Usage Note 69654: Estimate and test functions of kappas from multiple 2x2 tables
 |  |  |
When subjects or objects are rated or assessed by multiple raters or instruments, it is often of interest to determine how well the raters or instruments agree. When the ratings are done on a categorical scale, the kappa statistic is commonly used for measuring the level of agreement in the two-way table formed by the ratings from two raters. The kappa statistic for the two-way table is easily computed using the AGREE option in the FREQ procedure. To assess the overall agreement among multiple raters, you can use the methods available in the MAGREE macro (SAS Note 25006).
One interest might be to test whether the agreement between two raters is different from the agreement between two other raters. That is, you might want to test the equality of two or more kappas. If the kappas can be assumed to be independent, this can also be done with the AGREE option in PROC FREQ when the data are arranged in a multiway table. If the kappas are not independent, or if interest is in estimating or testing some function of several kappas, then this can be addressed using the model-based approach below, facilitated by the Kappa macro.
The following addresses the general case of multiple raters, each providing a binary assessment of each subject or item. The data from each pair of raters produces a 2×2 table for which a kappa agreement statistic can be computed. These kappas can be compared in a pairwise fashion. Also, any function of the kappas can be estimated and tested.
Example
The data used in this example is from the example titled "GEE for Binary Data with Logit Link Function" in the GENMOD procedure documentation. The data contains the binary respiratory status of subjects assessed at baseline and at four separate visits. A link to the data and code is provided in the example. Suppose that it is of interest to assess the agreement that exists between baseline and each of the four visits, whether agreement differs between those pairs, and if so, whether agreement in the first two visits is the same as in the last two. If not, then estimate an average kappa and test if there is some trend in agreement over time. Kappa statistics are to be computed for each of the four 2×2 tables with baseline as a common variable and then pairwise comparisons among those four kappas are to be estimated along with estimates and tests as just described.
By arranging the data as a multiway table, PROC FREQ can be used to estimate the individual kappas and to obtain overall and pairwise comparisons. Note however that PROC FREQ assumes that the kappas are independent. For these tables involving one set of repeatedly measured subjects, and with baseline as a common variable in all tables, that assumption might not be reasonable. The first DATA step in the code provided with the example creates the data in wide format with one observation per subject and a baseline and four separate visit variables containing the subject's responses at each of those time points. This data set is referred to by the name WIDE. A subsequent DATA step rearranges the data into long format with four observations per subject, each containing the baseline response as well as a response from one visit in a new OUTCOME variable, and including a VISIT variable identifying which visit the response came from. This data set is referred to by the name LONG.
Pairwise and overall comparisons using PROC FREQ
The following statements use the LONG data set format to estimate the four kappa statistics assessing agreement between baseline and each of the four visits as well as a test of the equality of those kappas.
proc freq data=long;
table visit*baseline*outcome / agree;
ods select kappastatistics equalkappatest;
run;
The four kappa estimates are presented below. The test of equality, assuming independence of the kappas, suggests no difference in the kappas (p=0.5717). A common, overall estimate of kappa across these four tables is 0.4078 with 95% confidence limits (0.3257, 0.4900).
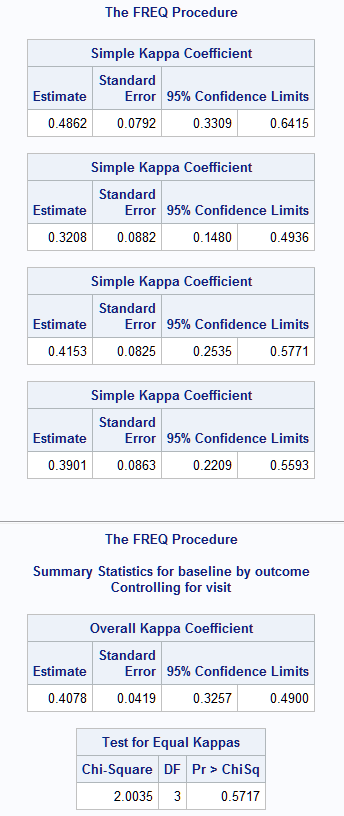 |
While there is no evidence of differences in the kappas, each pairwise comparison can be done by adding a WHERE statement in the above PROC FREQ step to select two of the visits. For example, adding the following statement provides the comparison of kappas from visits 1 and 2. That comparison reveals, as expected, no significant difference (p=0.1629). All six pairwise comparisons could be done in this way. If desired, the raw p-values could then be adjusted for multiple testing using PROC MULTTEST.
where visit in (1 2);
A model-based approach
The following model-based approach makes no assumptions about the independence of the tables. However, it requires fitting a generalized logit model to the multiway (2×2×...×2) table involving all of the responses. This requires having sufficient data. Even so, model-fitting problems can occur. So, before using this approach, it is strongly recommended that you use PROC FREQ, as above, to examine all of the tables of interest to find and eliminate any observations with missing values or tables that show problems such as constant variables or empty cells. The following analysis uses the WIDE data set.
