The GENMOD Procedure
-
Overview

-
Getting Started
-
SyntaxPROC GENMOD StatementASSESS StatementBAYES StatementBY StatementCLASS StatementCODE StatementCONTRAST StatementDEVIANCE StatementEFFECTPLOT StatementESTIMATE StatementEXACT StatementEXACTOPTIONS StatementFREQ StatementFWDLINK StatementINVLINK StatementLSMEANS StatementLSMESTIMATE StatementMODEL StatementOUTPUT StatementProgramming StatementsREPEATED StatementSLICE StatementSTORE StatementSTRATA StatementVARIANCE StatementWEIGHT StatementZEROMODEL Statement
-
DetailsGeneralized Linear Models TheorySpecification of EffectsParameterization Used in PROC GENMODType 1 AnalysisType 3 AnalysisConfidence Intervals for ParametersF StatisticsLagrange Multiplier StatisticsPredicted Values of the MeanResidualsMultinomial ModelsZero-Inflated ModelsTweedie Distribution For Generalized Linear ModelsGeneralized Estimating EquationsAssessment of Models Based on Aggregates of ResidualsCase Deletion Diagnostic StatisticsBayesian AnalysisExact Logistic and Exact Poisson RegressionResponse Level OrderingMissing ValuesDisplayed Output for Classical AnalysisDisplayed Output for Bayesian AnalysisDisplayed Output for Exact AnalysisODS Table NamesODS Graphics
-
ExamplesLogistic RegressionNormal Regression, Log Link Gamma Distribution Applied to Life DataOrdinal Model for Multinomial DataGEE for Binary Data with Logit Link FunctionLog Odds Ratios and the ALR AlgorithmLog-Linear Model for Count DataModel Assessment of Multiple Regression Using Aggregates of ResidualsAssessment of a Marginal Model for Dependent DataBayesian Analysis of a Poisson Regression ModelExact Poisson RegressionTweedie Regression
- References
Assessment of Models Based on Aggregates of Residuals
Lin, Wei, and Ying (2002) present graphical and numerical methods for model assessment based on the cumulative sums of residuals over certain coordinates (such as covariates or linear predictors) or some related aggregates of residuals. The distributions of these stochastic processes under the assumed model can be approximated by the distributions of certain zero-mean Gaussian processes whose realizations can be generated by simulation. Each observed residual pattern can then be compared, both graphically and numerically, with a number of realizations from the null distribution. Such comparisons enable you to assess objectively whether the observed residual pattern reflects anything beyond random fluctuation. These procedures are useful in determining appropriate functional forms of covariates and link function. You use the ASSESS|ASSESSMENT statement to perform this kind of model-checking with cumulative sums of residuals, moving sums of residuals, or LOESS smoothed residuals. See Example 44.8 and Example 44.9 for examples of model assessment.
Let the model for the mean be
![\[ g(\mu _ i) = \mb{x}_ i^\prime \bbeta \]](images/statug_genmod0012.png)
where 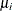 is the mean of the response
is the mean of the response 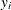 and
and 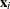 is the vector of covariates for the ith observation. Denote the raw residual resulting from fitting the model as
is the vector of covariates for the ith observation. Denote the raw residual resulting from fitting the model as
![\[ e_ i = y_ i - \hat{\mu }_ i \]](images/statug_genmod0460.png)
and let 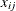 be the value of the jth covariate in the model for observation i. Then to check the functional form of the jth covariate, consider the cumulative sum of residuals with respect to ,
be the value of the jth covariate in the model for observation i. Then to check the functional form of the jth covariate, consider the cumulative sum of residuals with respect to ,
![\[ W_ j(x) = \frac{1}{\sqrt {n}}\sum _{i=1}^ n I(x_{ij} \le x) e_ i \]](images/statug_genmod0462.png)
where 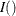 is the indicator function. For any x,
is the indicator function. For any x, 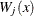 is the sum of the residuals with values of
is the sum of the residuals with values of 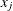 less than or equal to x.
less than or equal to x.
