The SYSLIN Procedure
- Overview
-
Getting Started
 An Example ModelVariables in a System of EquationsUsing PROC SYSLINOLS EstimationTwo-Stage Least Squares EstimationLIML, K-Class, and MELO EstimationSUR, 3SLS, and FIML EstimationComputing Reduced Form EstimatesRestricting Parameter EstimatesTesting ParametersSaving Residuals and Predicted ValuesPlotting Residuals
An Example ModelVariables in a System of EquationsUsing PROC SYSLINOLS EstimationTwo-Stage Least Squares EstimationLIML, K-Class, and MELO EstimationSUR, 3SLS, and FIML EstimationComputing Reduced Form EstimatesRestricting Parameter EstimatesTesting ParametersSaving Residuals and Predicted ValuesPlotting Residuals -
Syntax
-
Details
-
Examples
- References
Computational Details
This section discusses various computational details.
Computation of Least Squares-Based Estimators
Let the system be composed of G equations and let the ith equation be expressed in this form:
![\[ y_ i = Y_ i \bbeta _ i + X_ i \bgamma _ i + \mb{u} \]](images/etsug_syslin0042.png)
where
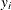
-
is the vector of observations on the dependent variable
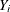
-
is the matrix of observations on the endogenous variables included in the equation
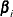
-
is the vector of parameters associated with
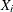
-
is the matrix of observations on the predetermined variables included in the equation
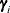
-
is the vector of parameters associated with

-
is a vector of errors
Let 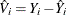 , where
, where 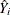 is the projection of onto the space spanned by the instruments matrix Z.
is the projection of onto the space spanned by the instruments matrix Z.
Let
![\[ \bdelta _ i \: =\: \left[ \begin{array}{c} \bbeta _{i}\\ \bgamma _{i} \end{array} \right] \]](images/etsug_syslin0047.png)
be the vector of parameters associated with both the endogenous and exogenous variables.
The K-class of estimators (Theil 1971) is defined by
![\[ \hat{ \bdelta }_{i,k} \: = \: \left[ \begin{array}{cc} Y_ i^\prime Y_ i - k \hat{V}_ i^\prime \hat{V}_ i & Y_ i^\prime X_ i \\ X_ i^\prime Y_ i & X_ i^\prime X_ i \end{array} \right]^{-1} \left[ \begin{array}{c} (Y_ i - kV_ i)^\prime y_ i \\ X_ i^\prime y_ i \end{array} \right] \]](images/etsug_syslin0048.png)
where k is a user-defined value.
Let
![\[ \bR \: = \: [ Y_ i X_ i ] \]](images/etsug_syslin0049.png)
and
![\[ \hat{\bR } \: = \: [ \hat{Y}_ i\ X_ i ] \]](images/etsug_syslin0050.png)
The 2SLS estimator is defined as
![\[ \hat{\bdelta }_{i, 2SLS} = [ \hat{R}_ i^\prime \: \hat{R}_ i ]^{-1} \hat{R}_ i^\prime y_ i \]](images/etsug_syslin0051.png)
Let 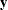 and
and 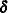 be the vectors obtained by stacking the vectors of dependent variables and parameters for all G equations, and let
be the vectors obtained by stacking the vectors of dependent variables and parameters for all G equations, and let 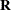 and
and 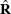 be the block diagonal matrices formed by
be the block diagonal matrices formed by 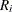 and
and 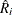 , respectively.
, respectively.
The SUR and ITSUR estimators are defined as
![\[ \hat{\bdelta }_{(IT)SUR} = \left[ \bR ^\prime \left(\hat{\Sigma }^{-1} \otimes \bI \right) \bR \right]^{-1} \bR ^\prime \left(\hat{\Sigma }^{-1} \otimes \bI \right)\mb{y} \]](images/etsug_syslin0058.png)
while the 3SLS and IT3SLS estimators are defined as
![\[ \hat{\bdelta }_{(IT)3SLS} = \left[ \hat{\bR }^\prime \left(\hat{\Sigma }^{-1} \otimes \bI \right) \hat{\bR } \right]^{-1} \hat{\bR }^\prime \left(\hat{\Sigma }^{-1} \otimes \bI \right)\mb{y} \]](images/etsug_syslin0059.png)
where 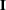 is the identity matrix, and
is the identity matrix, and 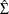 is an estimator of the cross-equation correlation matrix. For 3SLS, is obtained from the 2SLS estimation, while for SUR it is derived from the OLS estimation. For IT3SLS and ITSUR, it is obtained
iteratively from the previous estimation step, until convergence.
is an estimator of the cross-equation correlation matrix. For 3SLS, is obtained from the 2SLS estimation, while for SUR it is derived from the OLS estimation. For IT3SLS and ITSUR, it is obtained
iteratively from the previous estimation step, until convergence.