The Kappa macro uses the NLMIXED procedure to fit an intercepts-only, generalized logit model to the multinomial variable that identifies the cells of the cross-classification of all five variables – baseline×visit1×visit2×visit3×visit4. That variable has 25 = 32 levels. From this model, the 32 cell probabilities are obtained and functions of these are then used to compute the cell probabilities of the four 2×2 tables of interest. The kappa statistics are then defined as functions of these cell probabilities. All tests are large sample tests.
Kappa macro usage and limitations
In the Kappa macro call, specify the data set in data= and the variables involved in the tables in var=. data= and var= are required. DATA step options such as DROP=, KEEP=, or WHERE= can follow the data set name in parentheses. All variables specified in var= must be numeric and all values must be 0 or 1 only. There should be no missing values. Variable lists such as x1-x4, abc--xyz, or _NUMERIC_ are allowed. When one variable is to be in every table, specify its number (in its order in the var= list) in ref=. If ref= is omitted, then kappa statistics are defined for all possible 2×2 tables. Note that the macro does not check any of these requirements and various errors or incorrect results can occur if violated.
The macro call must be followed by one or more ESTIMATE statements to estimate and test any kappas or function of kappas. Include a final RUN statement to allow PROC NLMIXED to run. Note that the syntax of the ESTIMATE statement is as described in the NLMIXED documentation and is not like the ESTIMATE statement syntax used in other procedures. Following the label in quotation marks, specify an expression that is a single linear or nonlinear functions of the kappas. The function is tested for equality to zero. To test equality to a different value, subtract it in the expression. It is not possible to conduct a joint test of several functions of the kappas. The individual kappas have names of the form KAPPA_ij, where i and j are the two variable numbers (in their order in the var= list) identifying one 2×2 table. Optionally, the following statement can be included to suppress all output other than the results of the ESTIMATE statements, but the full NLMIXED output might be needed to assess the fit of the underlying model when errors or anomalies occur.
ods select AdditionalEstimates;
Because the number of statements that the Kappa macro generates for use in PROC NLMIXED grows very quickly with the number of variables and number of tables, its use is recommended only for a small number of variables and tables. Having a common variable in every table, such as when there is a gold standard or true rating, can greatly reduce the number of tables, but the number of variables should still be limited. Also, because a multinomial model is fit to the cells of the full cross-classification of all the variables, the number of observations required increases quickly in order to avoid model fitting problems that can arise when the data is too sparse relative to the size of the full table.
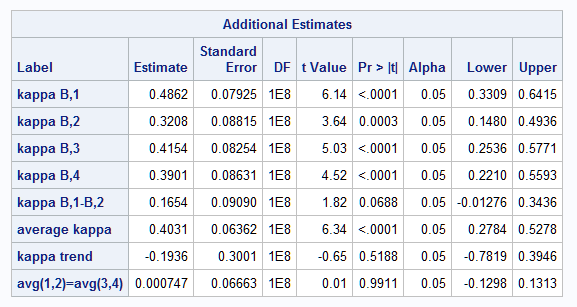
In the statements below, the baseline and four visit variables in the WIDE data set are used to form tables, and ref=1 indicates that the first variable, baseline, should be in every table resulting in four tables. Kappa statistics are defined for each of the four tables. The first four ESTIMATE statements request that each kappa be estimated and tested. The next ESTIMATE statement estimates the difference in the kappas from the visit1 and visit2 tables with baseline. The other pairwise differences could be done similarly. An average kappa is provided by the next ESTIMATE statement. Following that, the trend over the four visits is estimated (assuming equal spacing in time of the visits). The final ESTIMATE statement compares the average of the first two kappas to the average of the last two. This might be useful if there were some hypothesized difference between the earlier and later visits.
%kappa(data=wide, var=baseline visit1-visit4, ref=1)
estimate "kappa B,1" kappa_12;
estimate "kappa B,2" kappa_13;
estimate "kappa B,3" kappa_14;
estimate "kappa B,4" kappa_15;
estimate "kappa B,1-B,2" kappa_12-kappa_13;
estimate "average kappa" (kappa_12+kappa_13+kappa_14+kappa_15)/4;
estimate "kappa trend" -3*kappa_12 - kappa_13 + kappa_14 + 3*kappa_15;
estimate "avg(1,2)=avg(3,4)" (kappa_12+kappa_13)/2 - (kappa_14+kappa_15)/2;
run;
The results from the PROC NLMIXED and the Kappa macro reproduce the individual kappas provided by PROC FREQ above. The visit1-visit2 difference is estimated to be 0.1654 and is not significantly different from zero (p=0.0688). Also provided are estimates and tests of the three additionally specified functions of the kappas. The average kappa is estimated to be 0.40, similar to the estimate from PROC FREQ above, and is significantly different from zero (p<0.0001). However, there is no significant trend (p=0.5188) and the averages of the first and last two kappas do not differ significantly (p=0.9911).