Denote the score, or gradient vector, by
![\[ U(\bbeta ) = \sum _{i=1}^ n h(\mb{x}^\prime \bbeta )\mb{x}_ i (y_ i - \nu (\mb{x}^\prime \bbeta )) \]](images/statug_genmod0466.png)
where 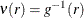 , and
, and
![\[ h(r) = \frac{1}{g\prime (\nu (r))V(\nu (r))} \]](images/statug_genmod0468.png)
Let 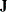 be the Fisher information matrix
be the Fisher information matrix
![\[ \bJ (\bbeta ) = -\frac{\partial U(\bbeta )}{\partial \bbeta ^\prime } \]](images/statug_genmod0469.png)
Define
![\[ \hat{W}_ j(x) = \frac{1}{\sqrt {n}}\sum _{i=1}^ n [I(x_{ij} \le x) + \bm {\eta }^\prime (x;\hat{\bbeta })\bJ ^{-1}(\hat{\bbeta })\mb{x}_ i h(\mb{x}^\prime \hat{\bbeta })]e_ i Z_ i \]](images/statug_genmod0470.png)
where
![\[ \bm {\eta }(x;\bbeta ) = -\sum _{i=1}^ n I(x_{ij} \le x) \frac{\partial \nu (\mb{x}_ i^\prime \bbeta )}{\partial \bbeta } \]](images/statug_genmod0471.png)
and 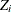 are independent
are independent 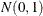 random variables. Then the conditional distribution of
random variables. Then the conditional distribution of 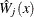 , given
, given 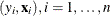 , under the null hypothesis
, under the null hypothesis 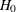 that the model for the mean is correct, is the same asymptotically as
that the model for the mean is correct, is the same asymptotically as 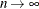 as the unconditional distribution of (Lin, Wei, and Ying 2002).
as the unconditional distribution of (Lin, Wei, and Ying 2002).
You can approximate realizations from the null hypothesis distribution of by repeatedly generating normal samples 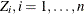 , while holding , at their observed values and computing for each sample.
, while holding , at their observed values and computing for each sample.
You can assess the functional form of covariate j by plotting a few realizations of on the same plot as the observed and visually comparing to see how typical the observed is of the null distribution samples.
You can supplement the graphical inspection method with a Kolmogorov-type supremum test. Let 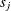 be the observed value of
be the observed value of 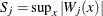 . The p-value
. The p-value ![$\mr{Pr}[S_ j \ge s_ j]$](images/statug_genmod0481.png) is approximated by
is approximated by ![$\mr{Pr}[\hat{S}_ j \ge s_ j]$](images/statug_genmod0482.png) , where
, where 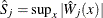 . is estimated by generating realizations of
. is estimated by generating realizations of 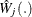 (1,000 is the default number of realizations).
(1,000 is the default number of realizations).
You can check the link function instead of the jth covariate by using values of the linear predictor 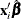 in place of values of the jth covariate . The graphical and numerical methods described previously are then sensitive to inadequacies in the link function.
in place of values of the jth covariate . The graphical and numerical methods described previously are then sensitive to inadequacies in the link function.
An alternative aggregate of residuals is the moving sum statistic
![\[ W_ j(x,b) = \frac{1}{\sqrt {n}}\sum _{i=1}^ n I(x-b\le x_{ij}\le x)e_ i \]](images/statug_genmod0485.png)
If you specify the keyword WINDOW(b), then the moving sum statistic with window size b is used instead of the cumulative sum of residuals, with 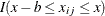 replacing
replacing 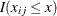 in the earlier equation.
in the earlier equation.