Computation of Standard Errors
The VARDEF= option in the PROC SYSLIN statement controls the denominator used in calculating the cross-equation covariance estimates and the parameter standard errors and covariances. The values of the VARDEF= option and the resulting denominator are as follows:
- N
-
uses the number of nonmissing observations.
- DF
-
uses the number of nonmissing observations less the degrees of freedom in the model.
- WEIGHT
-
uses the sum of the observation weights given by the WEIGHTS statement.
- WDF
-
uses the sum of the observation weights given by the WEIGHTS statement less the degrees of freedom in the model.
The VARDEF= option does not affect the model mean squared error, root mean squared error, or 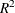 statistics. These statistics are always based on the error degrees of freedom, regardless of the VARDEF= option. The VARDEF=
option also does not affect the dependent variable coefficient of variation (CV).
statistics. These statistics are always based on the error degrees of freedom, regardless of the VARDEF= option. The VARDEF=
option also does not affect the dependent variable coefficient of variation (CV).
Reduced Form Estimates
The REDUCED option in the PROC SYSLIN statement computes estimates of the reduced form coefficients. The REDUCED option requires that the equation system be square. If there are fewer models than endogenous variables, IDENTITY statements can be used to complete the equation system.
The reduced form coefficients are computed as follows. Represent the equation system, with all endogenous variables moved to the left-hand side of the equations and identities, as
![\[ \mb{B Y} = \bGamma \mb{X} \]](images/etsug_syslin0062.png)
Here B is the estimated coefficient matrix for the endogenous variables Y, and  is the estimated coefficient matrix for the exogenous (or predetermined) variables X.
is the estimated coefficient matrix for the exogenous (or predetermined) variables X.
The system can be solved for Y as follows, provided B is square and nonsingular:
![\[ \mb{Y} = \mb{B} ^{-1} \bGamma \mb{X} \]](images/etsug_syslin0064.png)
The reduced form coefficients are the matrix 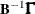 .
.
Uncorrelated Errors across Equations
The SDIAG option in the PROC SYSLIN statement computes estimates by assuming uncorrelated errors across equations. As a result, when the SDIAG option is used, the 3SLS estimates are identical to 2SLS estimates, and the SUR estimates are the same as the OLS estimates.
Overidentification Restrictions
The OVERID option in the MODEL statement can be used to test for overidentifying restrictions on parameters of each equation. The null hypothesis is that the predetermined variables that do not appear in any equation have zero coefficients. The alternative hypothesis is that at least one of the assumed zero coefficients is nonzero. The test is approximate and rejects the null hypothesis too frequently for small sample sizes.
The formula for the test is given as follows. Let 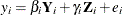 be the ith equation.
be the ith equation. 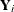 are the endogenous variables that appear as regressors in the ith equation, and
are the endogenous variables that appear as regressors in the ith equation, and 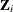 are the instrumental variables that appear as regressors in ith equation. Let
are the instrumental variables that appear as regressors in ith equation. Let 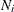 be the number of variables in and .
be the number of variables in and .
Let 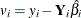 . Let Z represent all instrumental variables, T be the total number of observations, and K be the total number of instrumental variables. Define
. Let Z represent all instrumental variables, T be the total number of observations, and K be the total number of instrumental variables. Define 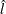 as follows:
as follows:
![\[ \hat{l} = \frac{{v’}_{i}(\mb{I} -\mb{Z}_{i}({\mb{Z} ’}_{i}\mb{Z} _{i})^{-1}{\mb{Z} ’}_{i})v_{i}}{{v’}_{i}(\mb{I} -\mb{Z} ({\mb{Z} ’}\mb{Z} )^{-1}{\mb{Z} ’})v_{i} } \]](images/etsug_syslin0072.png)
Then the test statistic
![\[ \frac{T-K}{K-N_{i}} ( \hat{l} - 1 ) \]](images/etsug_syslin0073.png)
is distributed approximately as an F with 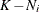 and
and 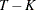 degrees of freedom. See Basmann (1960) for more information.
degrees of freedom. See Basmann (1960) for more information.
Fuller’s Modification to LIML
The ALPHA= option in the PROC SYSLIN and MODEL statements parameterizes Fuller’s modification to LIML. This modification is
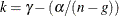 , where
, where  is the value of the ALPHA= option,
is the value of the ALPHA= option, 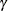 is the LIML k value,n is the number of observations, and g is the number of predetermined variables. Fuller’s modification is not used unless the ALPHA= option is specified. See Fuller
(1977) for more information.
is the LIML k value,n is the number of observations, and g is the number of predetermined variables. Fuller’s modification is not used unless the ALPHA= option is specified. See Fuller
(1977) for more information.