 |
Operating System and Release Information
| Product Family | Product | System | SAS Release | |
| Reported | Fixed* | |||
| SAS System | N/A | Aster Data nCluster on Linux x64 | ||
| DB2 Universal Database on AIX | ||||
| DB2 Universal Database on Linux x64 | ||||
| Netezza TwinFin 32-bit SMP Hosts | ||||
| Netezza TwinFin 32bit blade | ||||
| Netezza TwinFin 64-bit S-Blades | ||||
| Netezza TwinFin 64-bit SMP Hosts | ||||
| Teradata on Linux | ||||
| Cloud Foundry | ||||
| 64-bit Enabled AIX | ||||
| 64-bit Enabled HP-UX | ||||
| 64-bit Enabled Solaris | ||||
| ABI+ for Intel Architecture | ||||
| AIX | ||||
| HP-UX | ||||
| HP-UX IPF | ||||
| IRIX | ||||
| Linux | ||||
| Linux for AArch64 | ||||
| Linux for x64 | ||||
| Linux on Itanium | ||||
| OpenVMS Alpha | ||||
| OpenVMS on HP Integrity | ||||
| Solaris | ||||
| Solaris for x64 | ||||
| Tru64 UNIX | ||||
| z/OS | ||||
| z/OS 64-bit | ||||
| IBM AS/400 | ||||
| OpenVMS VAX | ||||
| N/A | ||||
| Android Operating System | ||||
| Apple Mobile Operating System | ||||
| Chrome Web Browser | ||||
| Macintosh | ||||
| Macintosh on x64 | ||||
| Microsoft Windows 10 | ||||
| Microsoft Windows 7 | ||||
| Microsoft Windows 8 Enterprise 32-bit | ||||
| Microsoft Windows 8 Enterprise x64 | ||||
| Microsoft Windows 8 Pro 32-bit | ||||
| Microsoft Windows 8 Pro x64 | ||||
| Microsoft Windows 8 x64 | ||||
| Microsoft Windows Server 2008 R2 | ||||
| Microsoft Windows Server 2012 R2 Datacenter | ||||
| Microsoft Windows Server 2012 R2 Std | ||||
| Microsoft® Windows® for 64-Bit Itanium-based Systems | ||||
| Microsoft Windows Server 2003 Datacenter 64-bit Edition | ||||
| Microsoft Windows Server 2003 Enterprise 64-bit Edition | ||||
| Microsoft Windows XP 64-bit Edition | ||||
| Microsoft® Windows® for x64 | ||||
| OS/2 | ||||
| SAS Cloud | ||||
| Microsoft Windows 8.1 Enterprise 32-bit | ||||
| Microsoft Windows 8.1 Enterprise x64 | ||||
| Microsoft Windows 8.1 Pro 32-bit | ||||
| Microsoft Windows 8.1 Pro x64 | ||||
| Microsoft Windows 11 | ||||
| Microsoft Windows 95/98 | ||||
| Microsoft Windows 2000 Advanced Server | ||||
| Microsoft Windows 2000 Datacenter Server | ||||
| Microsoft Windows 2000 Server | ||||
| Microsoft Windows 2000 Professional | ||||
| Microsoft Windows NT Workstation | ||||
| Microsoft Windows Server 2003 Datacenter Edition | ||||
| Microsoft Windows Server 2003 Enterprise Edition | ||||
| Microsoft Windows Server 2003 Standard Edition | ||||
| Microsoft Windows Server 2003 for x64 | ||||
| Microsoft Windows Server 2008 | ||||
| Microsoft Windows Server 2008 for x64 | ||||
| Microsoft Windows Server 2012 Datacenter | ||||
| Microsoft Windows Server 2012 Std | ||||
| Microsoft Windows Server 2016 | ||||
| Microsoft Windows Server 2019 | ||||
| Microsoft Windows Server 2022 | ||||
| Microsoft Windows XP Professional | ||||
| Windows 7 Enterprise 32 bit | ||||
| Windows 7 Enterprise x64 | ||||
| Windows 7 Home Premium 32 bit | ||||
| Windows 7 Home Premium x64 | ||||
| Windows 7 Professional 32 bit | ||||
| Windows 7 Professional x64 | ||||
| Windows 7 Ultimate 32 bit | ||||
| Windows 7 Ultimate x64 | ||||
| Windows Millennium Edition (Me) | ||||
| Windows Vista | ||||
| Windows Vista for x64 | ||||
| Type: | Usage Note |
| Priority: | |
| Topic: | Analytics ==> Categorical Data Analysis SAS Reference ==> Macro SAS Reference ==> Procedures ==> FREQ SAS Reference ==> Procedures ==> NLMIXED |
| Date Modified: | 2022-12-08 05:45:33 |
| Date Created: | 2022-10-31 10:36:12 |