ \sqrt {v} ) ~ \right) \]](images/statug_surveyfreq0156.png)
where
![\[ v = \widehat{\mr{Var}} (\ln \widehat{\mathit{RR}}_1) = \widehat{\mr{Var}} (\widehat{\mathit{RR}}_1) ~ / ~ \widehat{\mathit{RR}}_1^{~ 2} \]](images/statug_surveyfreq0157.png)
is the estimate of the variance of the log column 1 relative risk and is the th percentile of the t distribution with df degrees of freedom. (For more information, see the section Degrees of Freedom.) The value of the confidence coefficient is determined by the ALPHA=
option; by default, ALPHA=0.05, which produces 95% confidence limits.
If you request BRR variance estimation (VARMETHOD=BRR ), PROC SURVEYFREQ estimates the variance of the column 1 relative risk as described in the section Balanced Repeated Replication (BRR). If you request jackknife variance estimation (VARMETHOD=JACKKNIFE ), the procedure estimates the variance as described in the section The Jackknife Method.
If you do not specify the VARMETHOD= option or a REPWEIGHTS statement, the default variance estimation method is Taylor series (VARMETHOD=TAYLOR ). By using Taylor series linearization, the variance estimate for the column 1 relative risk can be expressed as
![\[ \widehat{\mr{Var}}(\widehat{\mathit{RR}}_1) = \widehat{\mb{D}} ~ \widehat{\mb{V}}(\widehat{\mb{X}}) ~ \widehat{\mb{D}}’ \]](images/statug_surveyfreq0158.png)
where 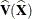 is the covariance matrix of
is the covariance matrix of 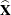 ,
,
![\[ \widehat{\mb{X}} = \left( ~ \widehat{N}_{11}, ~ ~ \widehat{N}_{1 \cdot }, ~ ~ \widehat{N}_{21}, ~ ~ \widehat{N}_{2 \cdot } ~ \right) \]](images/statug_surveyfreq0140.png)
and is an array that contains the partial derivatives of the column 1 relative risk with respect to the elements of ,
![\[ \widehat{\mb{D}} = \left( ~ \widehat{N}_{2 \cdot } / ( \widehat{N}_{21} \widehat{N}_{1 \cdot } ), ~ ~ ~ ~ - \widehat{N}_{11} \widehat{N}_{2 \cdot } / ( \widehat{N}_{21} \widehat{N}_{1 \cdot }^{~ 2} ), ~ ~ ~ - \widehat{N}_{11} \widehat{N}_{2 \cdot } / ( \widehat{N}_{1 \cdot } \widehat{N}_{21}^{~ 2} ), ~ ~ ~ \widehat{N}_{11} / ( \widehat{N}_{21} \widehat{N}_{1 \cdot } ) ~ \right) \]](images/statug_surveyfreq0159.png)
For more information, see Wolter (1985, pp. 239–242).
Confidence limits for the column 2 relative risk are computed similarly.