If you specify the keyword LOESS(f), loess smoothed residuals are used in the preceding formulas, where f is the fraction of the data to be used at a given point. If f is not specified, 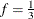 is used. For data
is used. For data 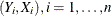 , define r as the nearest integer to
, define r as the nearest integer to 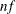 and h as the rth smallest among
and h as the rth smallest among 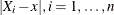 . Let
. Let
![\[ K_ i(x) = K\left(\frac{X_ i-x}{h}\right) \]](images/statug_genmod0492.png)
where
![\[ K(t) = \frac{70}{81}(1-|t|^3)^3I(-1\le t \le 1) \]](images/statug_genmod0493.png)
Define
![\[ w_ i(x) = K_ i(x)[S_2(x)-(X_ i-x)S_1(x)] \]](images/statug_genmod0494.png)
where
![\[ S_1(x) = \sum _{i=1}^ n K_ i(x)(X_ i-x) \]](images/statug_genmod0495.png)
![\[ S_2(x) = \sum _{i=1}^ n K_ i(x)(X_ i-x)^2 \]](images/statug_genmod0496.png)
Then the loess estimate of Y at x is defined by
![\[ \hat{Y}(x) = \sum _{i=1}^ n\frac{w_ i(x)}{\sum _{i=1}^ nw_ i(x)}Y_ i \]](images/statug_genmod0497.png)
Loess smoothed residuals for checking the functional form of the jth covariate are defined by replacing 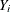 with
with 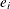 and
and 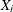 with . To implement the graphical and numerical assessment methods,
with . To implement the graphical and numerical assessment methods, 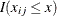 is replaced with
is replaced with 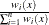 in the formulas for and .
in the formulas for and .
You can perform the model checking described earlier for marginal models for dependent responses fit by generalized estimating
equations (GEEs). Let 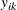 denote the kth measurement on the ith cluster,
denote the kth measurement on the ith cluster, 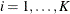 ,
, 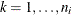 , and let
, and let 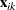 denote the corresponding vector of covariates. The marginal mean of the response
denote the corresponding vector of covariates. The marginal mean of the response 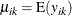 is assumed to depend on the covariate vector by
is assumed to depend on the covariate vector by
![\[ g(\mu _{ik})=\mb{x}^\prime _{ik}\bbeta \]](images/statug_genmod0506.png)
where g is the link function.
Define the vector of residuals for the ith cluster as
![\[ \mb{e}_ i = (e_{i1},\ldots ,e_{in_ i})^\prime = (y_{i1}-\hat{\mu }_{i1},\ldots ,y_{in_ i}-\hat{\mu }_{in_ i})^\prime \]](images/statug_genmod0507.png)
You use the following extension of defined earlier to check the functional form of the jth covariate:
![\[ W_ j(x)=\frac{1}{\sqrt {K}}\sum _{i=1}^ K\sum _{k=1}^{n_ i}I( x_{ikj} \le x)e_{ik} \]](images/statug_genmod0508.png)
where 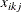 is the jth component of .
is the jth component of .
The null distribution of can be approximated by the conditional distribution of
![\[ \hat{W}_ j(x)= \frac{1}{\sqrt {K}}\sum _{i=1}^ K\left\{ \sum _{k=1}^{n_ i}I( x_{ikj} \le x)e_{ik} + \bm {\eta }^\prime (x,\hat{\bbeta }) \mb{I}_0^{-1} \hat{\mb{D}}^\prime _ i\hat{\mb{V}}_ i^{-1}\mb{e}_ i \right\} Z_ i \]](images/statug_genmod0510.png)
where 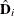 and
and 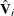 are defined as in the section Generalized Estimating Equations with the unknown parameters replaced by their estimated values,
are defined as in the section Generalized Estimating Equations with the unknown parameters replaced by their estimated values,
![\[ \bm {\eta }(x,\bbeta ) = -\sum _{i=1}^ K\sum _{k=1}^{n_ i} I(x_{ikj} \le x)\frac{\partial \mu _{ik}}{\partial \bbeta } \]](images/statug_genmod0513.png)
![\[ \mb{I}_0 = \sum _{i=1}^ K\hat{\mb{D}}^\prime _ i\hat{\mb{V}}^{-1}_ i\hat{\mb{D}}_ i \]](images/statug_genmod0514.png)
and 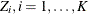 , are independent random variables. You replace with the linear predictor
, are independent random variables. You replace with the linear predictor 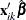 in the preceding formulas to check the link function.
in the preceding formulas to check the link function.