The ICPHREG Procedure

BASELINE Statement
-
BASELINE <OUT=SAS-data-set> <COVARIATES=SAS-data-set> <TIMELIST=list> <keyword=name …keyword=name> </ options>;
The BASELINE statement creates a SAS data set (named by the OUT= option) that contains the predicted values at specified times that partition the time axis for every set of covariates in the COVARIATES= data set. If the COVARIATES= data set is not specified, PROC ICPHREG uses a reference set of covariates that consists of the reference levels for the CLASS variables and the average values for the continuous variables.
Table 63.3 summarizes the options that you can specify in the BASELINE statement.
Table 63.3: BASELINE Statement Options
|
Option |
Description |
|---|---|
|
Data Set and Time List Options |
|
|
Specifies the output BASELINE data set |
|
|
Specifies the SAS data set that contains the explanatory variables |
|
|
Specifies a list of time points for computing the predicted values |
|
|
Keyword Options for Variables |
|
|
Specifies the cumulative hazard function estimate |
|
|
Specifies the hazard function estimate |
|
|
Specifies the log of the negative log of the survival function |
|
|
Specifies the log of the survival function |
|
|
Specifies the lower pointwise confidence limit for the cumulative hazard function |
|
|
Specifies the lower pointwise confidence limit for the survival function |
|
|
Specifies the estimated standard error of the cumulative hazard function |
|
|
Specifies the standard error of the survival function |
|
|
Specifies the estimated standard error of the linear predictor estimator |
|
|
Specifies the survival function estimate |
|
|
Specifies the upper pointwise confidence limit for the cumulative hazard function |
|
|
Specifies the upper pointwise confidence limit for the survival function |
|
|
Specifies the estimate of the linear predictor |
|
|
Other Options |
|
|
Specifies the level of the confidence interval for the survival function |
|
|
Specifies the transformation that is used to compute confidence limits for the survival function |
|
|
Names a variable whose values identify or group predicted survival or cumulative hazard functions in plots |
|
|
Names the variable in the COVARIATES= data set for identifying the predicted survival or cumulative hazard functions in plots |
|
You can specify the following options in the BASELINE statement.
- OUT=SAS-data-set
-
names the output data set. If you omit the OUT= option, the data set is created and given a default name by using the
DATAnconvention. For more information, see the section OUT= Output Data Set in the BASELINE Statement. - COVARIATES=SAS-data-set
-
names the SAS data set that contains the sets of explanatory variable values for which the functions of interest are estimated. All variables in the COVARIATES= data set are copied to the OUT= data set. Thus, any variable in the COVARIATES= data set can be used to identify the covariate sets in the OUT= data set.
- TIMELIST=list
-
specifies a list of time points at which the predicted values are computed. The following specifications are equivalent:
timelist=5,20 to 50 by 10 timelist=5 20 30 40 50
If you do not specify this option, predicted values are computed at all the times that partition the time axis.
- keyword=name
-
specifies the statistics to be included in the OUT= data set and assigns names to the variables that contain these statistics. Specify a keyword for each desired statistic, an equal sign, and the name of the variable for the statistic. You can specify the following keywords:
- CUMHAZ=name
-
specifies the cumulative hazard function estimate. Specifying CUMHAZ=_ALL_ is equivalent to specifying CUMHAZ=CumHaz, STDCUMHAZ=StdErrCumHaz, LOWERCUMHAZ=LowerCumHaz, and UPPERCUMHAZ=UpperCumHaz.
- HAZARD=name
-
specifies the hazard function estimate.
-
LOGLOGS=name
CLOGLOGS=name -
specifies the log of the negative log of the estimated survival function.
- LOGSURV=name
-
specifies the log of the estimated survival function.
-
LOWER=name
L=name
LOWERSDF=name -
specifies the lower pointwise confidence limit for the survival function. The confidence level is determined by the ALPHA= option.
- LOWERCUMHAZ=name
-
specifies the lower pointwise confidence limit for the cumulative hazard function. The confidence level is determined by the ALPHA= option.
-
STDERR=name
STDSDF=name -
specifies the standard error of the survival function estimator.
- STDCUMHAZ=name
-
specifies the estimated standard error of the cumulative hazard function estimator.
- STDXBETA=name
-
specifies the estimated standard error of the linear predictor estimator.
-
SURVIVAL=name
SDF=name -
specifies the estimated survival function (
![$S(t)=[S_0(t)]^{\exp (\mb{z}'\bbeta )}$](images/statug_icphreg0030.png) ). Specifying SURVIVAL=_ALL_ is equivalent to specifying SURVIVAL=Survival, STDERR=StdErrSurvival, LOWER=LowerSurvival, and
UPPER=UpperSurvival.
). Specifying SURVIVAL=_ALL_ is equivalent to specifying SURVIVAL=Survival, STDERR=StdErrSurvival, LOWER=LowerSurvival, and
UPPER=UpperSurvival.
-
UPPER=name
U=name
UPPERSDF=name -
specifies the upper pointwise confidence limit for the survival function. The confidence level is determined by the ALPHA= option.
- UPPERCUMHAZ=name
-
specifies the upper pointwise confidence limit for the cumulative hazard function. The confidence level is determined by the ALPHA= option.
- XBETA=name
-
specifies the estimate of the linear predictor
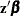 . If there is an offset, it is added to the predictor.
. If there is an offset, it is added to the predictor.
You can specify the following options after a slash (/).
- ALPHA=value
-
specifies the level of the confidence interval for the survival function. The value must be between 0 and 1. The default is the value of the ALPHA= option in the PROC ICPHREG statement, or 0.05 if that option is not specified.
-
CLTYPE=method
CITYPE=method
TYPE=method
CLTRANSFORM=method
TRANSFORM=method -
specifies the transformation that is used to compute the confidence limits for
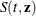 , which is the survival function for a subject that has a fixed covariate vector
, which is the survival function for a subject that has a fixed covariate vector  at event time t. You can specify the following methods:
at event time t. You can specify the following methods:
- LOG
-
uses normal theory approximation to compute the confidence limits for
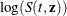 . The confidence limits for are obtained by back-transforming the confidence limits for .
. The confidence limits for are obtained by back-transforming the confidence limits for .
- LOGLOG
-
uses normal theory approximation to compute the confidence limits for the
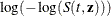 . The confidence limits for are obtained by back-transforming the confidence limits for .
. The confidence limits for are obtained by back-transforming the confidence limits for .
-
NORMAL
IDENTITY
LINEAR
PLAIN
DIRECT -
uses normal theory approximation to compute the confidence limits for
.
By default, CLTYPE=LOG.
- GROUP=variable
-
names a variable whose values identify or group the predicted curves. The variable must be a numeric variable in the COVARIATES= data set. Survival curves for observations that have the same value of the variable are overlaid in the same plot.
-
ROWID=variable
ID=variable
ROW=variable -
names a variable in the COVARIATES= data set for identifying plotted survival functions and cumulative hazard functions. This option has no effect if the PLOTS= option in the PROC ICPHREG statement is not specified. Values of this variable are used to label the plotted functions for the corresponding rows in the COVARIATES= data set. You can specify ROWID=_OBS_ to use the observation numbers in the COVARIATES= data set for identification.